
L’art de dompter son LLM
Télécharger la version magazine en cliquant ici
Nouvelles limites, nouvelles approches pour une meilleure compréhension des LLM
TL;DR ?
6 mots-clés
LLM, sécurité, robustesse, limites, hallucinations, architectures
Pourquoi lire cette publi peut vous être utile concrètement ?
Les LLM s’imposent partout, avec des promesses incroyables de nouveaux outils performants et, tenez-vous bien, « intelligents ». La recherche avance plus lentement que ces promesses, et nous donne régulièrement une vision plus claire et plus précise des choses. Ici, nous exposons des limites fondamentales de ces modèles, creusons les risques potentiels en sécurité, et nous intéressons enfin aux approches pouvant donner des résultats acceptables. Quel que soit l’outil que l’on veut manier, connaître ses limites permettra toujours de mieux travailler.
Quels process métier seront probablement modifiés sur la base de ces recherches ?
L’utilisation de LLM pour générer des réponses à partir d’informations extraites va devoir continuer d’évoluer pour être plus robuste aux hallucinations ou informations manquantes. De même, la sécurisation totale de ces modèles s’impose aujourd’hui comme une évidence.
Les cas d’usage que nous avons développé pour des clients qui touchent au sujet de cet écho de la recherche ?
Nous déployons régulièrement ces outils que nous implémentons en solutions concrètes : recherche dans une base documentaire, qualification de la toxicité d’un message, assistance à une activité professionnelle.
Si vous n’avez qu’une minute à consacrer à la lecture maintenant :
- Fun fact : les LLMs ne savent fondamentalement pas opérer une différence claire entre l’instruction et la donnée à traiter quand on leur demande de générer une réponse. L’injection de prompt a de beaux jours devant elle.
- Cette question est une nouveauté ! Au point que nous avons enfin un premier dataset pour mesurer l’impact de ces problèmes sur un nouveau modèle.
- Fun fact bis : des chercheurs ont découverts une nouvelle méthode pour extraire facilement d’un modèle de ce type la donnée privée présente dans l’entraînement ou le fine tuning. Si vous avez entraîné un modèle sur une donnée sensible, protégez ce modèle et son utilisation !
- Dans ce dernier cas, l’attaque peut être faite sur la donnée d’entraînement ou sur le fine tuning, même en ayant une connaissance très limitée de la forme de la phrase où se trouve la donnée sensible.
- Composer l’information, c’est savoir relier différentes informations entre elles, par exemple : « Jean est né à Londres, Londres est au Royaume-Uni, dans quel pays est né Jean ? ». Ce type de réflexion est un enjeu classique pour les approches de LLM.
- Des auteurs ont prouvé que ce type de composition de l’information ne peut être résolue correctement par les architectures Transformer, avec une limite forte en fonction du nombre d’éléments que l’on veut pouvoir composer.
- Enfin, parce qu’il faut toujours rêver un peu : Deepmind propose une nouvelle architecture plus optimisée, choisissant à chaque couche du modèle quels éléments de la séquence d’entrée seront travaillés.
Nouvelles limites des LLMs, nouvelles méthodes d’architecture, fun will never end…
Un LLM sait-il réellement distinguer une instruction d’une donnée à traiter ?
Si on contemple le paysage des Large Language Models via les nombreuses annonces de nouveaux outils ou de start-ups, on pourrait facilement croire que ces outils savent gérer le texte à traiter d’une manière assez fine, suffisamment au moins pour effectuer une telle distinction. Et pourtant, atterrissons sans grâce pour reprendre contact avec la réalité, une telle affirmation serait particulièrement dangereuse.
C’est ce que démontrent Zverev et al dans « Can LLMs separate instructions from data? and what do we even mean by that? ». La question est volontairement choquante, mais appuie au bon endroit pour nous réveiller. Ces modèles étant très récents, et notre domaine souffrant d’un déficit théorique considérable, cette question n’a même pas été correctement posée par les chercheurs. Peu étonnant donc de voir cette publication au workshop de l’ICLR 2024 dédié à la confiance et à la sécurité que l’on peut apporter à l’intelligence artificielle…
Le problème repris par les chercheurs est celui du contournement de prompt. Ce sujet est aujourd’hui bien connu : on développe un service via un LLM qui prendra en entrée le texte issu d’un utilisateur tiers. L’appel au LLM utilisera un prompt issu d’itérations plus ou moins glorieuses pour cadrer le résultat. Mais notre utilisateur peut s’amuser à insérer, dans le texte soumis, de nouvelles instructions détournant le LLM de son usage initial (le vilain), créant là une faille de sécurité peu acceptable.
