
IAGen comme Simulateur « universel », nouvelles architectures et meilleure compréhension
TL;DR ?
4 mots clés
UniSim, Kolmogorov-Arnold, modèles de diffusion, GAHB
Pourquoi lire cette publi peut vous être utile concrètement ?
Soyons honnêtes et avertissons le lecteur : les deux tiers de cet article sont plus techniques que d’habitude. Ceci dit, nous discutons dans cet article d’une nouvelle architecture fondamentale qui pourrait demain révolutionner de nombreuses approches Deep Learning, comme nous allons vers une meilleure compréhension des IAs génératives et, particulièrement, des modèles de diffusion qui sont depuis quelques années les moteurs de ces IAs. Enfin, le simulateur universel annonce un nouveau type d’outil permettant de travailler en robotique ou d’une manière générale en représentation de gestes par l’image qui, s’il présente quelques écueils, révolutionnera le travail quotidien dans ces domaines.
Quels process métier seront probablement modifiés sur la base de ces recherches ?
UniSim peut révolutionner la robotique et l’apprentissage d’interactions avec des objets, tel que le travail avec des gestes humains capturés en vidéo.
Les Kolmogorov-Arnold networks sont déjà un candidat intéressant pour approximer par des fonctions complexes des phénomènes simples.
Enfin, une meilleure compréhension des modèles de diffusion aura un impact fort sur tous les outils de génération d’images par IA, au-delà des rituels vaudous supposés donner des prompts efficaces.
Si vous n’avez qu’une minute à consacrer à la lecture maintenant :
- Deepmind et Berkeley se sont alliés pour créer un simulateur « universel », capable de prendre en entrée une image et des consignes d’action pour générer, en sortie, une vidéo simulant le résultat. Ce travail a notamment demandé d’accumuler et d’agréger de nombreux datasets différents et complémentaires. Les auteurs peuvent contrôler ce simulateur et ont pu entraîner un agent robotique uniquement en simulation pour ensuite l’utiliser dans le monde réel.
- And now something completely different : une nouvelle architecture fondamentale est apparue et fait beaucoup de bruit dans le monde de la recherche, nommée les Kolmogorov-Arnold Networks. Ces modèles sont encore réduits à des cas simples, mais semblent très efficaces. Ils prétendent demain pouvoir détrôner les MLPs qui sont aujourd’hui partout en Deep Learning.
- Enfin, une nouvelle étude lève un voile passionnant sur les modèles de diffusion qui sont devenus l’architecture incontournable pour les IAs génératives en image. Entre autres découvertes : ces modèles deviennent vite assez indépendants du dataset d’entraînement, et leur architecture est naturellement adéquate à la génération d’images.
Un Simulateur « universel » d’actions ?
Publication saluée comme « outstanding » lors du dernier ICLR 2024, l’article Learning Interactive Real-World Simulators de Yang et al rassemble du très beau monde de Deepmind et Berkeley pour proposer un travail assez impressionnant.
La question posée ici est de pousser les modèles dits d’IA générative (ces modèles de diffusion qui depuis trois ans se sont cordialement imposés dans le paysage, entre autres via le célèbre Stable Diffusion) au-delà de la simple génération d’images ou de vidéos. L’idée est d’utiliser ces modèles pour (attention, phrase un peu trop prétentieuse) simuler la réalité en les conditionnant sur des actions. Autrement dit, là où aujourd’hui on peut générer une vidéo « artistique » via un prompt, est-il possible de générer une vidéo basée sur une image initiale (représentant une situation) et sur une série d’actions imaginaires. Une illustration sera à ce stade efficace pour se représenter le challenge :

Ci-dessus, pour chaque colonne, la première image constitue un état initial issu de notre bonne vieille réalité, avec un « prompt » au-dessus. Les trois images en dessous montrent ce que le modèle a généré, soit une vidéo représentant ces actions réalisées visuellement.
Le projet est donc très ambitieux : disposer d’un modèle capable de prédire l’évolution d’un système réel et de générer les images correspondant à ces prédictions. Et comme d’habitude en Deep Learning, le plus important reste la donnée représentant le problème. Ce n’est donc pas un hasard si cette publication s’ouvre sur la génération d’un dataset gigantesque, lui-même issu de nombreux autres datasets différents. Ces datasets originels viennent majoritairement du monde de la recherche et représentent des problèmes assez semblables : exécutions dans des environnements synthétiques, donnée robotique réelle, activité humaine réelle, et même donnée image/texte issue d’Internet.

