
Freeform pixels, robots qui rangent des chemises, transformation d’une image en environnement physique et déception en interprétabilité
Pour télécharger la version pdf, c’est ici.
TL;DR ?
5 mots-clés de nos Echos
EdgeAI, Imitation Learning, modélisation physique, interprétabilité, feature visualization
Quels process métier seront probablement modifiés sur la base de ces recherches ?
Le sujet du edge AI est encore en friche avec une vraie difficulté à déployer des réseaux de neurones correctement. L’arrivée d’une caméra auto-suffisante et préservant l’anonymat est un événement à ne pas sous-estimer, surtout que l’approche du freeform Pixel est particulièrement intelligente. Autre point, l’Imitation Learning avait déjà présagé une révolution de la robotique en rendant l’entraînement de modèles beaucoup plus simple. Deepmind étend ces approches avec des résultats sidérants sur le plan robotique, en industrialisant la notion de démonstrations. Autre point, plus triste : le principal outil que nous avions pour « interpréter » un réseau de neurones agissant sur des images a été violemment annulé par Deepmind. Nous n’oublierons jamais cet outil qui restera éternellement dans nos cœurs.
Si vous n’avez qu’une minute à consacrer à la lecture maintenant, voici le contenu essentiel en 7 points :
- La meilleure publication du récent ECCV 2024 propose une approche innovante pour créer des solutions IA en vision qui sont notamment très économiques en énergie.
- Ces solutions anonymisent naturellement la donnée, et les auteurs vont jusqu’à proposer un prototype hardware sur des problèmes non triviaux comme le décompte de personnes ou la mesure de vitesse.
- Imitation Learning : nous en parlions il y a 6 mois, et le sujet explose. Deepmind s’en empare et entraîne un robot sur des actions complexes, notamment en manipulant des objets souples comme des chemises (cauchemar des roboticiens)
- Au-delà de l’exploit, Deepmind a industrialisé le processus d’enregistrer des démonstrations avec des acteurs non experts, et cette approche s’étend facilement à de nombreux autres sujets.
- Partir d’une image fixe pour automatiquement détecter les objets, et simuler ensuite un mouvement physiquement crédible dans l’image est une réussite récente.
- Point d’intérêt : l’IA n’est utilisée ici que pour détecter les éléments, et un « vrai » moteur physique agit ensuite pour générer le mouvement
- Enfin, deuil : la feature visualization, qui était une de nos dernières cartouches valables en interprétation de modèles de vision, a été abattue mathématiquement par Deepmind dans le cadre du ICML 2024.
Freeform pixels et caméras auto-suffisantes respectant l’anonymat.