C’est ce cas de figure qui est ici étudié par les auteurs. En effet, dans cette utilisation, le prompt initial est considéré comme l’instruction du LLM, et le contenu de l’utilisateur tiers est une donnée d’entrée qui ne devrait pas être exécutée. Les chercheurs questionnent donc ici, fondamentalement, la capacité d’un tel modèle à séparer l’instruction de la donnée d’entrée. Et les réponses sont, sans grande surprise, assez désagréables.
Pour adresser ce sujet, les auteurs définissent déjà une métrique permettant d’identifier à quel point un modèle est robuste quand un élément textuel est transféré de la zone d’instruction à la zone d’exécution. Ci-dessous, g est le modèle, s est l’instruction initiale, d la donnée d’exécution initiale, et x est un perturbateur :
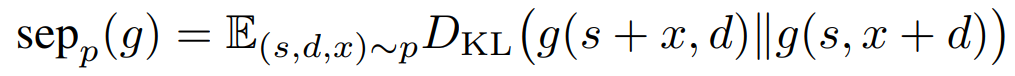
Ce score reprend notre bonne vieille divergence de Kullback–Leibler. Plus ce score sera élevé, moins le modèle fera une bonne division. Notons que cette métrique est assez « faible », en ceci qu’elle étudie juste la variation de la réponse quand on déplace le distracteur, mais ne s’intéresse pas à la qualité de la réponse.
Autre contribution des auteurs, la création d’un premier dataset permettant d’étudier ce type de perturbation et donc la capacité d’un modèle à séparer entre instructions et données à traiter. Le dataset SEP (should it be executed or processed) regroupe donc 9160 éléments, chaque élément étant constitué d’une instruction originelle, une donnée d’exécution, une instruction perturbatrice (qui sera un injectée soit d’un côté soit de l’autre), et la réponse à cette instruction perturbatrice. Un exemple d’élément est présenté ci-dessous :

Et donc, roulements de tambours mouillés, quels sont les résultats ?
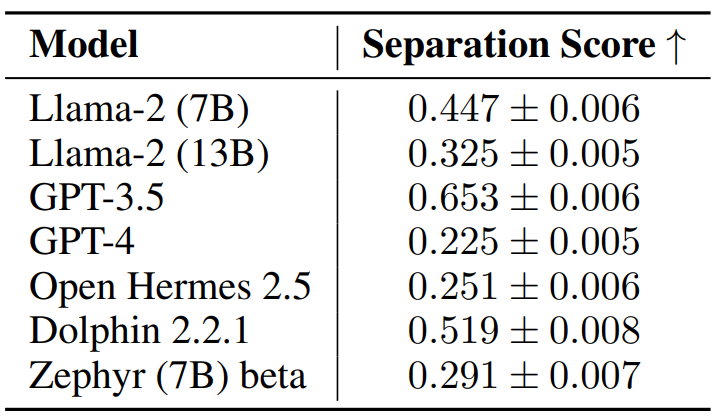
Plus le score de séparation est bas, moins le modèle fait la différence entre les deux concepts.. Et là, réelle surprise : plus un modèle est « gros », moins il va être capable de faire une distinction acceptable entre instruction et donnée, avec notamment GPT-4 qui est le plus mauvais modèle. En effet, ces modèles plus gros sont globalement meilleurs, mais beaucoup plus complexes à maîtriser, et donc beaucoup plus sensibles aux injections de prompt…
Ce travail est très important car il montre bien ce décalage entre un monde business qui s’envole dans les cieux pendant que les chercheurs continuent de poser des questions très fondamentales, questions auxquelles les réponses ne sont pas très rassurantes. Espérons que ce type de travail va engendrer d’autres approches d’analyses fondamentales pour enfin mieux comprendre ces outils et leurs limites. Sans cela, nous resterons condamnés à errer dans ces limbes où nous fantasmons les performances de ces modèles pour ensuite être totalement déçus…
Les LLMs entraînés sur une donnée sensible sont des bombes à retardement
Nous le savions déjà, via les approches dîtes de « Model inversion » : il est possible (voir, trivial) d’extraire, depuis un réseau de neurones entraîné, une partie de sa donnée d’entraînement. Dès lors qu’un modèle est entraîné sur une donnée interne à une entreprise, voire sur une donnée protégée (donnée personnelle, donnée de santé), il faut considérer le modèle comme étant lui-même une donnée à protéger.
