
IA & modèles de diffusion : révolution artistique, scientifique, et demain industrielle?

L’intelligence artificielle s’est toujours distinguée par cette capacité à faire tomber soudainement des murs techniques que l’on pensait inamovibles. Point sur les nouvelles évolutions permises par l’IA.
Article écrit par Eric Debeir, lead data scientist
Sommaire
Modèles de diffusion ?
Vous avez probablement entendu parler d’une de ces récentes révolutions, avec la génération d’images bluffantes à partir de phrases descriptives. Si ce n’est pas le cas, petit rattrapage : depuis quelques mois, il est possible via de nombreux outils de créer de nouvelles images à base de réseaux de neurones… Quelques exemples :
- Prompt: A full shot of a cute magical monster cryptid wearing a dress made of opals and tentacles. chibi. subsurface scattering. translucent skin. caustics. prismatic light. defined facial features, symmetrical facial features. opalescent surface. soft lighting. beautiful lighting. by giger and ruan jia and artgerm and wlop and william-adolphe bouguereau and loish and lisa frank. sailor moon. trending on artstation, featured on pixiv, award winning, sharp, details, intricate details, realistic, hyper-detailed, hd, hdr, 4k, 8k.
- The war by Robert Capa. Prompt : Complex 3 d render of a beautiful porcelain cyberpunk robot ai face, beautiful eyes. red gold and black, fractal veins. dragon cyborg, 1 5 0 mm, beautiful natural soft light, rim light, gold fractal details, fine lace, mandelbot fractal, anatomical, glass, facial muscles, elegant, ultra detailed, metallic armor, octane render, depth of field
- Prompt: Complex 3 d render of a beautiful porcelain cyberpunk robot ai face, beautiful eyes. red gold and black, fractal veins. dragon cyborg, 1 5 0 mm, beautiful natural soft light, rim light, gold fractal details, fine lace, mandelbot fractal, anatomical, glass, facial muscles, elegant, ultra detailed, metallic armor, octane render, depth of field
Ces exemples ont été tirés au hasard depuis l’excellent site : https://lexica.art/
De nombreux projets de recherche ont attaqué ce sujet de génération d’images : Imagen de Google , DALL.E . Mais c’est un travail plus récent qui a révolutionné l’Internet, notamment car les modèles étaient, cette fois-ci, accessibles librement sous licence Open Source : les Latent Diffusion Models. Depuis la diffusion de cet outil, un énorme débat a émergé au sein de la communauté des illustrateurs :
- Ces modèles peuvent-ils être vus comme des outils de création artistique ? Instinctivement, non, et pourtant, nous ne faisons qu’effleurer les utilisations possibles de ces modèles…
- Quid de la concurrence demain entre des illustrateurs qui passeront un temps certain sur leur travail, et l’exploitation d’un modèle IA ? Il y a en effet fort à parier que dans de nombreux cas, les donneurs d’ordre ne seront pas forcément sensibles à la valeur ajoutée d’une réelle création artistique ?
- Dans la mesure où ces modèles ont été entraînés sur une gigantesque base d’images comprenant majoritairement des travaux de vrais artistes, comment considérer les résultats du modèle, surtout quand les utilisateurs ne se privent pas d’utiliser des noms d’artistes encore en activité ( https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/731 ou https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/688 ) ?
Apparation des modèles de diffusion
Au-delà de ces débats, d’un point de vue technique, nous pouvons constater l’apparition d’une nouvelle famille d’outils d’intelligence artificielle (les “modèles de diffusion”).
Cette famille d’outils présente déjà des résultats prodigieux sur les apprentissages d’images.
Nous vous proposons d’étudier ensemble, en restant à haut niveau, la particularité de ces outils, comment ceux-ci peuvent s’appliquer à d’autres problèmes, et les opportunités générales apportées par ces modèles. Mais force est de reconnaître que la communauté scientifique du Deep Learning s’est emparée largement de ce sujet avec une explosion des travaux de recherche.
Par exemple, les équipes de recherche de NVIDIA (leader incontesté des modèles génératifs) ont récemment proposé une publication qui a été reconnue comme “outstanding paper” de l’incontournable conférence du NEURIPS 2022, publication dans laquelle ils approfondissent ces modèles et en proposent une meilleure compréhension.
Au-delà des images : audio, 3d, mouvement humain…
Commençons peut-être par là. Si l’application aux images a été fortement diffusée sur les réseaux sociaux, il serait très limité de s’arrêter là. Nous sommes en effet face à une nouvelle architecture qui s’applique déjà à de nombreux autres domaines, et qui demain pourrait s’appliquer à des problèmes particuliers sur une donnée métier.