Soyons honnêtes. L’évocation de « pixels » appris par intelligence artificielle, qui permettraient de créer de nouveaux types de caméras auto-suffisantes sur le plan énergétique, invoquera avant tout le doute le plus profond. Et pourtant, cette publication de Columbia, ayant reçu le « best paper award » de la conférence ECCV2024, est un travail sérieux et passionnant. Parce que l’intelligence artificielle va (Dieu merci) bien au-delà des Large Language Models, ce travail mérite d’être étudié avec attention.
En effet, nous souffrons beaucoup de ces arbres qui cachent la forêt : les travaux en Deep Learning popularisés sont souvent des travaux très lourds, entraînant des modèles gigantesques (on dit « Frontier Models » en soirée en ce moment) pour des résultats toujours plus haut (selon la métrique académique et critiquable recommandée). Ici, les auteurs vont à l’opposé de ce mouvement, en recherchant une approche minimaliste pour s’attaquer à des problèmes de vision assez classiques : décompte du nombre de personnes dans une pièce, vitesse de traversée d’un véhicule, etc. La révolution porte ici sur l’extrême simplicité de l’approche, et nous allons voir comment de tels problèmes peuvent être résolus avec quatre petits pixels. (Cette dernière affirmation joue un peu sur les mots, mais c’est précisément le sujet ici). CI-dessous, un exemple du système pour le décompte de personnes, avec un capteur de 24 pixels :
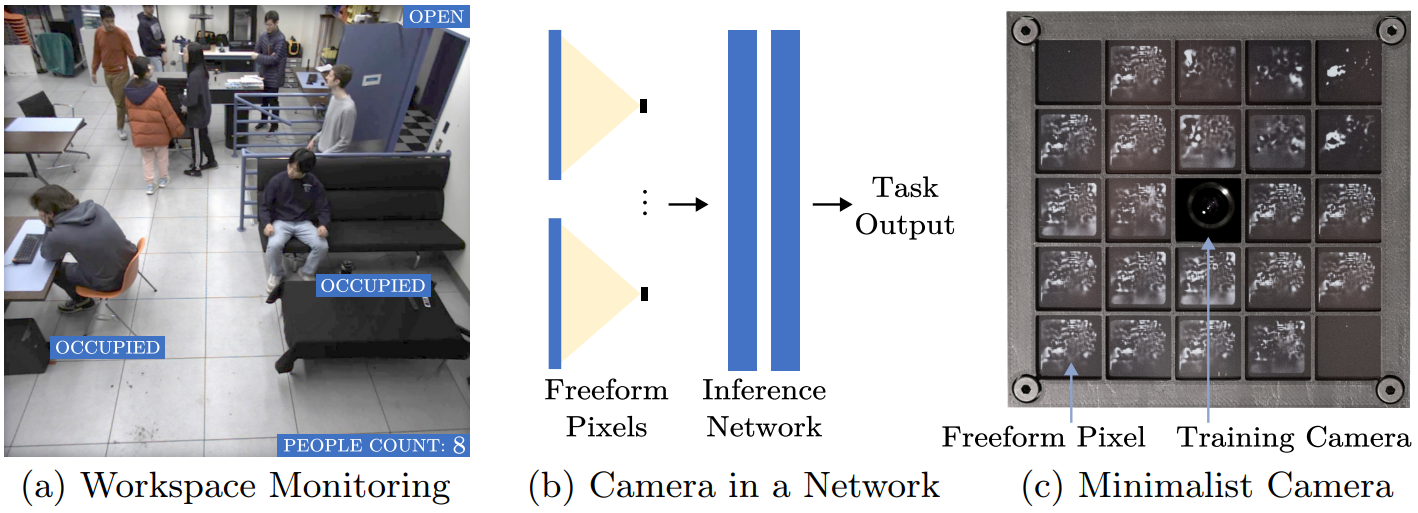
Attention : ce travail est passionnant mais donne très peu d’éléments de reproduction, un minimum de méfiance reste donc de rigueur…Mais rentrons dans le sujet, et qu’est-ce donc qu’un « freeform pixel » ? L’idée des auteurs est de modéliser une nouvelle forme de capteur qui, pour modéliser la valeur d’un pixel (donc une simple valeur d’intensité), ne va pas percevoir la lumière passant par un point minime (pinhole), mais qui au contraire va recevoir toute l’information lumineuse de la scène. Détail d’importance : cette information lumineuse va passer par un masque en deux dimensions qui va atténuer, voir supprimer, la lumière reçue à certains endroits. Notons que ce masque est, ci-dessous, un masque binaire, mais qu’il peut dans l’absolu prendre toute valeur entre 0 et 1.
Nous aurons donc un système basé sur un ensemble de ces pixels. Chacun aura un masque qui sera soumis à apprentissage face à un flux vidéo utilisé comme ensemble d’entraînement. La valeur de chaque pixel sera ensuite utilisée pour alimenter un réseau de neurones spécifique (ci-dessous : inference network) qui, lui, renverra la valeur supervisée souhaitée. Notons qu’un argument important apparaît en anonymisation : un tel système, exploitant quelques dizaines de pixels, anonymisera de fait l’image en entrée, ne pouvant conserver assez d’information pour pouvoir reconstituer un visage ou une personne à l’image. Tout du moins est-ce l’affirmation des auteurs, crédible mais à confirmer définitivement.