Cet état des choses était déjà assez déprimant comme cela, Deepmind nous propose dans le cadre du récent ICLR 2024 un nouveau travail dans lequel ils décrivent une nouvelle forme d’attaque particulièrement angoissante, visant les Large Language Models que nous affectionnons tant. « Teach LLMs to Phish: Stealing Private Information from Language Models », de Panda et al, présente cette nouvelle apocalypse dont nous n’avions pas forcément besoin…
Les auteurs décrivent une nouvelle collection d’attaques, telles que :
- L’attaquant a une idée vague du texte en amont à utiliser pour forcer le modèle à recracher une donnée sensible. Le simple fait de demander un début de biographie permet d’activer l’attaque.
- L’attaquant peut empoisonner le dataset d’entraînement en ajoutant un nombre modéré d’éléments, pour ensuite pousser le modèle lors d’un fine-tuning a conserver les données sensibles qu’il voit passer.
- Dès lors qu’une donnée sensible est au moins dupliquée, le succès de l’attaque augmente de 20%. Plus le modèle est gros, et plus le modèle sera fragile…
- Les défenses classiques (déduplication) sont inefficaces.
Envie d’en savoir plus ? Ci-dessous un schéma reproduisant une des attaques décrites par les auteurs :

Ci-dessus :
- Quelques éléments dits « poisons » sont injectés dans le dataset. Ces éléments ne sont pas nécessairement injectés pendant tout l’entraînement, mais suffisent à enseigner au modèle à conserver des informations spécifiques (ici, numéro de carte de crédit)
- Lors du fine tuning, le modèle voit naturellement passer ce type d’information au moins une fois.
- Enfin, en utilisation, le modèle envoie un prompt reproduisant faiblement l’apparence des poisons, et peut récupérer cette donnée sensible.
Et sans surprise (le cynisme est un sport de combat en Deep Learning), cela marche extrêmement bien. Dans un premier cas, les auteurs analysent le cas où l’attaquant ne connaît rien au « secret », soit, l’information qu’il veut capturer. Plusieurs affirmations ci-dessous, où le « secret extraction rate » en ordonnée estime la proportion d’informations sensibles que l’on peut extraire :
#1 : Les secrets dupliqués sont très faciles à obtenir
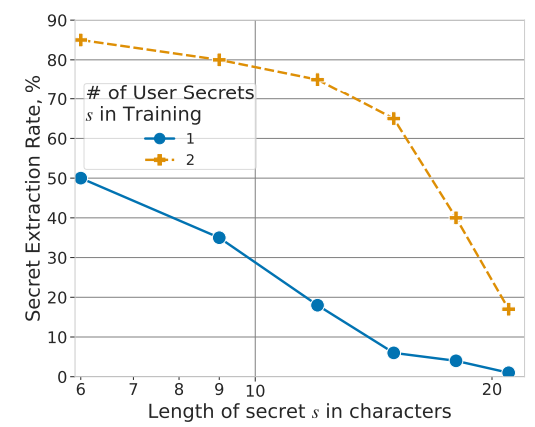
Nous observons deux courbes ci-dessus : la bleue où les secrets ne sont présents qu’une seule fois dans le dataset, et la courbe orange où ceux-ci sont dupliqués (deux fois chacun). Si nous observons à chaque fois une dégradation de l’attaque quand la taille du secret augmente, le simple fait de les avoir dupliqués suffit à faire exploser les scores.
