Why you should read this publication
Diving into causality in AI means navigating between the dream of a reasoning machine capable of identifying cause and effect, and scientific reality, which highlights the limits of our statistical models. This dossier traces the rise of “causal representation learning”, discusses the advances made at the CALM workshop (NeurIPS 2024) and presents emerging applications of causal graphs. Without indulging in myth or pessimism, we take stock of a field in full effervescence.
If you only have a minute to devote to reading now, here's the essential content in a nutshell
- The search for causality in artificial intelligence is a grail launched in 2021 to obtain new tools.
- An AI model capable of understanding causality would be much more robust to new data and easier to interpret.
- The field of Causal Representation Learning is tackling this subject with a great deal of work, but also with real difficulties, notably concerning the ability to intervene on a phenomenon to modify its state.
- The CALM workshop at NEURIPS 2024 was dedicated to this work in connection with Large Models. This is still an active area of research.
- Some are pushing to reduce the complexity of this undertaking and concentrate on identifying concepts in a model.
- Others propose approaches to the correct use of a LLM in causal graph generation, despite the many errors that will be encountered.
- We are already seeing applications in this field, for example in the correct classification of very short incident reports.
Causality and AI: introduction
Here are two terms that we’d like to bring absolutely close together. Causality is a logical mechanism of reasoning, where an observation is the consequence of an action or another observation. Discovering and interacting with the world theoretically presupposes an understanding of these mechanisms: a tumor detection in medical imaging should be based on the observed anatomy of the person, the manipulation of an object by a robot arm should apprehend the notion of gravity, and the response of a Large Language Model should be based on a sequence of logical reasonings…
And yet, it has to be admitted that, even today, our (all too) beloved AI models are basically statistical models, impressive though they may be, but they identify correlations rather than causalities. But there is a real current of research on the integration of this notion of causality into our models, and before presenting the latest cutting-edge results, we need to introduce the subject a little.
Two scientific studies should be consulted to understand this. The first, “Anchor regression: Heterogeneous data meet causality” by Rothenhausler et al, is regarded as an essential foundation. The author advocates replacing statistical inference ( if I observe in a room that every time a window is opened, the temperature is lower, I can consider that there is a correlation between these two pieces of information) by a causal inference (if I open the window, then the temperature will drop). When faced with a set of observations, the challenge is to determine the source factors that will imply other observations, and to qualify the causal links between these elements. As we shall see, one of the main challenges is to obtain approaches that are far more robust than conventional statistics.
But the founding publication of this movement in artificial intelligence is “Toward causal representation learning “with Schölkopf as first author and our very own Yoshua Bengio hidden behind. This 2021 publication can be seen as a manifesto for the search for new AI models that can, through learning, discover the logical structure (the causal links) of a given object. dataset representing a phenomenon. The stakes go far beyond mere intellectual satisfaction, because such models would have appreciable qualities:
- Robustness : unlike a conventional AI model, a causal model is much less dependent on the biases of the dataset training in that it would isolate generic mechanisms which it would then use to give an answer. We’re no longer working on correlations observed in the data, but on the logic behind them.
- Re-use of models : all practitioners Deep Learning practitioner has seen the best model collapse on a new dataset A causal model would not suffer from these problems, for the reasons outlined above relating to its robustness.
- Superior quality A causal model, free of correlations, would be much more efficient. At Deep Learning we model dependencies by conditional probabilities of observation, for example: “Seeing people with umbrellas in the street suggests that it’s raining. “. But this conditional probability does not allow us to act correctly, typically:” Closing umbrellas in the street would increase the probability of it not raining again “… On the contrary, a causal system would be free of this type of error.