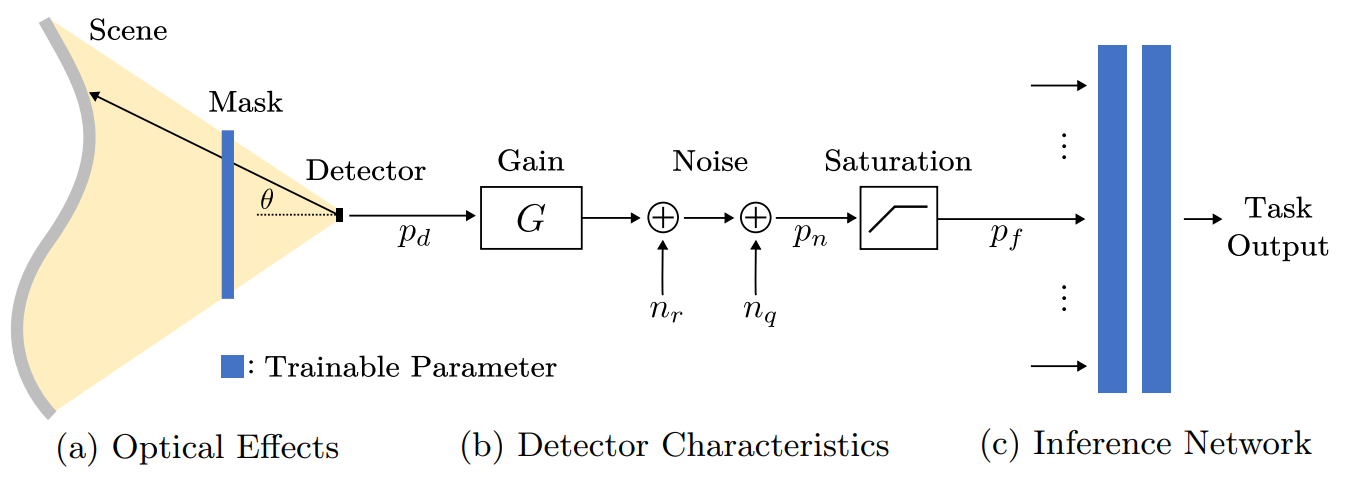
Mais, mais, mais… Est-ce que ça marche ? Les chercheurs ont dans un premier temps travaillé sur un cas de test simpliste, mais ont ensuite poussé leurs travaux jusqu’à créer un prototype de la « caméra » nécessaire pour différents problèmes. Pour créer ce prototype, on retrouve un ensemble de pixels avec, pour chacun, un masque imprimé résultant de l’entraînement du modèle. Une heure de vidéo est utilisée pour entraîner le modèle. Chacun de ces pixels transmet sa valeur via une amplification vers un microcontrôleur qui interagit en bluetooth avec un périphérique externe. Ce système est par ailleurs recouvert de panneaux solaires, lui permettant d’être auto-alimenté même en environnement intérieur. Notons qu’on peut changer l’application de la caméra en imprimant de nouveaux masques pour chaque pixel.

Et nous pouvons observer ci-dessous deux cas d’application intéressants. Le premier porte sur le décompte de personnes dans une salle, le second sur la détection de la vitesse de véhicules. On voit à chaque fois un graphique de performance en fonction du nombre de « pixels », comparé à une baseline qui utilise les pixels classiques (et qui est, soyons honnêtes, peu intéressante). On voit aussi les masques appris par les freeform pixels, qui opèrent un découpage de l’espace ad-hoc par rapport au problème adressé, et (pour le premier cas) un tableau de résultats bruts :

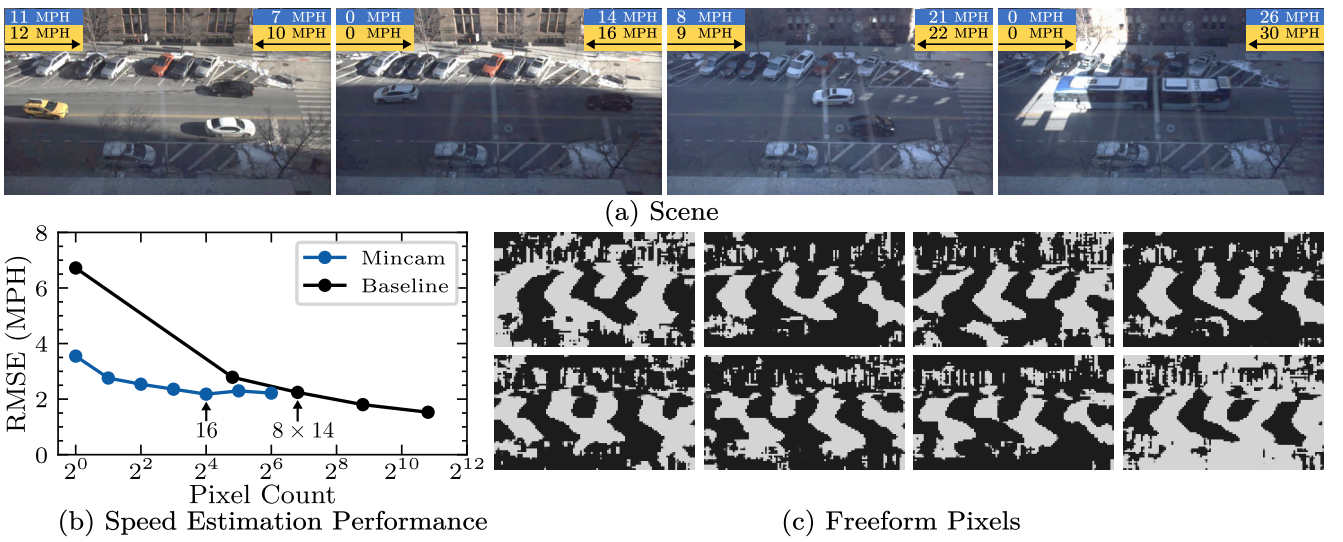
Pour conclure, ce travail mérite d’être suivi avec beaucoup d’attention. Nous sommes sur une nouvelle ouverture du Edge Computing, dans un contexte où l’énergie dépensée par ces modèles est un sujet qui fâche. Ici, en allant jusqu’au prototype matériel, les chercheurs de Columbia proposent une solution efficace et extensible, avec une anonymisation forte de l’image en entrée…
ALOHA unleashed : les robots savent plier une chemise
(Et c’est un petit exploit, mais reprenons les choses dans l’ordre)