Rassembler des données aussi différentes n’est évidemment pas une gageure, ne serait-ce que pour définir une modélisation commune finale. Ici, la vidéo est conservée comme une série d’images, et les textes de description sont transformés en embeddings via un modèle classique T5, auxquels sont concaténés les actions robotiques si elles sont présentes. Cet espace sera l’espace d’actions du modèle, les inputs à partir desquels il génèrera la prédiction. Trois précisions intéressantes :
- Pour les panorama scans ci-dessus, l’enjeu est de simuler le déplacement d’un agent et donc l’évolution de sa caméra quand il se déplace. Les auteurs partent du panorama statique, puis génèrent des mouvements en déplaçant un aperçu limité de ce panorama.
- Pour la donnée synthétique (un de nos chevaux de bataille chez Datalchemy), les auteurs insistent sur son importance, notamment pour générer les cas rares qui se rencontreront peu dans la donnée réelle. Cette approche est aujourd’hui un classique du Deep Learning.
- Pour les images tirées d’Internet, elles sont considérées comme des vidéos ayant une unique frame. L’annotation de l’image est utilisée comme action (par exemple, a person walking in the street)
À ce stade, habemum dataset, nous pouvons parler du modèle. Ce dernier prendra en entrée une première image (l’état initial) et la description de l’action, afin de générer les observations futures dépendant de cette action. Celle-ci peut être un déplacement de la caméra codifié, des actions d’un bras robot ou, plus simplement, du langage naturel. Le modèle (schéma ci-dessous) est sans surprise un modèle de diffusion qui apprend à générer via une opération de débruitage (nous en reparlons juste après), et s’appelle d’une manière auto-régressive, une image après l’autre.
Avant de se projeter dans l’utilisation d’un tel modèle, un reality-check est indispensable : les auteurs ont entraîné leur modèle sur 512 TPU v3 pendant 20 jours. Autrement dit, via une rapide approximation, un petit budget de 500.000€ est nécessaire (pour un seul training) pour reproduire ce résultat…
Ce constat passé, regardons un peu les résultats de ce modèle ci-dessous :

- En haut à gauche : le modèle peut simuler le résultat visuel d’actions assez complexes d’interactions humaines, comme se laver ou sécher ses mains. Notons que l’on peut désigner une cible d’action (ici, la carotte) librement via le langage naturel, constituant une des forces des Large Language Models et autres modèles de cross embeddings
- En haut à droite : interactions avec des boutons et avec un système électrique
- En bas, gauche et droite : « navigation » dans le simulateur en se déplaçant à partir d’une scène initiale.
Retenez ces exemples, ils nous serviront de base pour critiquer ce travail dans la suite de cet article.
L’application fondamentale présentement est d’utiliser ce « simulateur universel » pour entraîner des agents robotiques sans besoin d’interactions avec la réalité (souvent impossibles en entraînement), ou d’un simulateur spécialisé. Cette application est fascinante puisqu’elle rejoint le domaine du Deep Reinforcement Learning qui n’est pas sans écueil, notamment sur la problématique de transférer un agent d’un environnement simulé à un environnement réel. Les difficultés viennent souvent des limites visuelles de l’environnement simulé, comme celles liées à la modélisation des interactions complexes de manière satisfaisante. Ici, les auteurs présentent un agent entraîné uniquement face à UniSim, avec un algorithme plus que classique (Reinforce) et d’observer sa généralisation aux cas réels, comme le montre le schéma ci-dessous :
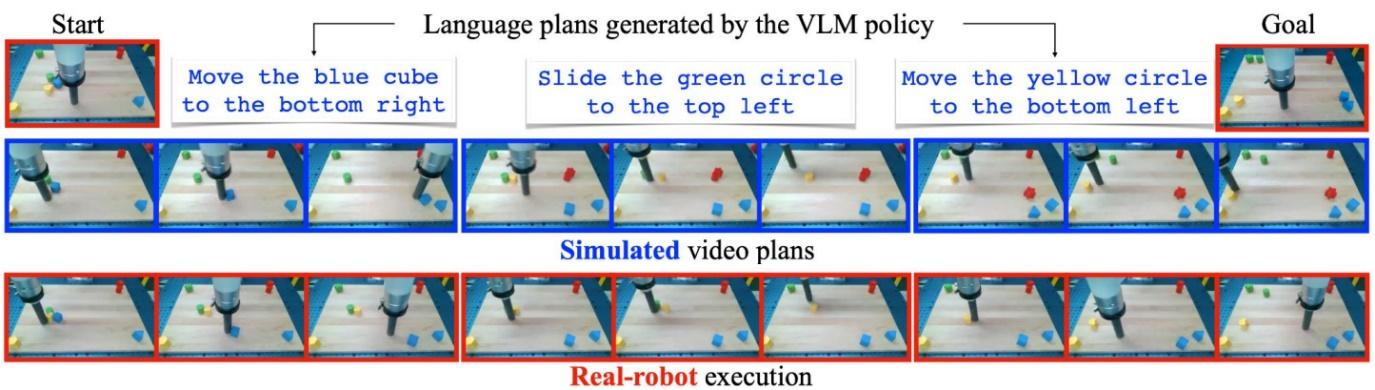
Mais alors, révolution ? Peut-être oui, peut-être non 😊 Notre mission principale chez Datalchemy est de suivre la recherche et de filtrer celle-ci sans pitié pour permettre à nos clients d’utiliser des approches récentes et efficaces. Et si nous avons beaucoup travaillé en robotique et en Deep Reinforcement Learning (voir notre précédent article consacré à l’Imitation Learning), nous n’imaginons pas trop, à date, utiliser un tel outil s’il était disponible. Explications :
