Pourquoi lire cette publication peut vous être concrètement utile ?
The subject of edge AI is still in the wilderness, with real difficulty in deploying neural networks correctly. The arrival of a self-sufficient, anonymity-preserving camera is an event not to be underestimated, especially as the approaching freeform Pixel is particularly clever. The Imitation Learning had already heralded a revolution in robotics by making model training much simpler. Deepmind extends these approaches with astounding results in robotics, industrializing the notion of demonstrations. Another, sadder point: the main tool we had for “interpreting” a neural network acting on images was violently cancelled by Deepmind. We’ll never forget this tool, which will remain forever in our hearts.
If you only have a minute to devote to reading now, here's the essential content in a nutshell
- The best publication of the recent ECCV 2024 proposes an innovative approach to creating vision-based AI solutions that are notably very energy-efficient.
- These solutions naturally anonymize the data, and the authors go so far as to propose a prototype hardware on non-trivial problems such as people counting or speed measurement.
- Imitation Learning We talked about it 6 months ago, and the subject is exploding. Deepmind has seized upon it, training a robot to perform complex actions, including manipulating soft objects such as shirts (a roboticist’s nightmare).
- Beyond the feat, Deepmind has industrialized the process of recording demonstrations with non-expert players, and this approach can easily be extended to many other subjects.
- Using a still image to automatically detect objects, and then simulate a physically credible movement in the image, is a recent success story.
- Point of interest: AI is used here only to detect elements, and a “real” physics engine then acts to generate movement
- Last but not least: the feature visualizationwhich was one of our last valid cartridges in vision model interpretation, has been mathematically shot down by Deepmind as part of the ICML 2024.
Freeform pixels and self-sufficient cameras respect anonymity.
Let’s be honest. The mention of “pixels” learned by artificial intelligence, which would enable the creation of new types of energy self-sufficient cameras, will above all invoke the deepest doubt. And yet, this publication by Columbiawhich received the best paper award “ECCV2024 conference, is a serious and exciting piece of work. Because artificial intelligence goes (thank goodness) far beyond Large Language Modelsthis work deserves careful study.