Ceux qui suivent nos revues de la recherche n’ont pas manqué un article paru en mars 2024 portant sur l’Imitation Learning. Pour rappel, ce domaine a commencé l’an dernier à révolutionner la robotique et l’intelligence artificielle, plus précisément le domaine du Deep Reinforcement Learning. Ce domaine consiste à entraîner un agent à résoudre une tâche en maximisant une récompense modélisant la réussite de l’agent. Et si ce domaine a eu de nombreux moments de gloire (en manipulation robotique, ou via AlphaGo / AlphaGoZero), il a toujours souffert d’une énorme lourdeur dans les entraînements. Là-dessus étaient arrivés différents travaux pouvant entraîner un robot à partir de démonstrations enregistrées par des humains. Deux travaux étaient à l’honneur de notre dernière revue : les Diffusion Policies (que nous avions reproduit avec plaisir) et ALOHA.
Aujourd’hui, c’est Deepmind qui revient dans cette partie en s’inspirant directement de ces deux derniers travaux. ALOHA Unleashed est un travail qui mérite l’attention, au-delà du simple accomplissement technique. En effet, comme le relèvent les auteurs, les travaux précédents étaient impressionnants de par leur efficacité (entraînement de quelques heures pour un simple grasping robotique), mais étaient très limités dans leurs applications. Ici, le défi adressé par Deepmind porte sur la manipulation à deux bras d’objets déformables (comme une chemise), sujet terrifiant pour tout roboticien qui se respecte. En effet, il est déjà peu trivial de manipuler des objets rigides, alors manipuler un objet dont la forme évoluera radicalement en fonction des mouvements appliqués est un défi technique incroyable. Quelques exemples ci-dessous (avec d’autres cas comme la manipulation très précise) :
On note que ces actions peuvent être des successions d’actions complexes, comme le fait d’accrocher une chemise à un cintre (attention, ces images peuvent choquer des ingénieurs en robotique) :

Comme nous allons le voir, ce travail cumule plusieurs points pour arriver à ces résultats, notamment, une démultiplication des démonstrations enregistrées par des humains et un coût d’entraînement rédhibitoire…
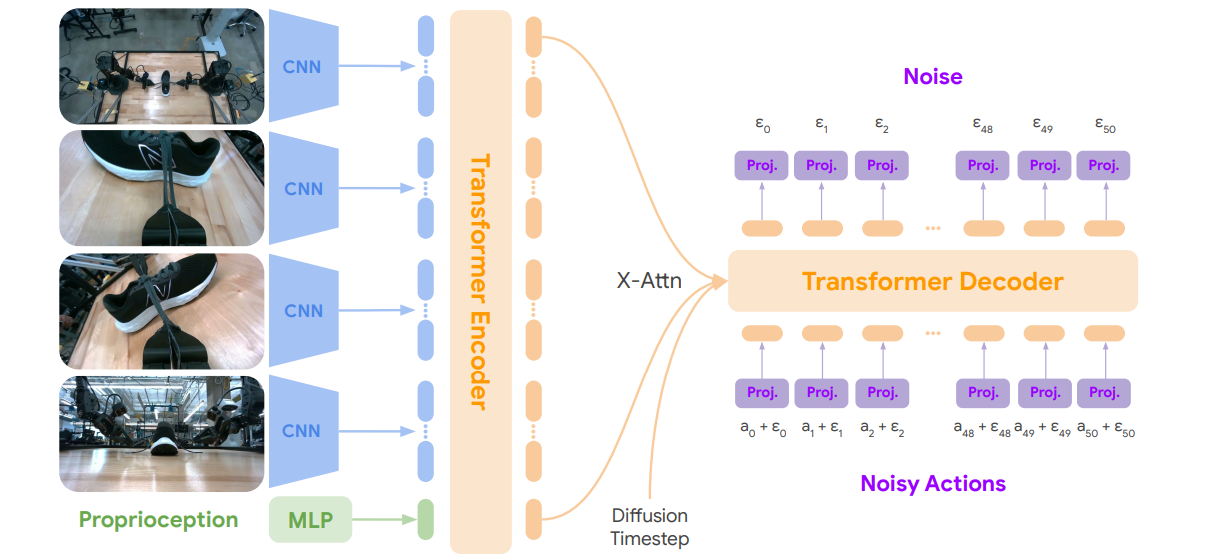
L’architecture utilisée est décrite ci-dessous. On note plusieurs points d’intérêts :
- Quatre caméras récupèrent des images. Ces images sont encodées par des réseaux ad-hoc, ici, des réseaux convolutifs de type Resnet50. Notons que l’utilisation de modèles convolutifs est ici intéressante, à rebours du « Vision Transformer partout ». Cette approche était aussi favorisée dans le cadre du Diffusion Policies.