Ici, parler de simulateur est en réalité un peu exagéré. Un simulateur, théoriquement, reproduit un certain nombre de règles physiques (gravité, contacts entre les objets, etc.) pour déterminer les conséquences d’une action. Unisim, lui, apprend sur un gigantesque dataset à prédire des images futures à partir d’un historique d’images et une description d’actions. Peut-être a-t-il dans son espace interne modélisé des règles physiques qu’il aurait appris lors de son entraînement, mais même si c’est le cas, ces règles physiques ne seront pas simples à extraire voire impossible (voir notre revue précédente sur l’interprétabilité du Deep Learning). De plus, un modèle Deep Learning pourra toujours, à tout moment, se tromper sur une prédiction (phénomène d’hallucinations), et ce sans prévenir. Ici, détecter une telle erreur sera particulièrement complexe, voire impossible. Notons d’ailleurs que pour certains problèmes qui étaient sous-représentés dans la donnée, les auteurs ont observé qu’il était nécessaire de préfixer le prompt pour désigner le dataset contenant ces problèmes pour que cela fonctionne :

La vraie question est évidemment celle de la généralisation. L’expérience des auteurs sur l’entraînement d’un agent sur Unisim pour ensuite l’appliquer à un cas réel est d’ailleurs très limitée (déplacer des formes géométriques très simples) par rapport aux prédictions complexes présentées dans la publication… Les auteurs sont d’ailleurs très honnêtes sur ces limites dans leur travail. Ils notent entre autres qu’il est parfaitement possible de donner un ordre absurde et d’observer un résultat (demander à un bras robot de se laver les mains). Entre autres limites : un modèle très gros est trop consommateur en mémoire et consécutivement a du mal à prendre en entrée suffisamment d’images pour modéliser un problème complexe. Le fait qu’il ne manipule que des images le rend « aveugle » à d’autres paramètres d’actions, comme par exemple la force exercée sur un bras robot.
Ceci dit, cela reste un travail intéressant, poursuivant les approches de contrôle robotique par le langage naturel que Google a régulièrement proposé (les célèbres RT-1 et RT-2). Sujet à suivre donc !
Kolmogorov-Arnold Networks
Attention. Le contenu de ce paragraphe risque d’être un peu plus technique que d’habitude…
Les KANs, ou Kolmogorov-Arnold Networks, sont une nouvelle architecture fondamentale Deep Learning qui provoque quelques secousses dans le monde de la recherche depuis la sortie du papier éponyme de Liu et al. Attention : Nous ne parlons pas ici d’une nouvelle approche pour créer des Large Language Models, ou pour contrôler un agent robotique, mais d’une architecture beaucoup plus fondamentale qui a pour vocation à remplacer les MLP (multi layer perceptrons). Ces derniers sont l’architecture ancestrale du Deep Learning, irremplaçable, et on les retrouve disséminés dans toutes les architectures existantes jusqu’aux Large Language Models, en complément des couches de Transformer. Cette architecture est d’ailleurs régulièrement remise à l’honneur, comme par exemple pour travailler des nuages de points en 3 dimensions ou pour travailler directement sur des images avec le célèbre MLPMixer. S’attaquer à cette architecture n’est pas innocent et peut s’avérer être particulièrement intéressant.
Plongeons un petit peu dans les détails techniques. Le principe est ici de repartir d’un concept mathématique assez fondamental, celui de l’approximation universelle. L’idée est que, quelle que soit la fonction que nous désirons approximer, nous pourrons le faire avec une erreur aussi basse que nous le désirons via un MLP suffisamment complexe. Cette notion d’approximation universelle est fondamentale dans le monde du Deep Learning. Les auteurs proposent ainsi de s’inspirer d’un autre théorème mathématique d’approximation, la représentation de Kolmogorov-Arnold, afin de proposer une nouvelle architecture radicalement différente donnant des résultats fascinants.