There’s a slight problem here: if we want to discover causal links, we’ll need to know the impact ofinterventions. The aim of an intervention is to modify just one of the fundamental variables and observe the consequences of this modification. We’ll come back to this point later, but the diagram below shows the difference between a classical AI model and a causal model:
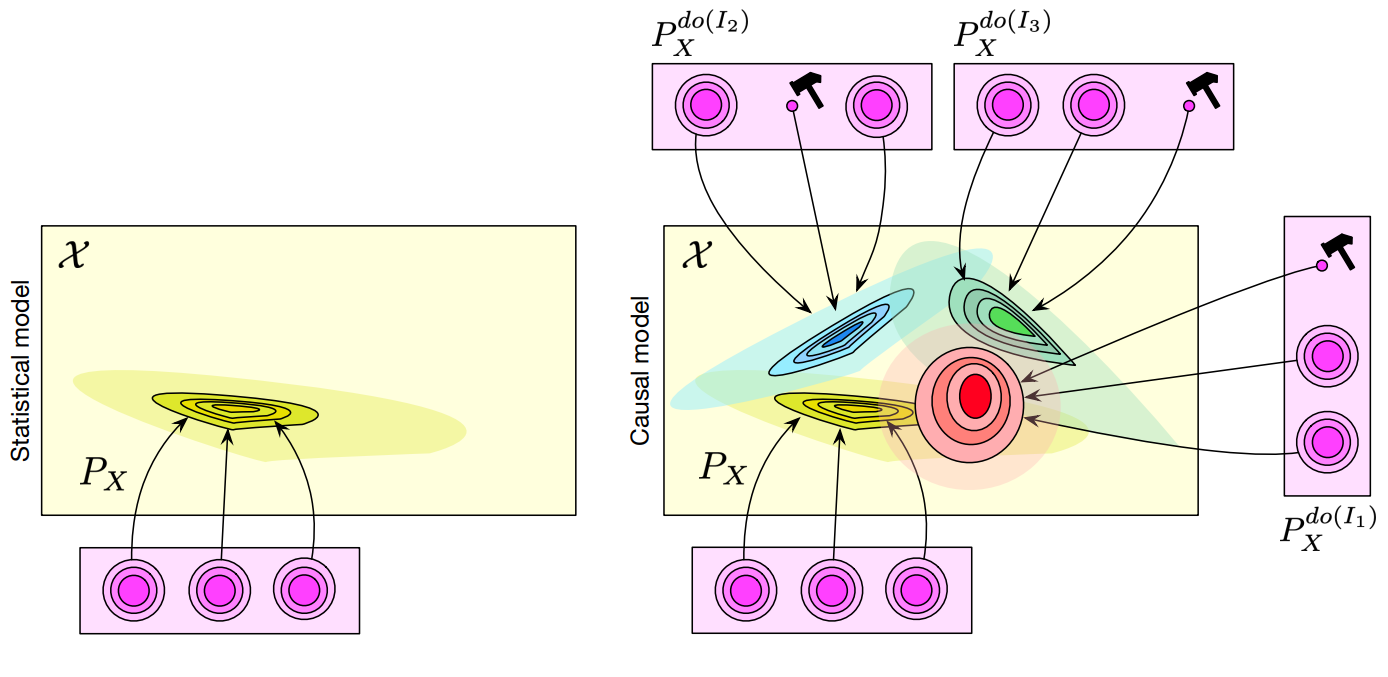
Left: a classic model. Each “circle” is a variable of interest, and the model projects all these variables into a target distribution.
Right: we can model the impact of an intervention on each variable of interest (the cute little hammers. Yes, they are cute ) on the target distribution, and thus estimate how each modifies the result.
A causal model has many advantages over a classical model. Let’s not forget that a classical model is only valid if it is used on data belonging to the same distribution as the training dataset, which is no longer the case here. The terrible Distribution Drift which makes AI engineers tremble, becomes apprehensible here: just because our medical images come from another practitioner or hospital doesn’t mean our model will collapse. And above all, we can hope to answer counterfactual questions, such as ” Would this patient have had a heart attack if he’d exercised more? “. This last point is very important, in that a causal model could play the role of a much more effective predictive model, in line with the research in World Models for example.