- La proprioception est encodée par un multilayer perceptron classique
- Ces représentations sont mises en entrée d’un Transformer pour générer une représentation globale de la scène à l’instant t
- Enfin, les actions de contrôle du robot seront issues du décodeur, via une approche de diffusion (débruitage itératif). 50 passes sont nécessaires pour générer les prochaines actions à générer.
Pour rentrer dans les indispensables détails, nous sommes ici (contrairement aux approches précédentes) sur un entraînement très lourd. Basé sur le framework JAX, l’entraînement utilise 64 TPUv5e pendant 265 heures. Si nous voulons le reproduire, c’est un petit budget de 500k€… (Note : si ce budget pour un unique entraînement vous paraît acceptable, contactez-nous, nous rêvons d’échanger avec vous)
Mais ne nous arrêtons pas là et étudions un autre point important du travail de Deepmind : la multiplication des démonstrations. En effet, selon l’adage peu glorieux mais vrai disant que plus de données est toujours préférable, les auteurs ont industrialisé l’enregistrement de démonstrations par des acteurs non experts. Un total de 26.000 démonstrations sont enregistrées pour les 5 tâches. Notons qu’un protocole a été mis sur pieds pour que des utilisateurs non experts puissent interagir avec le système correctement (vous pouvez consulter un exemple de protocole à cette adresse). Et ce point mérite d’être étudié.
Le fait de pouvoir récupérer de nombreuses démonstrations sur une tâche pour ensuite les utiliser conjointement est un sujet encore complexe en Deep Learning. Néanmoins, l’accumulation d’une telle information peut se projeter dans de nombreux domaines métier, où des experts techniques effectuent un geste métier complexe. En reproduisant ce type de protocole, il devient imaginable via une approche Imitation Learning de générer ensuite un modèle pour se confronter au sujet cible. Nous rentrons dans une approche d’intelligence collective, à suivre donc.
PhysGEN : modéliser des forces physiques à partir d’une image
Une petite vidéo pour introduire le sujet 😊
[https://stevenlsw.github.io/physgen/static/videos/teaser.mp4]
Nous parlions dans notre webinar de juillet dernier du sujet GameGEN, générant un jeu vidéo en deux dimensions à partir d’une image statique. Ici, le sujet est assez proche et a été à l’honneur du ECCV 2024. A partir d’une image statique, sur laquelle on a un fond (background) et des objets au premier plan, le système va pouvoir détecter les éléments pouvant se déplacer et permettre de leur assigner une force initiale pour ensuite observer le mouvement résultat dans une vidéo. La qualité de rendu est assez impressionnante, mais prends garde, toi qui rentre ici en voulant rêver d’IA Générative ! Le travail présenté ici marche fondamentalement car il minimise l’intelligence artificielle là où elle est strictement nécessaire, condition de réussite inévitable si l’on veut un résultat fonctionnel.