L’application aux images en premier s’explique facilement, et c’est d’ailleurs un phénomène courant en Deep Learning. En effet, la donnée est beaucoup plus simple à récupérer, de nombreuses applications existent, et nous sommes très tolérants aux erreurs marginales dans une image générée, beaucoup plus que nous ne le serions face à de la musique générée.
Ceci dit, nous avons déjà pu observer des applications très différentes et passionnantes
Les nouvelles applications
“Multi-instrument Music Synthesis with Spectrogram Diffusion” est une application à la musique, où le modèle de diffusion va ainsi générer des extraits de musique avec de multiples instruments, en travaillant directement sur les spectrogrammes. Un mécanisme de conditionnement va permettre de poursuivre un morceau de musique dans la durée. Ce travail n’est pas encore bluffant sur le plan auditif, et nous ne sommes donc pas au niveau de la génération d’image ou un simple amateur pourrait facilement croire que l’oeuvre a été générée par un humain.
Néanmoins, force est de constater que les choses vont vite. Le dernier travail en date de génération musicale intéressant était l’oeuvre d’OpenAI avec leur Jukebox qui déjà était très prometteur. La publication plus récente est l’oeuvre de l’équipe Magenta de Google qui s’est spécialisée dans le Deep Learning adapté à la musique, avec de nombreux travaux passionnants.
Demain, ce type de travail peut s’appliquer à toute approche sur le domaine audio. En effet (nous en reparlerons par la suite), un tel modèle ne permet pas juste de générer de la donnée, mais d’approximer ses variances et de les contrôler.
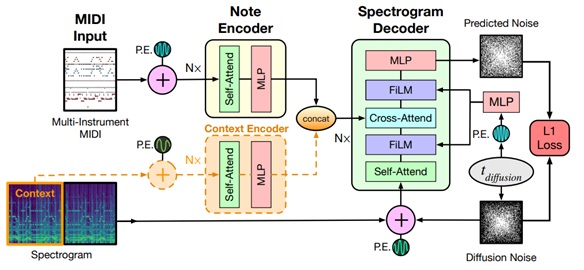
Modélisation et génération de mouvements humains
Autre approche passionnante, “Human Motion Diffusion Models”
Elle vise à modéliser et à générer des mouvements humains, notamment à des fins d’animation. Ce travail vise à pouvoir générer facilement le mouvement d’un modèle 3d représentant un individu, via une simple phrase décrivant l’action à réaliser. Ce travail est important, car en apprenant à générer un mouvement humain, il apprend implicitement à “résumer” ou “compresser” ces mouvements, et peut donc permettre de partir de mouvements détectés pour les normaliser ou les qualifier.

Génération de volumes en trois dimensions
Dernier exemple, la génération de volumes en trois dimensions directement depuis une phrase de génération. Plusieurs travaux existent déjà, nous recommandons le travail de Google Research et Berkeley “DreamFusion: Text-to-3D using 2D Diffusion”.
La génération de volumes en trois dimensions est souvent un passage obligatoire en modélisation, et ce type d’outils peut permettre d’alimenter très rapidement une architecture de traitement en nouveaux volumes avec un axe de génération très simple à utiliser. Au-delà, similairement au modèle de génération d’images, un tel modèle apprend la correspondance entre certains termes et leur expression en trois dimensions, que l’on parle du sujet, du style, de la position, etc. Les travaux futurs permettront (on l’espère) de mieux contrôler ce type de génération via une séparation plus pertinente de la génération.
Et la liste s’allonge tous les jours. On a récemment vu des propositions d’approches scientifiques pour faire de la détection localisée par modèles de diffusion, ou même enrichissant des modèles de langage de type BERT avec cette méthode…
Modèles génératifs : pour quels usages ?
Bref rappel
Les modèles génératifs sont une famille de modèles en Deep Learning (IA) spécialisés dans la génération de données. Entraînés sur un dataset composé de nombreux éléments, ces modèles apprennent à générer une donnée qui ne soit pas directement présente dans le dataset, mais qui corresponde à la distribution de la donnée telle qu’elle est représentée par ce dataset. Dit autrement, un tel modèle a pour objectif d’apprendre les règles globales propres à tous les éléments du dataset pour réussir à générer une donnée qui aurait pu se trouver dans ce dataset. On parle mathématiquement d’apprentissage d’une distribution. Évidemment, un tel modèle est très dépendant de la variance des données présentes dans ce dataset.