Notons que d’autres chercheurs s’étaient attaqués au sujet, mais avaient bloqué sur le fait qu’appliquer directement ce théorème revient à produire un réseau de neurones à deux couches, naturellement limité dans sa capacité d’expression. Les auteurs ont donc travaillé à étendre la définition initiale pour créer des réseaux de taille variable, avec une approche de complexité dynamique permettant au modèle de s’adapter au cours de son entraînement. Mais, nous allons un peu trop vite, qu’est-ce qu’un KAN, et comment diffère-t-il d’un MLP ? Le schéma ci-dessous récapitule les points importants :
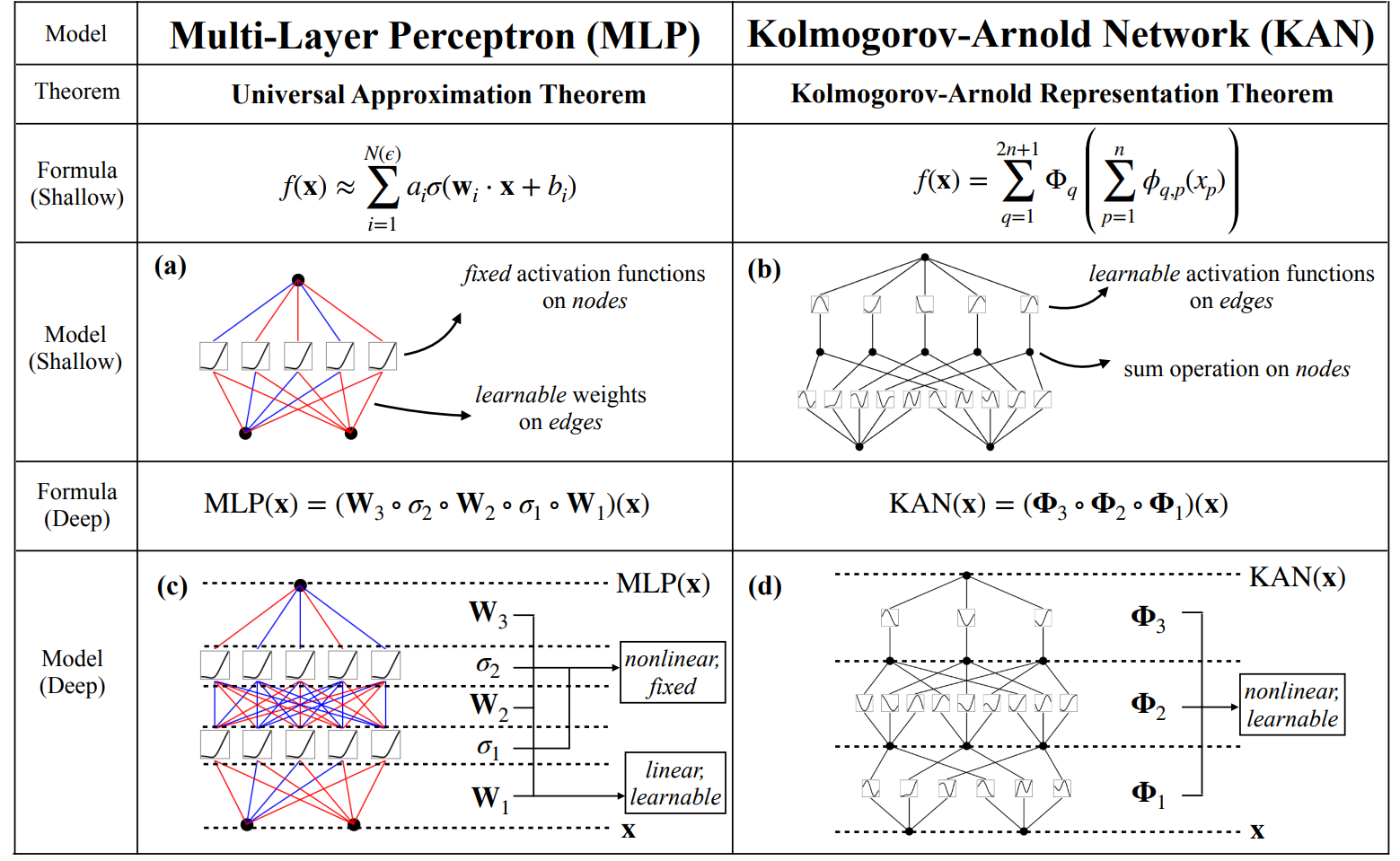
À gauche, nous retrouvons le bon vieux MLP. Les fonctions d’activation sont fixées (en général, le classique ReLU) et chaque nœud dispose de ces paramètres soumis à apprentissage (les weights). Chaque nœud exprime une combinaison linéaire des valeurs reçues en entrée.