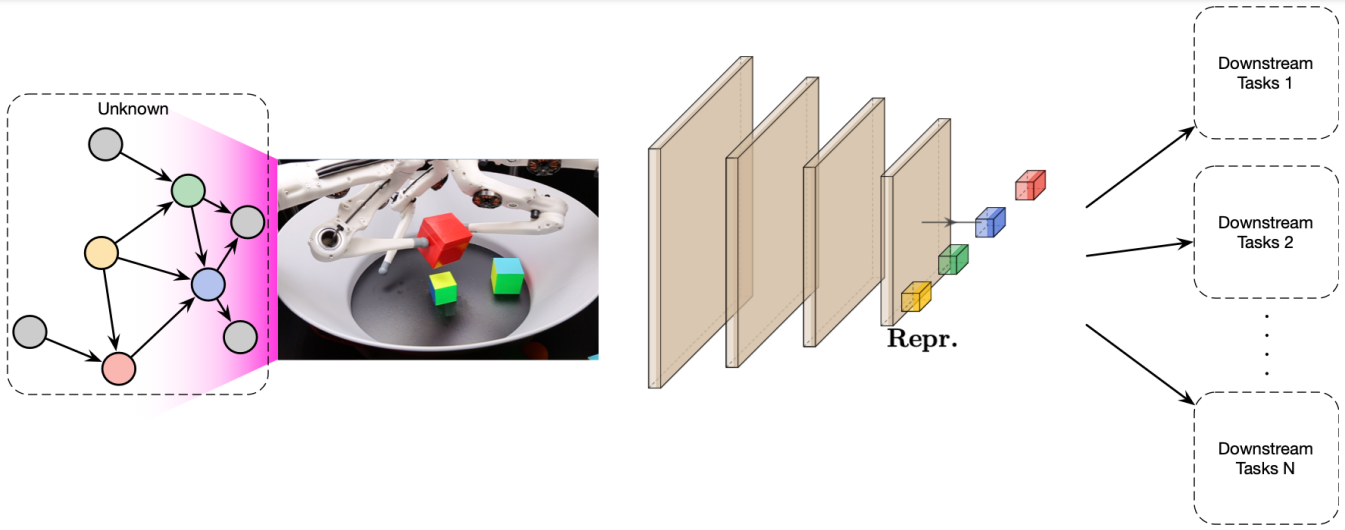
The diagram below represents the fundamental problem we want to tackle: a robot arm manipulates objects and only has access to the pixels of a camera image, without knowing the causal graph modeling the interactions between the objects. While we are unlikely to rediscover the full logical relationships between elements, a causal system could at least expose clear variables by, for example, separating the position and appearance information of each object in its representations.
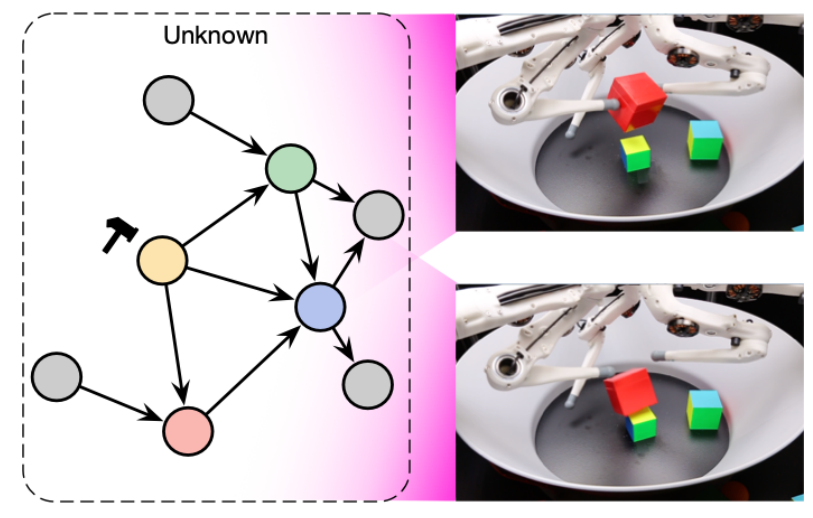
The image below shows an intervention modifying the position of one of the robot’s appendages. A classical model would only see a pixel modification, with the very heavy objective of identifying a correlation. A causal model, on the other hand, would be able to expose the important information that has changed.