#2 : Plus un modèle est gros, plus il retient par cœur ces secrets
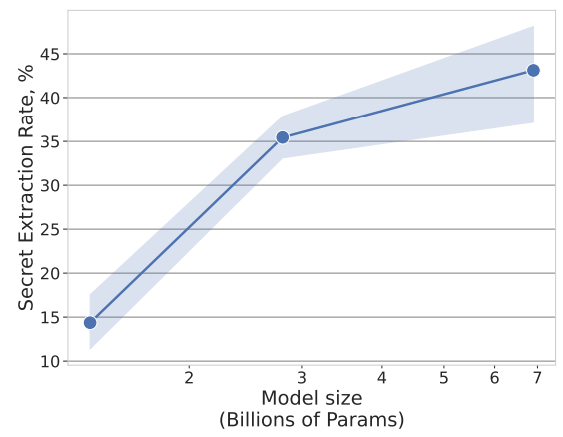
Nous observons que sur une attaque sans connaissance à priori, l’augmentation de la taille du modèle fait exploser le taux d’extraction. Nous retrouvons la triste et classique morale des LLMs : plus c’est gros, plus c’est dangereux…
#3 Un entraînement plus long ou sur plus de données aggrave les choses
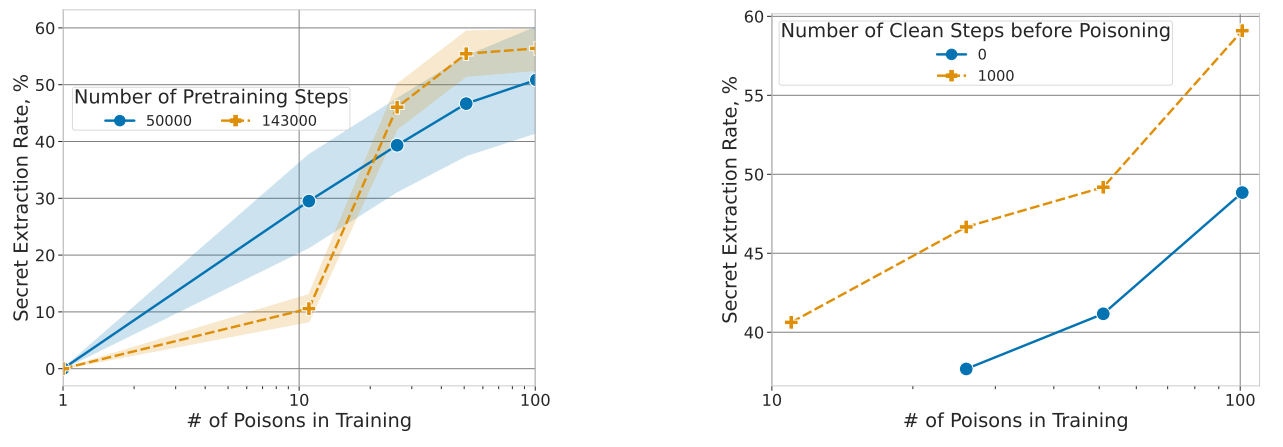
A gauche : avec suffisamment de poisons dans l’ensemble d’entraînement, le taux d’extraction s’aggrave quand le modèle a été plus entraîné.
A droite : faire un fine-tuning sur une donnée propre aggrave aussi le taux d’extraction des secrets.
Mais, rappelons-le, nous sommes ici dans un cas où l’attaquant ne sait pas exactement ce qu’il cherche ! Hors, dans l’immense majorité des cas, l’attaquant aura une connaissance imparfaite mais réelle de sa victime, et pourra donc utiliser cette connaissance à priori pour mieux cibler ses attaques. Dans ce cas-là, les auteurs arrivent jusqu’à 80% de secrets extraits. D’autres déclinaisons portent sur le federated learning, qui semble lui aussi concerné.
Qu’en conclure ? Que si on veut entraîner un modèle sur la donnée d’une entreprise, ou sur une donnée privée, il est inimaginable de ne pas totalement protéger ce modèle, mais qu’une protection parfaite n’existe pas… Dès lors, il paraît important de ne pas laisser un LLM en accès direct (même restreint), mais d’instrumenter les appels au maximum pour limiter la capacité du modèle à générer de l’information depuis son entraînement. Les LLMs sont d’excellents outils de modélisation du langage, mais les utiliser comme extracteurs d’information est aujourd’hui un sujet délicat, ne serait-ce que face aux limites que nous observons dans le domaine du RAG. Et ce n’est pas un hasard, cadrer un modèle pour limiter les problèmes (et notamment les hallucinations), c’est le sujet de notre prochain webinar du mois de mai 😊
La composition d’informations : une limite fondamentale des LLMs
Un peu dans la poursuite du premier travail décrit dans cette revue, nous avons là une nouvelle publication de Deepmind (qui reste, malgré les précautions épistémologiques, un prescripteur incontournable) s’attaquant à cartographier la capacité de ces modèles à adresser des problèmes simples spécifiques. Oubliez les oracles annonçant des modèles assistants humains polyvalents, le problème étudié ici est très simple et fondamental : la capacité à lier des éléments entre eux. Par exemple (le prompt est potentiellement beaucoup plus long mais contient ces informations) :
« Londres est dans le Royaume Uni… Alan Turing est né à Londres… Dans quel pays est né Alan Turing ? »
« On Limitations of the Transformer Architecture », de Peng et al, s’intéresse à ce problème dit de composition. Il s’inscrit dans une lignée de travaux visant à identifier des limites fortes de l’architecture du Transformer qui, depuis Vaswani et al, est l’approche incontournable en traitement du langage. Plusieurs résultats précédents sont déjà dignes d’intérêt :
- Il a été prouvé en 2020 qu’un Transformer ne pouvait pas reconnaître tout le temps la parité d’une information (par exemple, gérer des doubles négations) ou évoluer dans des parenthèses ouvertes récursivement…
- Cas plus complexe, l’approche dite de 3-matching consiste en trois nombres à la suite dans une séquence tels que la somme de ces trois nombres est égale à 0 modulo une autre valeur. Notons que l’approche de 2-matching elle peut être gérée par un Transformer mais pas par une autre architecture connue comme les MLPs, soulignant une supériorité des Transformers sur certains points.