Le KAN représenté à droite est radicalement différent. Les nœuds ne font qu’additionner les valeurs reçues, sans paramètre soumis à apprentissage. Les liens entre les nœuds, en revanche, vont modéliser des combinaisons de fonctions mathématiques élémentaires (des splines), et cette combinaison va être soumise à apprentissage. En effet, le théorème de Kolmogorov-Arnold stipule que toute fonction continue multivariée sur N variables pourra être exprimée comme la composition finie de fonction continue d’une variable unique. Autrement dit, la seule combinaison de plusieurs variables sera la somme, et l’information importante sera apprise sur chaque variable séparément pour modéliser la fonction cible.
À noter que dans l’approche présentée, les auteurs proposent un moyen de simplifier un KAN après son apprentissage afin d’obtenir un réseau le plus simple possible qui adresse le problème à résoudre. Les modélisations obtenues sont particulièrement efficaces, exemple ci-dessous où l’on veut apprendre à modéliser une fonction mathématique spécifique. Le pruning enlève les parties du réseau inutiles, suite à quoi on observe que le réseau a bien appris à modéliser chaque partie de la fonction mathématique jusqu’à retrouver la formule que nous voulions apprendre.
Nous ne plongerons pas plus loin dans les détails et reprenons de la hauteur afin de questionner l’intérêt de ce travail scientifique. Les plus belles modélisations mathématiques ne viendront pas s’imposer dans notre domaine sans résultats expérimentaux spécifiques. Et si ces résultats sont effectivement intéressants, ils restent un peu limités pour que nous puissions nous projeter facilement.
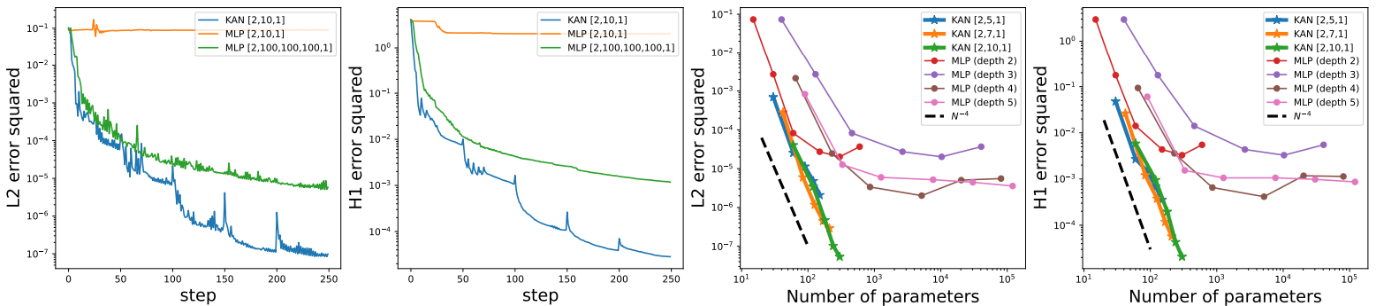
Premier résultat, sur une donnée synthétique assez basique, les auteurs observent que les KANs convergent beaucoup plus vite que les MLPs avec une complexité moindre. Ci-dessous, nous avons à chaque fois en haut la fonction mathématique cible que nous voulons reconstituer, et des courbes donnant l’erreur en fonction de la complexité (le nombre de paramètres) du réseau.
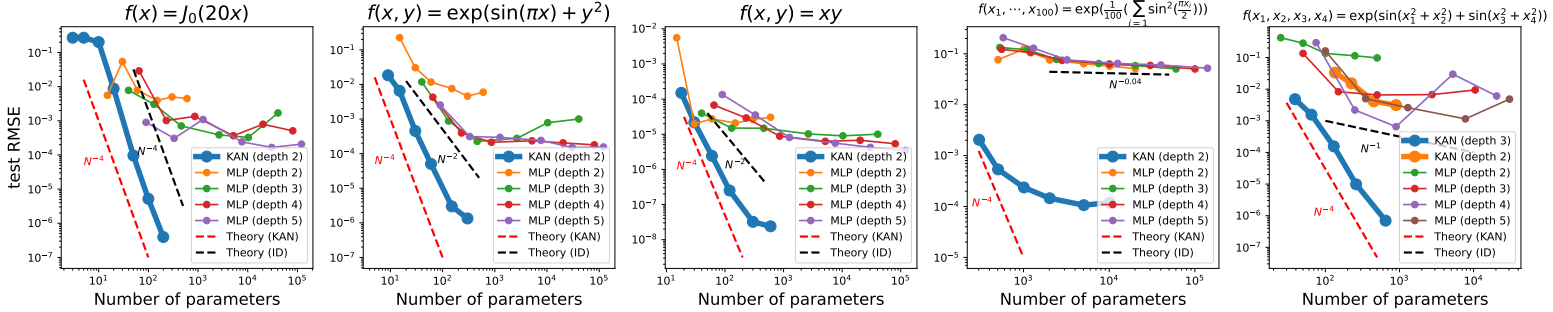
Second résultat (nous en sautons quelques uns) concernant la résolution d’équations différentielles partielles. La résolution de ce type d’équations intervient souvent en physique pour modéliser des systèmes un peu complexes, par exemple de résistance des matériaux ou de dynamique des fluides. Ici sur un problème très simple, le KAN semble dépasser largement en termes de résultats et d’efficacité leurs cousins MLPs.