Let’s take a step back: we’re talking about the reasoning of an AI model, after all. And we’ll see that the latest releases from OpenAI or DeepSeek cannot really lay claim to any form of reasoning, given their nature as statistical models. Should we then rush to these models? Not yet. At the time, this publication did not propose a solution to the problem, and “merely” launched a research trend. Modeling the impact of an intervention is extremely difficult, and the tools of Deep Learning is more a question of training the largest possible models than a fine-tuned control approach.
That hasn’t stopped many researchers from making progress on the subject. We’d like to invite you to take a look at one of them. workshop recent NeuRIPS 2024dedicated to causality applied to Large Models. This workshop gives us an exciting insight into the current state of causality research and the opportunities it presents.

Searching for concepts rather than causes
Among the publications honored at this workshop is a very interesting work from the laboratories of Meta. “From Causal to Concept-Based Representation Learning. Rajendran et al’s “Causal Learning” takes up the fundamental objectives of causal learning, and already offers us an accelerated view of the numerous works that have followed one another from the founding publication to the present day. Three years have gone by, and it has to be said that, while causal representation is still a hot topic among researchers, progress has been slow.
A fundamental question, in fact, is whether a causal graph can exist when faced with a problem! In many cases, even a human expert will not be able to state with certainty that there is a logical link between two assertions, or even if there is a logical link to justify certain observations. The researchers therefore tried to simplify the problem as much as possible to at least establish in which cases the search for a causal graph was simply possible. An important limitation was established in deciding whether causality graphs were possible: the need for several datasets representing the problem, these datasets are distinguished by interventions (we find them!). But if datasets are already uncommon, such datasets modeling the impact of an intervention on each variable are extremely rare, if not impossible to generate (if a reader is capable, for example, of modifying gravity in real time, please send us a CV as a matter of urgency)…
In this publication, the authors argue for a less ambitious but more reasoned approach. We’re no longer looking for the original causes of observations, but for projections of these causes, projections that we can link to the causes of our observations. concepts understandable by humans. The idea is that for each global concept, each variation of that concept exists in an affine subspace:
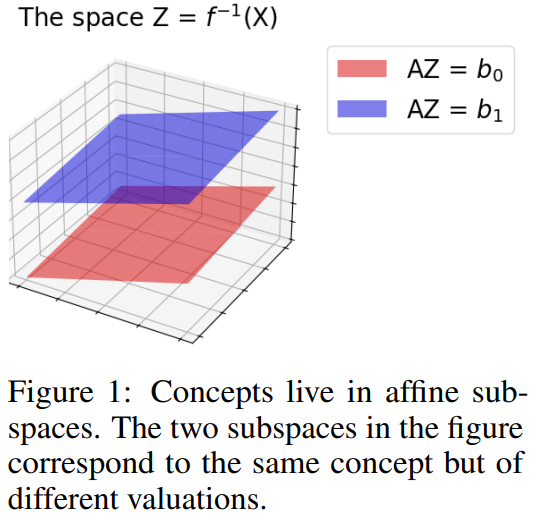
We note that we are now talking about concepts, not causality. This brings us into the field of interpretability research in artificial intelligence. The aim of this shift is no longer to depend on interventions to discover causalities, but of conditioning to discover concepts. Whereas intervention involves acting on the phenomenon in order to observe it, conditioning is more concerned with grouping the phenomenon together. dataset into subspaces where a concept is identified with variances.
We lose the aspect of logical discovery, but gain in efficiency. And this is the authors’ main plea: the approaches of Causal Representation Learning are doomed, and it would be better to work on concept modeling in model learning.