À chaque fois, ce type de résultat permet de nous projeter un peu correctement dans ce que peuvent ou ne peuvent pas réaliser ces architectures. Attention néanmoins ! Ces travaux sont souvent limités à des formes assez simples de l’architecture en question, typiquement, une ou deux couches seulement. L’empilement des couches de traitement dans un modèle est un facteur fort d’évolution en complexité (certes mal contrôlée), et ces résultats perdent leur aspect « absolu » mathématiquement démontré face à des modèles comme Llama2, Llama3, GPT4 ou Mistral. Cet avertissement donné, les auteurs remarquent par exemple sur GPT4 que le problème semble persister.
Ici, pas d’illustration et c’est une bonne nouvelle ! Les auteurs démontrent (oui, une vraie démonstration mathématique) qu’un Transformer a couche unique sera incapable de gérer ce problème de composition de l’information dès que le nombre d’éléments à devoir composer dépasse un certain seuil, dépendant du nombre de têtes d’attention et de la dimensionalité de l’espace latent. Autrement dit : ces architectures (simplistes) ont une limite absolue en nombre d’éléments qu’elles sauront composer entre eux. Notons aussi que les auteurs étendent l’analyse au Chain of Thought (une des rares méthodes de prompt ayant survécu au-delà de trois mois) pour démontrer l’existence d’une limite similaire). Les exemples ci-dessous illustrent ce problème, cette fois-ci pour le modèle « state of the art » :

Rapportons ce type de résultat fondamental aux approches de types RAG, où l’on vient en fin de traitement créer un prompt long contenant le plus d’informations, pour ensuite demander à notre cher LLM de tout synthétiser, et observons que nous faisons là un pari bien dangereux… Ce n’est pas pour rien que dans un nombre important de cas où un client vient nous voir pour ce type de projet, nous questionnons l’importance du LLM pour modéliser un texte « joli » à la fin, face à la proposition d’informations unitaires correctement structurées !
Mais alors, comment utiliser un LLM ? Une réponse de Stanford
Il serait (trop) facile de remplir nos revues de recherche d’exemples déprimants (quoique nécessaires). Si ces modèles ont des défauts gigantesques, ils n’en gardent pas moins une puissance remarquable en manipulation du langage, et la bonne question est plutôt de savoir comment utiliser ces modèles. Rappelons que nous avions vu récemment, dans une autre revue, l’exemple AlphaGeometry où le LLM était confronté à un moteur de validation symbolique, pour des résultats impressionnants.
Le titre ici décrit l’ambition : « Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models », de Shao et al. L’article propose un mode opératoire global pour écrire des articles longs dignes de Wikipedia avec ces outils explosifs. Et la réponse repose fondamentalement sur une décomposition du problème en de nombreux appels différents, mieux structurés, pour obtenir des résultats beaucoup plus acceptables.