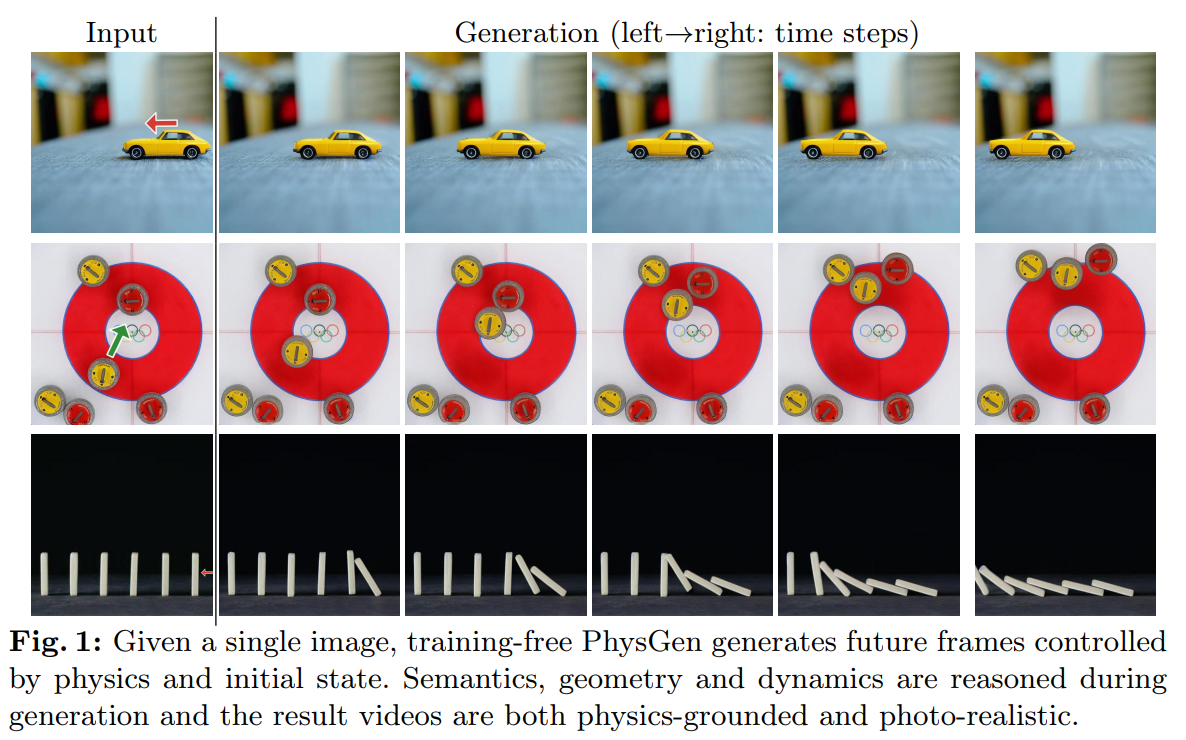
Rentrons dans le détail et étudions la méthode mise en œuvre :
- A partir de l’image fixe, un premier enjeu va être d’identifier les éléments pertinents, notamment, distinguer le fond (avec potentiellement des éléments causant des collisions) des éléments au premier plan qui, eux, peuvent recevoir une force initiale ou réagir à la collision d’un autre élément. Pour ce faire, deux modèles différents sont utilisés : GPT4V pour catégoriser les objets et générer des informations physiques, et GroundedSam pour délimiter ces éléments correctement. Notons que GPT4V peut, ici, parfaitement halluciner, mais soyons lucides, peu de modèles cross-modaux atteignent sa qualité à date.
- Une fois les éléments délimités, nous voudrons calculer le mouvement de chaque élément. Ici, pas d’intelligence artificielle et c’est une bonne nouvelle ! Une approche par équations différentielles classiques est utilisée pour générer les mouvements.
- Ce mouvement obtenu, des améliorations des images générées seront appliquées, avant de passer ensuite par un modèle de diffusion générant des images esthétiquement plus agréables dans le temps.
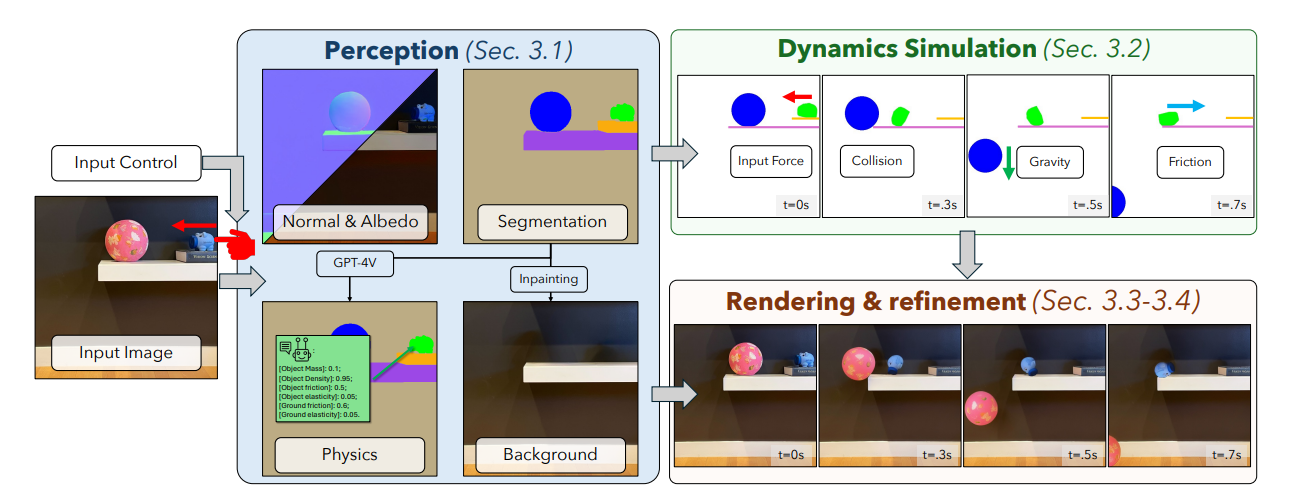
Pour conclure, ce travail est intéressant surtout dans son alliance entre méthodes classiques (simulation dynamique) et IA (détection des éléments en entrée, amélioration de l’image en sortie). Rappelons qu’une phase sans intelligence artificielle est une phase sécurisée et contrôlée 😊 Et ce type d’approche peut se rapprocher de ce qui se fait en jumeau numérique, où on utilisera l’intelligence artificielle pour initialiser le simulateur pour ensuite laisser ce dernier faire son travail correctement.