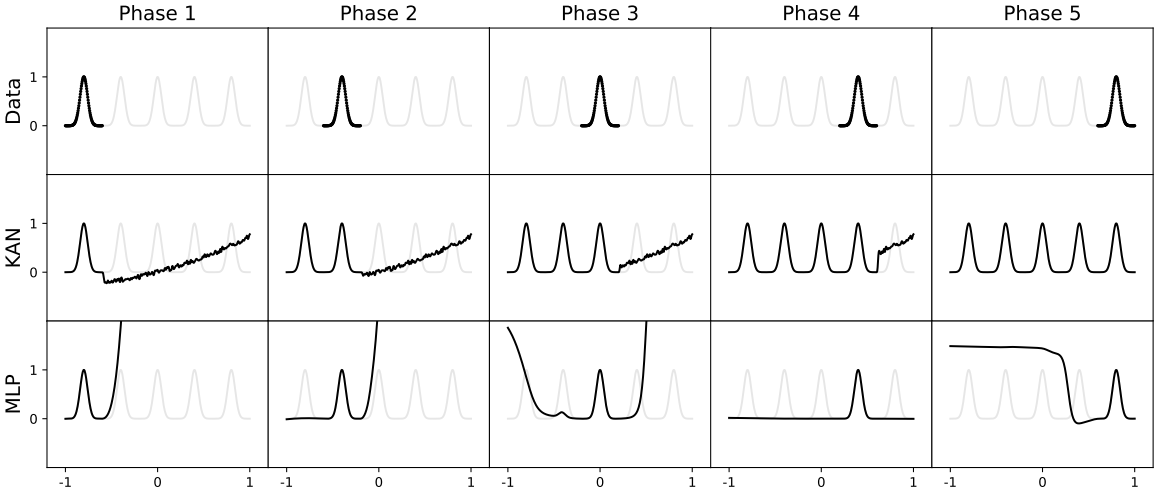
Dernier point intéressant, un scénario reproduisant une approche d’apprentissage continu. Ci-dessous, le modèle va recevoir la donnée séquentiellement (avec les points de gauche à droite). On observe que le MLP va vite oublier les données reçues précédemment, là où le KAN va continuer d’apprendre sans détruire l’information précédente :
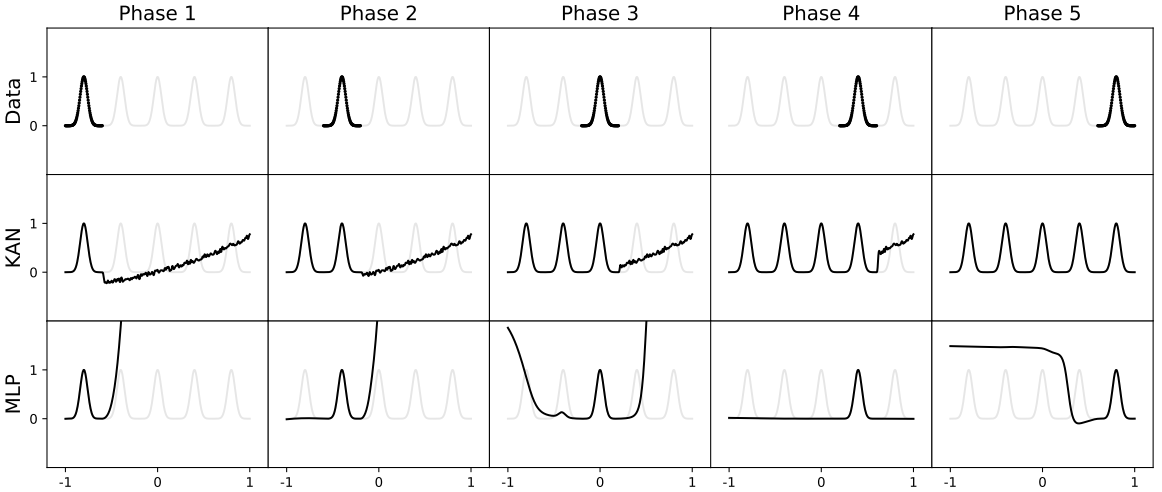
D’autres résultats sont présentés, mais ils ont tous en commun de prendre des problèmes très simples, sur lesquels les auteurs observent une supériorité de leur architecture sur le MLP.