Indeed, we suffer a lot from these trees that hide the forest: work in Deep Learning work is often very heavy, involving gigantic models (known as “Frontier Models”). Frontier Models “In this case, the authors go against this trend, taking a minimalist approach to tackling fairly conventional vision problems: counting the number of people in a room, the speed at which a vehicle crosses a street. Here, the authors go against this trend, seeking a minimalist approach to tackling fairly classic vision problems: counting the number of people in a room, the speed at which a vehicle crosses the road, and so on. The revolution here lies in the extreme simplicity of the approach, and we’re going to see how such problems can be solved with just four tiny pixels (this last statement is a bit of a play on words, but that’s precisely the point here). Below, an example of the people counting system, with a 24-pixel sensor:
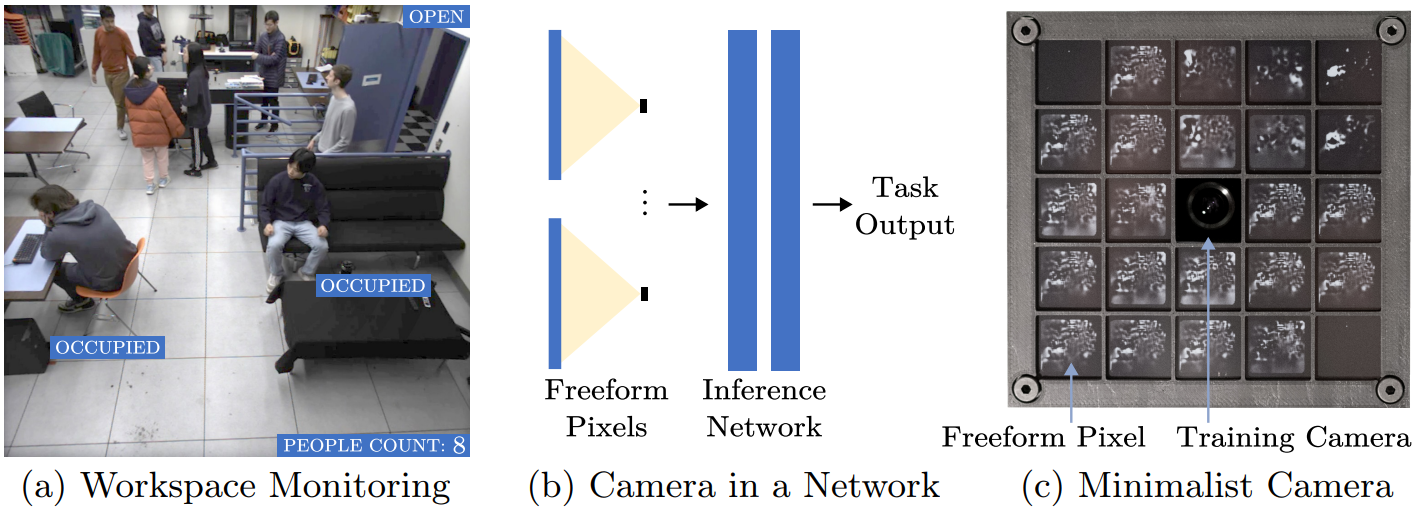
Attention Please note: this work is fascinating, but gives very few elements of reproduction, so a minimum of mistrust is in order…
But let’s get down to business: what is a “freeform pixel”? freeform pixel ” ? The authors’ idea is to model a new form of sensor which, in order to model the value of a pixel (i.e. a simple intensity value), will not perceive light passing through a tiny point ( pinhole), but will instead receive all the light information from the scene. An important detail: this light information will pass through a two-dimensional mask that will attenuate, or even suppress, the light received at certain points. Note that this mask is, below, a binary mask, but that in absolute terms it can take any value between 0 and 1.
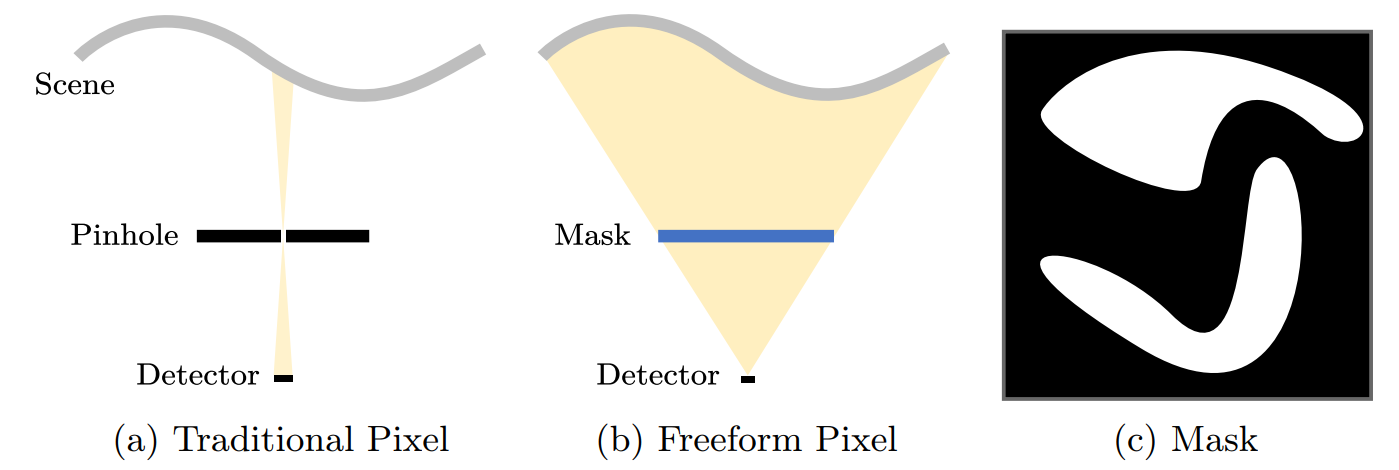
So we’ll have a system based on a set of these pixels. Each pixel will have a mask that will be trained against a video stream used as a training set. The value of each pixel will then be used to feed a specific neural network (below : inference network), which will return the desired supervised value. It should be noted that an important argument arises in anonymization: such a system, exploiting a few dozen pixels, will de facto anonymize the input image, as it cannot retain enough information to be able to reconstruct a face or a person in the image. At least, that’s what the authors claim – a credible assertion, but one yet to be definitively confirmed.