Les auteurs ici décomposent le problème : si je veux écrire un article complet, j’aurai besoin d’effectuer des recherches préparatoires pour aller chercher différentes visions d’un même sujet. J’aurai aussi besoin d’identifier les sources pertinentes (spoiler : ne frétillez pas trop vite), pour enfin générer d’abord un plan global et ensuite rédiger chaque section en suivant ce plan. C’est cette approche qui a été implémentée, de la manière suivante :
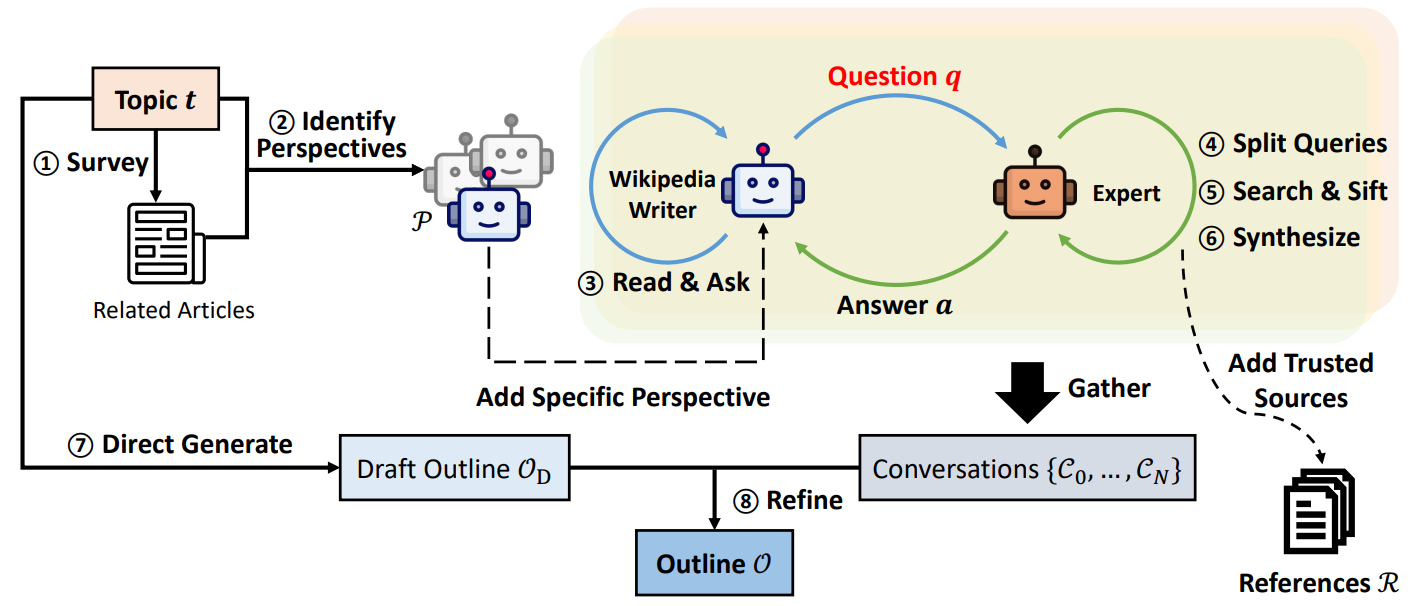
Nous commençons en haut à gauche avec un topic, un sujet sur lequel nous désirons écrire notre article. Nous allons avoir les approches suivantes (suivez les numéros dans le schéma 😊 ) :
- (1) : Le « Survey ». L’outil va aller chercher un certain nombre d’articles déjà existants pouvant être liés à notre sujet d’analyse. Une distance par similarité sera utilisée pour identifier ce contexte global de travail.
- (2) : La génération de « perspectives ». On appelle « perspective » ici un angle d’analyse du problème, définissant le comportement d’un agent. Par exemple, pour parler d’un quartier de Paris, on pourra avoir une perspective où le modèle doit agir en tant qu’agent immobilier, une autre où il aura dans son prompt un rôle d’habitant, puis d’historien, etc. Cette recherche de perspectives est ici fondamentale pour forcer les LLMs suivants à innover dans leurs générations de questions.
- (3) : Pour chaque perspective, un LLM est utilisé. Ce LLM va à chaque itération créer une nouvelle question sur le sujet à analyser en prenant en compte la perspective et l’historique des questions/réponses déjà générées.
- (4) à (6): Un second LLM, dit « expert », va recevoir cette question. Il va commencer par décomposer la question en requêtes unitaires à faire vers une base d’informations validées, exécuter ces requêtes et filtrer le résultat, pour ensuite générer une synthèse
- (7) : En parallèle, on demande à un LLM de générer le plan (outline) de l’article à respecter
- (8) : Enfin, l’ensemble des conversations générées est utilisé pour qu’un dernier (enfin !) LLM puisse générer le contenu.