Mais alors, faut-il réagir de suite et utiliser ces modèles ? Evidemment, non. Il est urgent d’attendre et d’observer avec attention les évolutions académiques dans les prochains mois. De nombreux chercheurs ont commencé à tester cette architecture sur des problèmes plus appliqués. C’est cette reproduction de la recherche qui permettra de décider si cette architecture est pertinente ou non. À minima, notons l’efficacité de cette approche, et une certaine forme de flexibilité mathématique séduisant l’amateur éclairé qui saura se méfier de ses propres biais et donc attendre de plus amples résultats.
Mieux comprendre les modèles de diffusion et leurs priors
Autre travail qui nous a beaucoup intéressé ce mois-ci, également mise à l’honneur comme outstanding au dernier ICLR, Generalization in diffusion models arises from geometry-adaptive harmonic representations de Kadkhodaie et al lève un voile intéressant sur le fonctionnement des modèles de diffusion.
Nous en parlions en début de cette revue mais reposons les choses : les modèles de diffusion constitue une architecture mise à l’honneur depuis 2021 qui s’est imposée dans le domaine de l’IA générative, en remplaçant d’une manière assez violente leurs prédécesseurs, les Generative Adversarial Networks grâce à une efficacité décuplée. Cette approche va apprendre à débruiter des images itérativement, et ainsi à créer un système de génération prenant en entrée une « image de bruit » et, par des appels successifs, générant en sortie une image finale de qualité. La diffusion s’est imposée en génération d’images, de nuages de points 3D ou de vidéo, ou encore dans d’autres domaines tels que le Deep Reinforcement Learning (via le Diffusion Policy dont nous avions parlé dans une revue précédente) ou la génération audio.
Une question qui agite depuis quelques années la communauté scientifique est de comprendre pourquoi cette approche de débruitage est aussi efficace face à d’autres approches plus intuitives. C’est à cette question que les auteurs ont voulu répondre. Même si leurs travaux laissent plus de questions que de réponses, ils posent toutefois les bases d’une meilleure compréhension qui va nourrir les travaux futurs dans le domaine d’une manière passionnante. Les auteurs étudient aussi un autre phénomène qui est l’apprentissage « par cœur » du dataset d’entraînement, notamment quand ce dernier est de petite taille…
La première expérience des auteurs est fascinante. Ils entraînent un modèle de diffusion à générer des images avec des datasets d’entraînement de tailles différentes : 10 images, 100, 1000, 10.000 et 100.000 images. Plus exactement, ils entraînent pour chaque taille de dataset deux modèles différents et comparent leurs résultats, visibles ci-dessous :
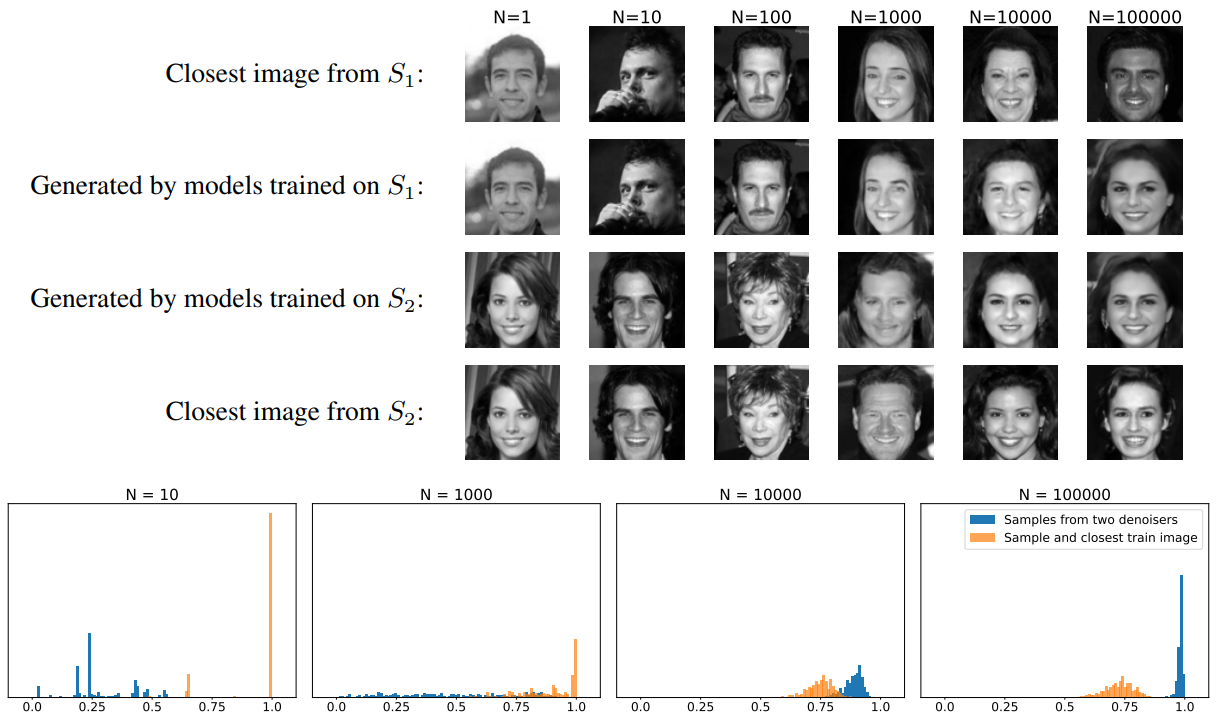
Ci-dessus, nous avons ainsi :
En haut : 2 modèles (S1 et S2) ont été entraînés sur 1,10,…,100.000 images. À chaque fois, les modèles avaient des datasets d’entraînement totalement différents (aucun élément partagé entre les datasets). On observe que pour de petites volumétries d’images (1,10,100), les images générées par le modèle sont exactement des images des datasets, comme en témoignent les images les plus proches de dataset (Closest image from…) récupérées à chaque fois. En revanche, et c’est là le plus fascinant, considérant que c’est le même bruit en entrée de chaque modèle, on observe vers 100.000 images que l’image générée par S1 est extrêmement proche de celle générée par S2 ! Considérant qu’ils n’ont aucune image partagée dans leurs datasets, cette proximité est donc parfaitement étonnante ! On observe que les images les plus proches issues des datasets sont différentes des images générées – nous sommes bien en généralisation.