(Très) mauvaise nouvelle : la visualisation de features ne marche pas
Petite apocalypse : déjà que les techniques d’interprétabilité du Deep Learning crédible se compte sur une main éclopée générée par un modèle de diffusion, voilà que la technique principale que nous connaissions est violemment invalidée par Deepmind. Le prix à payer quand on travaille dans un domaine innovant comme l’intelligence artificielle, me direz-vous, et nous ne pourrons qu’acquiescer consciencieusement.
De quoi parlons-nous ? Deepmind a lâché une petite bombe dans le cadre de l’ICML 2024 via la publication « Don’t trust your eyes: on the (un)reliability of feature visualizations, Geirhos et al ». Cette publication revient sur la « feature visualization », une technique centrale d’interprétabilité, technique dont nous vous aurons parlé si vous avez suivi une de nos formations 😊. Cette technique, dédiée aux modèles IA travaillant l’image, permet d’identifier l’activité d’un « neurone » du modèle via une image représentant ce neurone. Un petit exemple issu du projet « Lucid » en dira plus qu’un long discours :
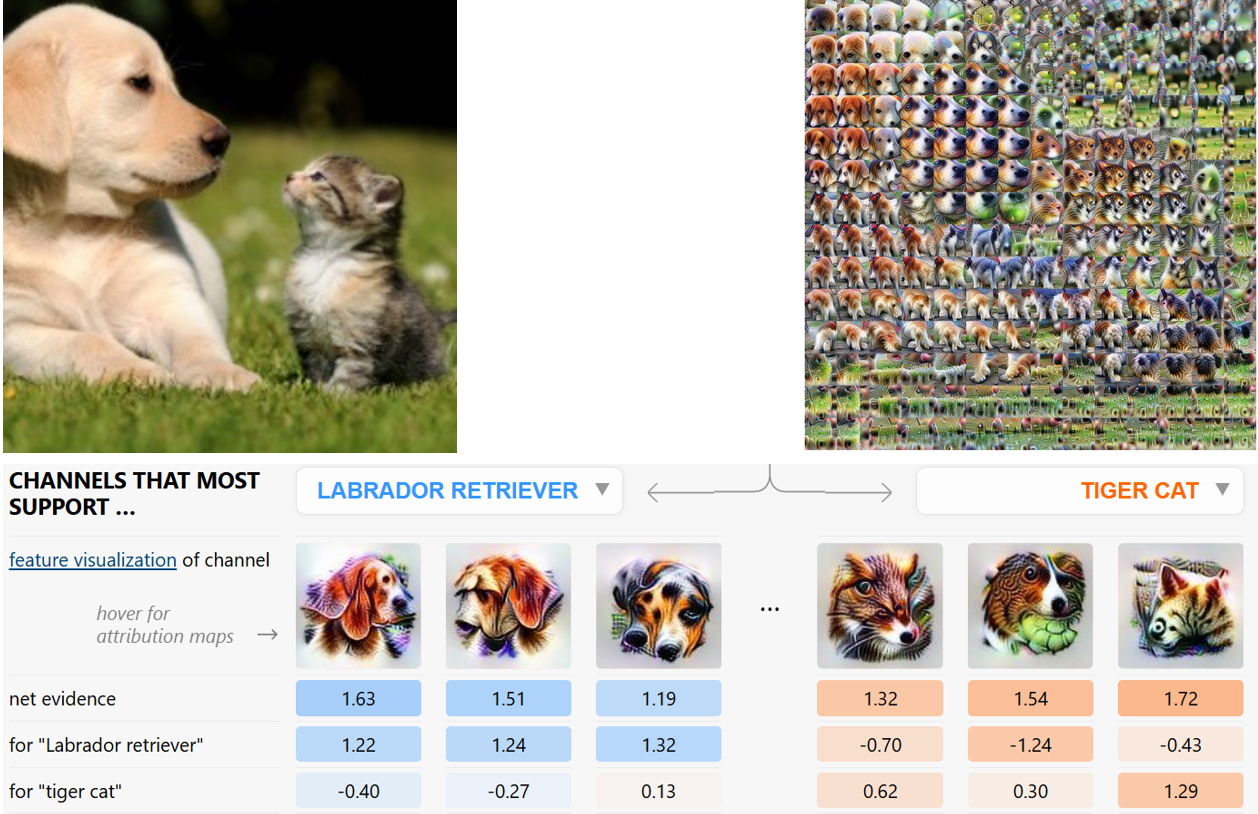
Ci-dessus :
- En haut à gauche, l’image d’entrée
- En haut à droite, l’image telle qu’elle est « vue » à l’intérieur du réseau de neurones. Chaque carré est précisément une feature visualization du pixel intermédiaire.