An example will probably make all this easier to digest. The authors have worked with the CLIP which, as a reminder, projects an image and natural language into the same space. They then input simple, different geometric shapes, with sub-variations in color, position and deformation. And then they tried to identify, using their method, a single vector linked to the shape concept. We can see below that projection onto this concept vector gives well-defined subspaces as a function of shape variation, for two different architectures:
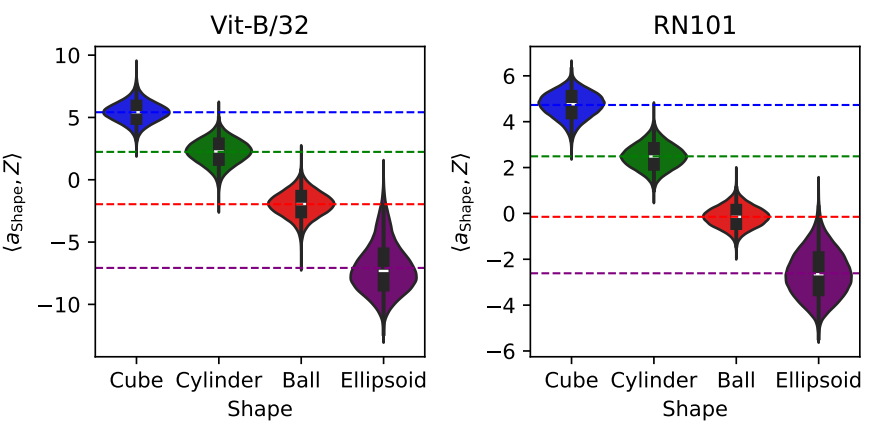
And that’s it. No further application, the problem of too recent research. But, by joining the work in interpretability, the field of causal learning becomes more credible and generic, and it’s up to us to watch what happens next…
Discover causality to classify short texts
Let’s leave this highly theoretical work behind and turn our attention to another gem from the Workshop CaLM. ” Using Relational and Causality Context for Tasks with Specialized Vocabularies that are Challenging for LLMs. “from Nakashini et al (Toyota research), tackles a very classic and still rather difficult problem: the classification of very short reports.
The challenge here is to qualify incident reports, which are still very short, written quickly by operational staff. A short text contains very little usable information, preventing conventional approaches from producing relevant results (and strongly encouraging the appearance of hallucinations in one of our good old LLMs). The idea here is to generate a causality graph from these relationships. This graph is then used to classify the input texts:
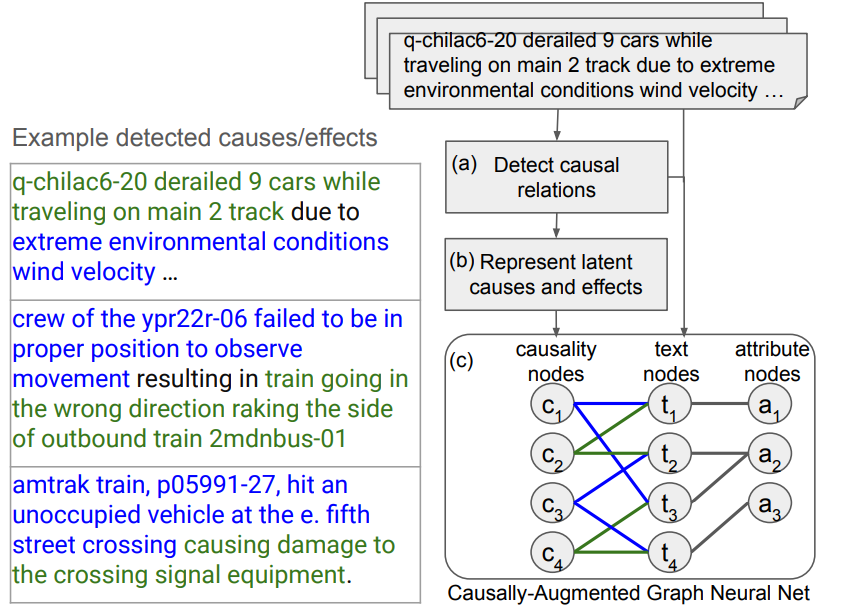
In the diagram above, we have various text reports of rail incidents. The colors (green and blue) are derived from LLM calls to distinguish cause from effect. This information is then aggregated to represent the causalities shared by different text fragments. This graph is then used to learn classes that can be used for these reports. Here are a few examples of the results:

Here, the approach works because we’re not looking for an “absolute” causal graph, but rather to separate causes and consequences within a very small business domain. Aggregation helps to limit the effect of poor LLM predictions (which will happen, of course). In practical terms, classifying short texts of this type has many applications in different business domains where we want to exploit limited textual feedback.