En bas : nous voyons la similarité entre des paires d’images générées par les deux modèles pour différentes volumétries de datasets d’entraînement. On observe que pour un dataset de 100.000 images, deux images générées par les deux modèles sont beaucoup plus proches que les images issues du dataset.
La conclusion est donc que les modèles apprennent à avoir un comportement très proche là où leurs datasets d’entraînement sont disjoints. Ce point est très surprenant, d’autant qu’en Deep Learning, on prend vite l’habitude de relier tout phénomène au dataset d’entraînement. L’explication proposée par les auteurs est que les modèles de diffusion sont structurellement en capacité de généraliser facilement à la génération d’images. On parle ici de prior structurel. Les auteurs observent que l’on peut exprimer le traitement du modèle de génération via une base mathématique assez intéressante, base nommée ici geometry-adaptive harmonic bases (GAHB). Le schéma ci-dessous montre comment une image, bruitée plus débruitée par le modèle de diffusion, peut être exprimée en fonction de cette base interne au modèle :
En haut à gauche : l’image initiale, sa version bruitée et la version débruitée issue du modèle de diffusion.
En bas à gauche : on observe en abscisse l’index de chaque élément de la base, et en ordonnée l’importance donnée à chaque élément. On constate qu’un tout petit nombre d’éléments à des valeurs non nulles, autrement dit, que le modèle observe une réduction de complexité de l’image à débruiter en exprimant cette image sur un faible nombre d’éléments de la base.
A droite : l’information portée par différents éléments de la base. Nous constatons visuellement que l’information va épouser fortement les contours de l’image à débruiter, avec des oscillations entre valeurs positives (rouges) et valeurs négatives (bleues). Cette observation est le point de départ d’analyses un peu plus hypothétiques. L’idée est qu’un modèle de diffusion va naturellement exprimer l’information selon des oscillations sur cette base de décomposition GAHB. Un test sur des images beaucoup plus simples exhibe également ces oscillations, et soutient l’idée que cette décomposition est un fonctionnement « naturel » des modèles de diffusion facilitant ainsi leur gestion de l’image :
Les deux conclusions sont particulièrement captivantes. J’avouerais toutefois une préférence pour la première observation, soit le fait que deux modèles entraînés sur deux datasets disjoints issus d’un même dataset arrivent quelque part au même résultat. Ceci soutient fortement l’idée que les modèles de diffusion apportent à la donnée une information structurelle forte pour faciliter l’apprentissage d’images. Au-delà, l’observation de la décomposition est intéressante, mais nous laisse hélas sur notre faim. Que signifient exactement ces GAHB ? Comment utiliser cette décomposition ? Encore une fois, il est important d’attendre les prochains travaux pour voir comment évolue ce courant de recherche 😊