- En bas : principales prédictions et feature visualizations des neurones ayant le plus contribué aux prédictions
Cette technique est utilisée depuis 2017 jusqu’à aujourd’hui, et était considérée comme une des rares techniques « valables ». Mais est-ce que ces visualisations étaient réellement efficaces, où est-ce parce qu’il n’y avait pas de concurrent crédible que nous nous en contentions ? La réponse est, ici, désagréable.
En effet, les chercheurs de Deepmind essaient déjà de voir s’il est possible de faire activement mentir une de ces visualisations. L’idée est de forcer des visualisations arbitraires à modèle égal, et de prouver que l’information en sortie peut être totalement décorrélée de la réalité de ce que fait un neurone. Ici, les auteurs introduisent dans le modèle des unités « silencieuses » qui perturberont la visualisation. Notons que nous sommes dans un cas d’action malveillante, ou un attaquant ferait volontairement mentir ces observations :

Les visualisations à gauche sont « normales ». Celles à droite portent sur le même réseau, mais manipulées, et force est de reconnaître que l’interprétabilité n’ira pas bien loin.
Allant sur une approche non plus « malveillante », mais sur la fiabilité de ces visualisations, les auteurs ont effectué une comparaison sur à quel point ces feature visualizations peuvent représenter certaines classes d’images. On voit dans le schéma plus bas que dans les premières couches, la représentation d’une image par exemple de crocodile sera aussi proche d’autres images de crocodiles que d’images par exemple de fleurs ou de voitures. Les choses évoluent mieux vers la fin du réseau avec une meilleure discrimination, mais ces résultats montrent déjà qu’une visualisation sur les premières couches a peu de sens d’être discriminante :
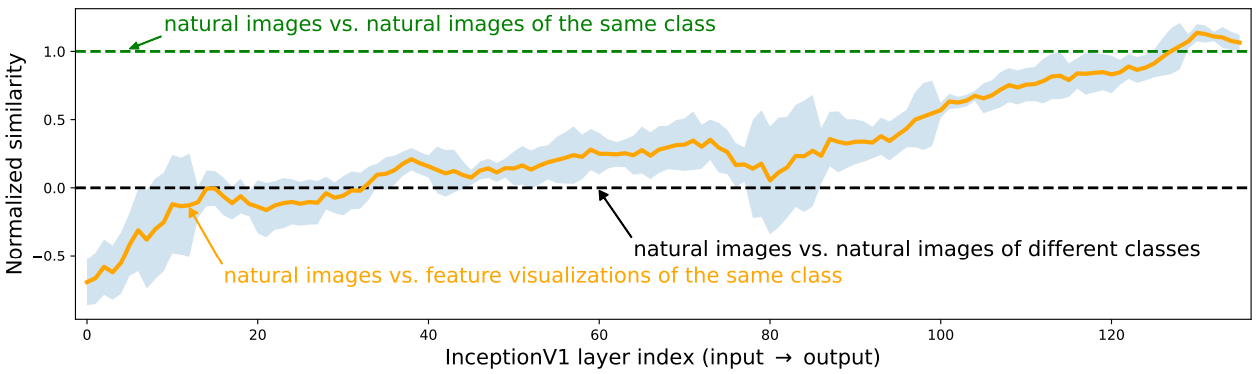
Mais le véritable résultat est mathématique, et repose la question de ce qu’est l’interprétabilité : peut-on, à partir de ces features, successivement :
- Prédire le résultat d’un modèle à partir d’une entrée ?
- Prédire ce résultat avec un bruit qui soit limité ?
- Prédire ce résultat en estimant le minimum et le maximum ?
La réponse, ici démontrée, est négative. Dans la majorité des cas, ces techniques ne permettront pas de répondre correctement à ces questions, invalidant cordialement l’approche.