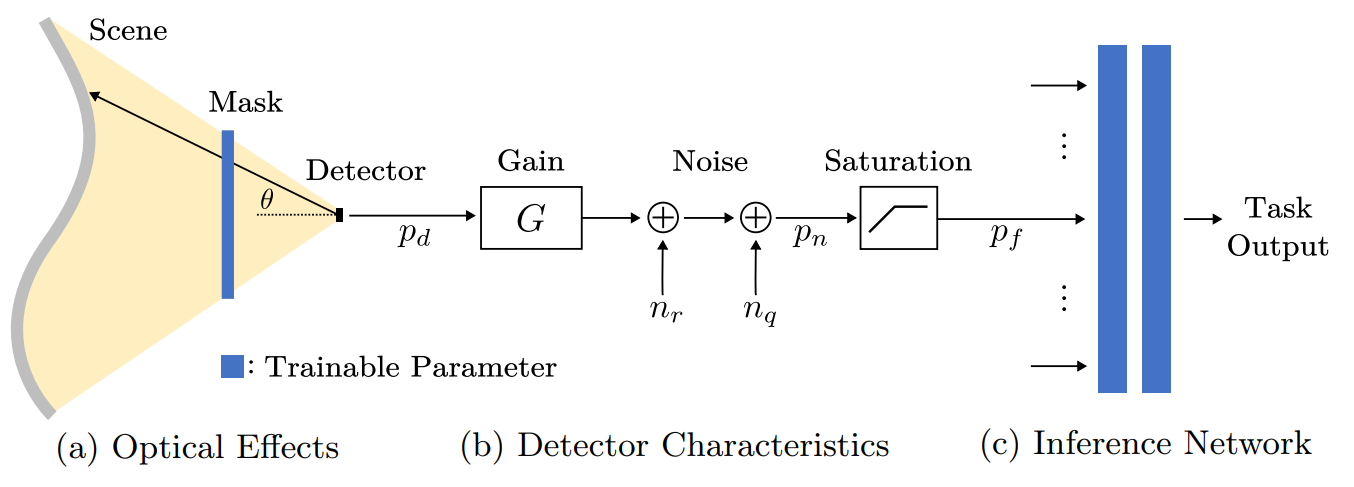
But, but, but… Does it work? The researchers began by working on a simplistic test case, but then went on to create a prototype of the “camera” needed for different problems. The prototype consists of a set of pixels, each with a printed mask resulting from the model’s training. One hour of video is used to train the model. Each of these pixels transmits its value via amplification to a microcontroller, which interacts by bluetooth with an external peripheral. The system is also covered by solar panels, enabling it to be self-powered even in indoor environments. The camera application can be changed by printing new masks for each pixel.