Looking for the causal order rather than the causal graph
The latest flagship publication from the workshop, ” Causal Order: The Key to Leveraging Imperfect Experts in Causal Inference “by Vashishtha et al, is also a feature of ICLR 2025 and will leave its mark. Let’s return to our theoretical (and somewhat desperate) goal: to discover a causal graph from observations in a dataset. Even with the best LLMs of the world, the undertaking quickly becomes insurmountable. An example of an application tested by the researchers was, faced with a set of observations ( A,B,C,D…) to submit to an LLM for each pair (AB, AC, AD… BC, BD, etc.), asking the LLM if one of the variables could cause the other, and then aggregating the results.
The problem with this naive approach is that it will be impossible, when working in this way, to distinguish whether a variable causes directly or indirectly another variable. For example, if we have the causal graph ” Lung cancer “🡪” Medical consultation “🡪” Positive X-rays “but that we only question the LLM than on ” Lung cancer “and” Positive X-rays “However, this will not allow us to construct an acceptable global causality graph! And yet, beyond the unitary response of the LLM, it’s this causality graph that we’re particularly interested in.
The authors therefore propose a different approach on two points, the first fundamental, the second more practical:
- We don’t want to ask the LLM to extract a causal graph, but a causal order. causal order. We speak of causal order when we distinguish between two observations if one is related to the other in terms of causality. In the example above, ” Lung cancer is related to ” Positive X-rays “. Although order information is less direct, the authors demonstrate that it is much more effective in converging on an acceptable causal graph. Indeed, it becomes simpler to aggregate all the responses from the LLM with this information.
- We don’t want to question our LLM on pairs of information, but on triplets, asking the LLM to give the causal order on the elements given.
The authors show that this approach is generally better when using LLMs or human experts to obtain causal information. The diagram below summarizes the approach:
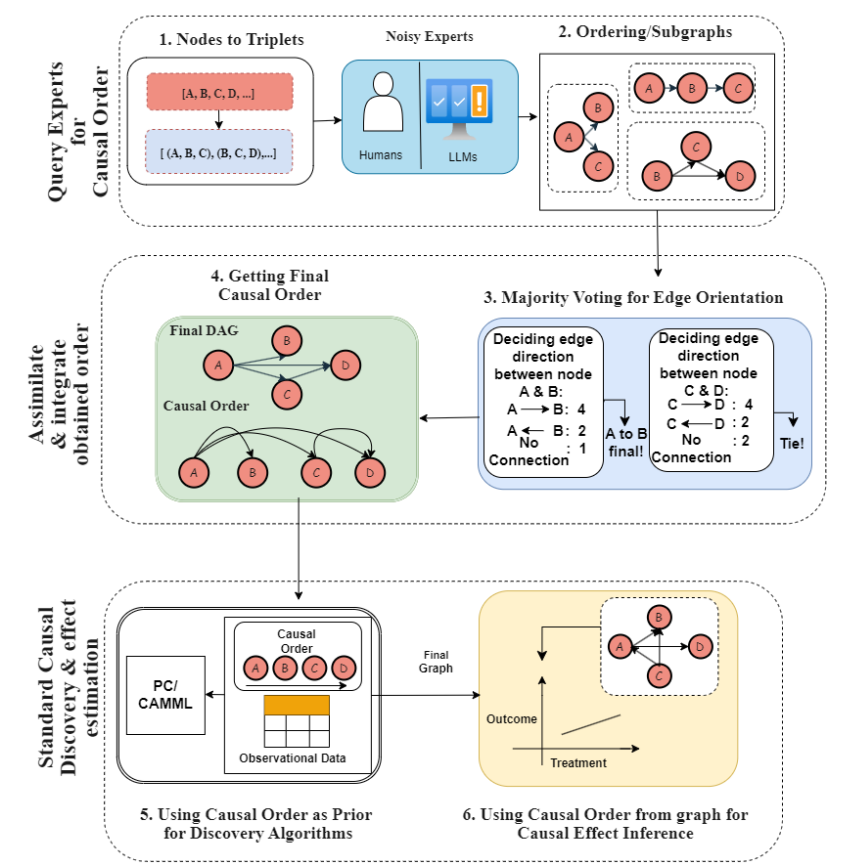
From top to bottom :
1 & 2: We generate triples from the set of information we want to process, and ask either the LLMsWe then use this information to generate graphs for each triplet. We then use this information to generate graphs for each triplet.