Cette approche donne effectivement de bien meilleurs résultats. Nous remarquons que décomposer en nombreux appels spécifiques permet de limiter logiquement les hallucinations, tout en donnant un levier de contrôle sur l’outil : nous pouvons analyser et filtrer les perspectives utilisées, comme les conversations retenues pour générer le texte final.
Néanmoins, quelques remarques désagréables sont ici obligatoires :
- Déjà, nous multiplions ici le nombre d’appels à des LLMs, en faisant exploser le coût d’utilisation du système.
- Ensuite, même s’il a été observé que faire échanger deux LLMs différents permet de générer de meilleurs résultats, nous restons sur des outils dangereux pouvant échouer. Cela vaut aussi sur l’appel à l’expert pour synthétiser le résultat de ses recherches. Même si nous forçons un contexte basé uniquement sur des informations contrôlées et vraies, notre LLM pourra évidemment halluciner.
- Et d’ailleurs, si nous voulons nous projeter vers un outil professionnel, nous observons que la base d’informations validées est ici indispensable, et que l’on doit être capable de faire des recherches unitaires dessus avec succès, ce qui n’est pas impossible, mais pas forcément garanti…
Les évolutions d’architecture du Transformer se ramassent à la benne
L’auteur ne peut retenir totalement son émotion en pensant à toutes ces tentatives, jetées dans la mer d’Arxiv depuis 2017, visant à améliorer l’architecture de ce bon vieux Transformer. La majorité de ces tentatives dansent autour du mécanisme d’attention et de sa complexité quadratique, mais certaines, plus intéressantes que les autres, questionnent la capacité à aborder différemment chaque problème via une même architecture. L’enjeu est de créer un modèle capable de « décider » s’il a suffisamment traité une séquence ou non, afin de sortir du côté monolithique de ces architectures. Un candidat (que nous avions étudié en 2018) en son temps fut les Universal Transformers de Dehghani et al.
Aujourd’hui, Deepmind nous propose une nouvelle architecture qui semble très pertinente, même si le lecteur saura garder le recul nécessaire et ne pas la voir comme une solution définitive. « Mixture-of-Depths: Dynamically allocating compute in transformer-based language models », de Raposo et al, revient en effet sur ce sujet d’ajustement dynamique à la complexité d’une séquence avec une approche présentant des avantages nets.