Ces modèles relevaient de la science-fiction jusqu’à 2013/2014 avec l’apparition de deux grandes familles de modèles génératifs.
Première famille de modèles génératifs
La première famille est celle des Variational Autoencoders (VAE) de Kingma. À très haut niveau, ces modèles apprennent à simplifier une donnée au maximum tout en apprenant la diversité (mathématiquement, la distribution) de cette donnée. Ce sont donc des outils très précieux pour pouvoir approximer une donnée dans sa complexité, avec ensuite la possibilité d’appliquer de nombreuses approches transversales : détection d’anomalie, clustering, etc. Ces outils vont donc au-delà du simple modèle génératif, et ont permis notamment de créer des systèmes IA avec une notion d’incertitude dans les prédictions.
Deuxième famille de modèles génératifs
La deuxième famille, un peu plus connue, est celle des Generative Adversarial Networks (GAN) de Goodfellow. Cette approche est déroutante au premier abord, avec un “duel” entre un modèle apprenant à générer de la donnée et un autre modèle apprenant à critiquer la génération. Elle permet néanmoins de facilement créer des modèles génératifs de bonne qualité. Le célèbre site “This person does not exist” présente ainsi des portraits d’individus qui n’existent pas, mais ont été généré par le StyleGan de Nvidia.
Le consensus jusqu’à récemment était que les GAN pouvaient donner de meilleurs résultats sur le plan de la qualité visuelle, mais que les VAE apprenaient beaucoup mieux la diversité d’une donnée et représentaient ainsi un outil plus puissant pour travailler sur une donnée complexe. Evidemment, en Deep Learning, les choses ne restent jamais stables très longtemps. Les “VQ-VAE” se sont imposés ces trois dernières années, et les modèles de diffusion sont ensuite arrivés.
Intérêt dans les processus métier et/ou industriels
Il ne faut pas sous-estimer l’intérêt de ces outils dans des processus métier et/ou industriels.
Un modèle génératif est un outil précieux pour l’ensemble des opérations d’analyse de la donnée. On pourrait même argumenter sur le fait que leur capacité à générer une donnée n’est pas leur principal attrait sur un plan appliqué, face à la possibilité de pouvoir les exploiter comme des outils d’exploration et d’analyse de la donnée.
Approximer la distribution d’une donnée, c’est devenir capable d’identifier les grandes variances de cette donnée, seules ou combinées, et de pouvoir ensuite questionner tout nouvel élément face à cette distribution.
Détection d’anomalies, simplification de la donnée, prise en compte de l’incertitude dans une prédiction ou dans une annotation ou clustering ne sont que la partie émergée de l’iceberg. Au-delà, tous ces modèles apprennent à projeter la donnée dans un espace beaucoup plus agréable, dans lequel des opérations arithmétiques simples donnent lieu à des modifications importantes de la donnée. Pour peut être rendre cette approche plus claire, reprenons l’exemple des images, et du StyleGan de NVIDIA générant des visages. Il devient possible d’éditer des images très finement, non pas en manipulant les pixels de l’image, mais en travaillant sur la projection de la donnée effectuée par le modèle :
(from https://github.com/yuval-alaluf/hyperstyle)
Les modèles de diffusion sont donc plus qu’un coup d’éclat réservé à la génération d’images. En tant que modèles génératifs, ces modèles présentent de nombreuses applications dont la majorité n’a sans doute pas encore été découverte.

Modèles de diffusion, quelles opportunités ?
Quels intérêts futurs ?
Les modèles de diffusion ne font donc qu’arriver, mais nous pouvons déjà réfléchir à ce que ces nouveaux outils vont nous apporter en termes d’usage, au-delà du simple traitement d’images. Pour cet exercice légèrement acrobatique, trois sources peuvent alimenter notre réflexion :
- 1/ L’exploitation des approches issues de l’inférence variationnelle (VAE ou Normalizing Flows), qui ont poussé ces modèles au-delà de la simple génération de données, et qui servent aujourd’hui d’outils
- 2/ L’observation de ce que produit la communauté sur Internet à partir de la récente diffusion du modèle Stable Diffusion, ou de nouveaux usages apparaissent régulièrement.