3 & 4: By analyzing all the results, we generate a final causality graph
5: It is then possible to use this graph as a condition for search/discovery algorithms by orienting/qualifying hypotheses.
6 : This graph can also be used for inference to identify causes in a specific case.
The authors also propose new metrics for qualifying a graph. They then compare different approaches, notably (below) between graphs generated by pairs of elements (with several variants) and those generated by triplets :
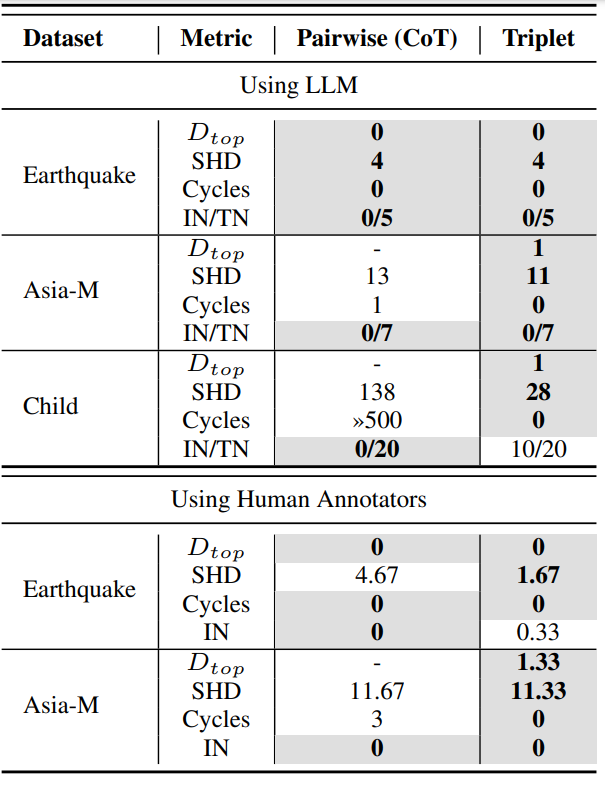
The metrics are Dtop (a metric of the authors on the topological quality of the graph), the SHD which was the classic metric for estimating the quality of a graph (the lower the better), the number of cycles in the graph (we want as few as possible if we’re working on causality), and IN/TN which gives the number of isolated nodes in the graph and the total number of nodes (we also want as few isolated nodes as possible).
Conclusion
What can we learn from this short journey?
Already, we can see that the “ultimate” goal of generating a causal graph via Deep Learning is currently an impossible task. This may come as a surprise when we come across the waltz of press releases on the “reasoning” behind AIs, but we’re just noting the wide gap between the reality of academic research and the overflowing communication around these tools.
Nevertheless, we have to admit that things are moving forward. Whether it’s shifting the battle to a (slightly) less complex domain, such as concept identification and interpretability, or developing more intelligent methods such as the use of causal order, we already have some interesting tools for working with information and extracting relevant structure. Of course, these systems are not perfect and must be considered as assistants to human experts, with their advantages and limitations. 😊