Fondamentalement, l’idée ici est de contourner le principal problème de toutes les approches précédentes qui, certes, « décidaient » à l’intérieur du modèle du besoin de plus travailler certains éléments d’une séquence plutôt que d’autres. Ces approches étaient en effet « trop dynamiques », et quand bien même elles réduisaient le nombre de calculs nécessaires, le fait que ce nombre de calcul puisse varier causait de gros problèmes d’optimisation empêchant d’obtenir réellement, en fin de compte, une approche plus efficace. L’idée ici est de décider, en amont, du nombre de tokens sur lesquels travaillera chaque couche du modèle, et ensuite de forcer le modèle à choisir les tokens à conserver. Leur nombre n’évoluant pas, cette approche peut donc plus facilement être implémentée et optimisée.
Le schéma ci-dessous montre le mécanisme central proposé par les auteurs :
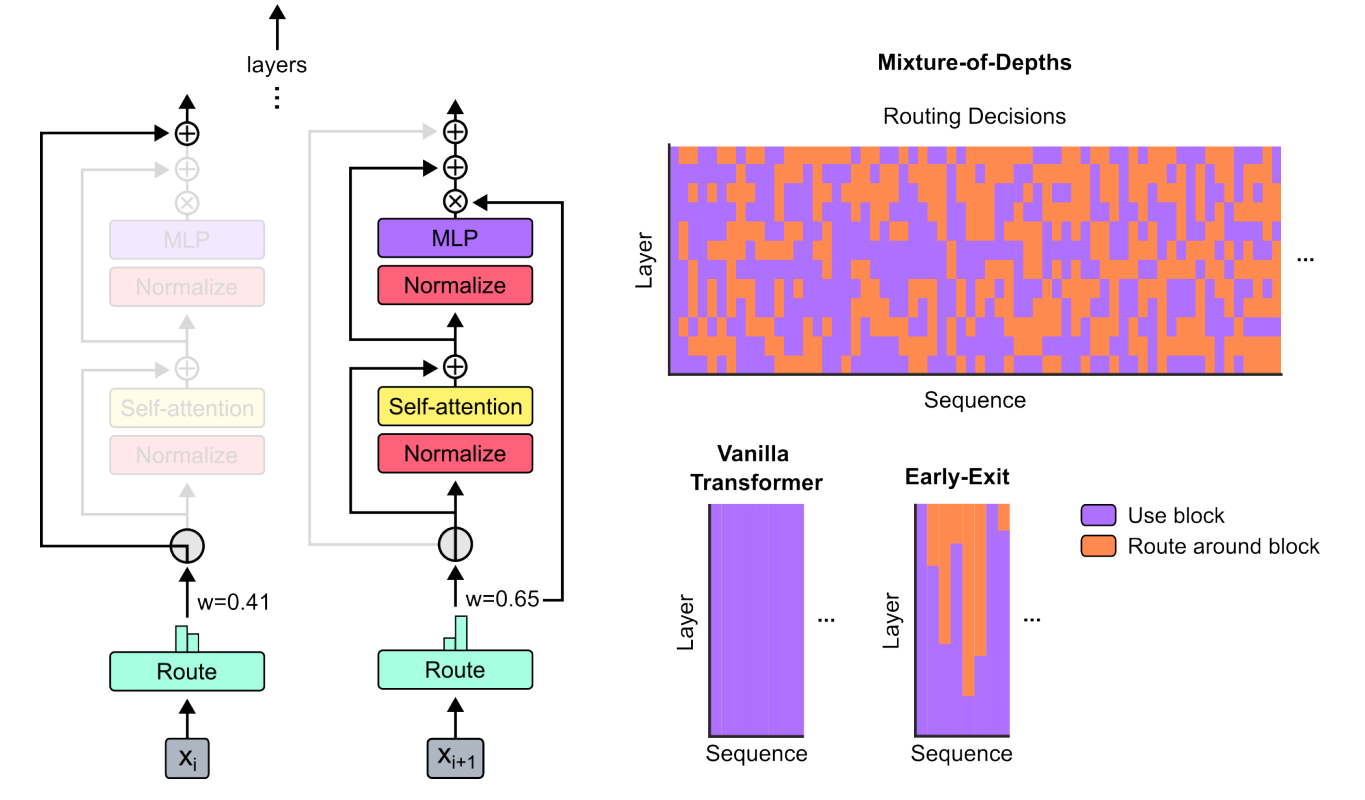
À gauche : on retrouve le mécanisme central d’une couche de Transformer, illustré dans le cas où un token ne sera pas source de calculs mais directement transféré à la couche suivante (cas de gauche), et celui où suite au calcul de « Route », le token sera au contraire transformé pour générer une nouvelle donnée de plus haut niveau (à droite).
À droite de haut en bas : le premier graphique montre à travers les éléments d’une séquence (en abscisse), pour les différentes couches du modèle (en ordonnée), si chaque élément a été traité ou au contraire a été routé autour du bloc. On observe que le modèle apprend, selon la couche, à gérer différemment chaque token. En bas, nous voyons d’un côté un schéma similaire pour un « Vanilla Transformer » (donc une architecture classique), et à droite la version Early-Exit. Cette version correspond aux approches précédant ce travail des auteurs, où on pouvait décider d’arrêter de travailler sur un élément de la séquence, mais uniquement d’une manière définitive.
Les résultats sont intéressants, et présentés sous deux formes d’application par les auteurs :
- A complexité de calcul similaire, les auteurs améliorent l’architecture initiale en gagnant jusqu’à 2% de précision.
- Plus intéressant : les auteurs entraînent un Transformer dynamique ayant la même qualité qu’un modèle classique, mais en divisant par deux le nombre de calculs.
Rappelons qu’en Deep Learning, accélérer l’entraînement est souvent plus intéressant qu’augmenter les résultats d’une manière brute. Et si nous ne pouvons évidemment garantir que cette architecture particulière s’imposera, force est de constater que ce type d’amélioration se généralise. On pourrait même rapprocher ce travail du Mamba (dont nous parlions dans la précédente revue) comme d’un candidat intéressant à surveiller pour la prochaine génération de modèles. L’approche monolithique des Transformers est effectivement un défaut (sur lequel Mamba, avec son système de sélection, prend un avantage certain). Ici, un intérêt de ce travail est qu’il bâtit sur d’autres travaux concurrents d’optimisation des Transformers et qu’il sera potentiellement plus simple à généraliser. Comme d’habitude, restons prudents et continuons d’espionner la recherche 😊