- 3/ Nous voyons que cette approche s’applique déjà à d’autres types de données (audio, mouvement humain, volumes en 3 dimensions), et pouvons donc imaginer ce que ces nouvelles données vont apporter
Détails des points évoqués
Le premier point est sans doute le plus fondamental, mais le plus complexe à prévoir. Un modèle de diffusion apprend à approximer une donnée dans sa distribution (au sens mathématique). Cela implique que l’on peut s’en servir pour des problématiques comme la détection d’anomalie (comme par exemple la maintenance prédictive). Les prochains mois nous montreront si le monde académique arrive à produire des résultats à ce sujet. Évidemment, il faut garder un principe de précaution, et ne pas utiliser un outil sous prétexte qu’il est récent et “sexy”. Il faut plutôt questionner dans quelle mesure ce nouvel outil pourrait améliorer notre capacité à adresser certains problèmes. Hors, la détection d’anomalie est un serpent de mer du domaine du Machine Learning : il englobe un grand nombre de sujets très différents avec des complexités très variables. Un modèle de diffusion offre une approche originale, car permet d’itérer sur différentes versions de la donnée, en la re-projetant dans l’espace “normal” qui a été appris (via les itérations de bruitage ou débruitage). Il est probable que certaines problématiques puissent ainsi être adressées d’une nouvelle manière. Notons qu’un intérêt ici pourrait être de localiser l’anomalie dans l’image d’une manière plus efficace, et d’exposer une distance entre cette anomalie et une “norme” apprise par le modèle.
Le second point est moins scientifique, mais ne doit pas être ignoré. Il y a autant de potentiel d’innovation dans une découverte fondamentale, que dans l’exploration de nouveaux usages. Un simple suivi des expérimentations réalisées avec Stable Diffusion montre de nouvelles approches toutes les semaines. Par exemple, si tout le monde sait que l’on peut générer une image à partir d’un texte, peu savent qu’il est aussi possible de générer une image en définissant les éléments qui doivent apparaître d’une manière globale, via des rectangles de localisation (schéma issu Rombach et al) :
Ou même, via une “esquisse” en aplats colorés :


Dernier exemple en “inpainting”, où nous supprimons une partie de l’image et demandons au modèle de diffusion de régénérer la partie manquante. Celle-ci le sera en respectant le reste de l’image encore visible, produisant une image “crédible” en générant la partie manquante :

Nous sommes donc face à un outil très polymorphe. Qui plus est, le mécanisme de conditionnement (permettant d’apprendre un lien entre input et image générée) est relativement libre et ne demande qu’à être adapté à de nouveaux concepts.
Nous sommes donc face à des outils qui vont au-delà de la simple génération, pour effectuer de la conversion de domaines, avec de nombreuses applications. Face à un type de donnée spécifique modélisant un problème métier ou industriel, nous pouvons cartographier cette donnée et la modifier d’une manière stupéfiante en la conditionnant à une information plus simple.
Concluant sur le dernier point, on observe que les modèles de diffusion arrivent sur de nombreux types de données différents (audio, image, texte, etc.) Nous pouvons donc déjà observer que de nombreux types de signaux plus ou moins complexes pourront connaître le même type d’application.
Hors, la majorité des systèmes industriels proposent un monitoring basé sur de nombreuses sondes, caméras, micros, dont la trop grande complexité est un frein pour des analyses poussées.
Le Deep Learning offre des outils pour réduire cette complexité en minimisant la perte d’informations (les features de haut niveau dans un modèle entraîné). Les modèles de diffusion nous proposent une approche de ce type novatrice. Par exemple, pour qualifier le bruit présent dans un signal, et décider si ce bruit est extérieur au système étudié ou si, à l’inverse, ce bruit est une nouvelle composante traduisant un problème important, les modèles de diffusion pourraient être un outil très pertinent dans la mesure où ils apprennent précisément à bruiter ou débruiter la donnée…
Au-delà, rappelons que ces approches permettent aussi de créer des correspondances entre différents types d’information. C’est en rapprochant un apprentissage sur le texte et un apprentissage sur les images qu’OpenAI avait créé DALL-E. On peut donc espérer disposer d’outils permettant de convertir une information en une autre, par exemple, en transformant un signal temporel de bon fonctionnement mécanique vers un texte explicatif de ce bon fonctionnement. À ce stade, il est grand temps d’expérimenter en attendant de pied ferme les prochains travaux scientifiques.
Évidemment, nous surveillons à Kickmaker ces sujets avec attention, et expérimentons déjà afin de pouvoir demain vous proposer les meilleures solutions possibles, alliant la qualité d’innovation de ces travaux à notre rigueur d’implémentation en ingénierie. En effet, au-delà de la révolution scientifique, notre défi est de transformer ces essais en outils exploitables et contrôlables. Suivez-nous, et si vous désirez aller un peu plus loin, parlons-en! 2023 sera une année exceptionnelle en suivant ces opportunités d’application.
Article écrit par Eric Debeir, lead data scientist