And we can see two interesting applications below. The first involves counting the number of people in a room, the second detecting the speed of vehicles. In each case, we can see a graph of performance as a function of the number of “pixels”, compared with a “pixel”. baseline which uses classic pixels (and is, let’s be honest, not very interesting). We also see the masks learned by freeform pixelswhich divide up the space ad-hoc to the problem being addressed, and (in the first case) a table of raw results :

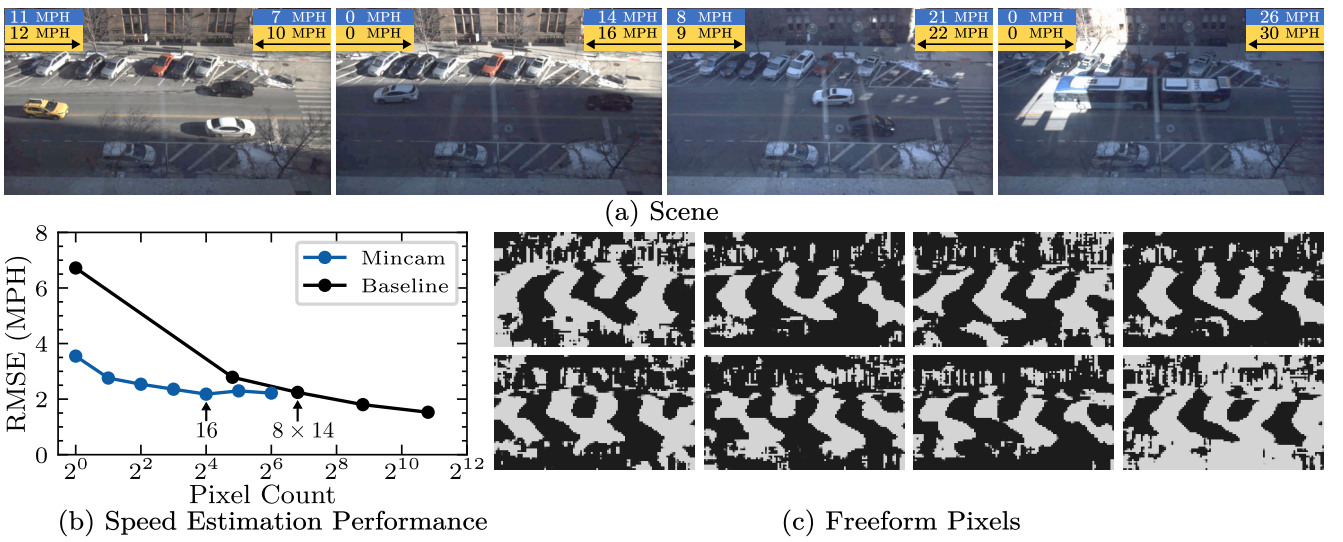
In conclusion, this work deserves to be followed with great attention. We are working on a new Edge ComputingIn a context where the energy expended by these models is an irritating subject. Here, by going as far as the hardware prototype, the researchers at Columbia offer an efficient, scalable solution, with strong input image anonymization…
ALOHA unleashed: robots know how to fold a shirt
(And that’s quite a feat, but let’s put it in order)
Those who follow our research reviews won’t have missed an article published in March 2024 onImitation Learning. As a reminder, last year this field began to revolutionize robotics and artificial intelligence, specifically the field of Deep Reinforcement Learning. This field consists in training an agent to solve a task by maximizing a reward modeling the agent’s success. And while this field has had many moments of glory (in robotic manipulation, or via AlphaGo / AlphaGoZero), it had always suffered from an enormous training burden. This led to a number of projects that could train a robot using demonstrations recorded by humans. Two works were featured in our last review: the Diffusion Policies (which we were happy to reproduce) and ALOHA.
Today, it’s Deepmind who returns to this section with direct inspiration from these last two works. ALOHA Unleashed is a work that deserves attention, beyond mere technical achievement.
Indeed, as the authors point out, previous work was impressive in terms of its effectiveness (training of a few hours for a simple grasping robotics), but were very limited in their applications. Here, the challenge posed by Deepmind is about two-armed manipulation of deformable objects (like a shirt), a terrifying subject for any self-respecting roboticist. Indeed, manipulating rigid objects is already not very trivial, so manipulating an object whose shape will change radically according to the movements applied is an incredible technical challenge. Some examples below (with other cases such as very precise manipulation):

Note that these actions can be a succession of complex actions, such as hanging a shirt on a hanger (warning: these images may shock robotics engineers):

As we shall see, this work combines a number of factors to achieve these results, including the need to multiply the number of demonstrations recorded by humans, and the prohibitive cost of training…
The architecture used is described below. There are several points of interest:
- Four cameras capture images. These images are encoded by ad-hoc networks, in this case convolutional networks of the type Resnet50. Note that the use of convolutional models is interesting here, as opposed to the ” Vision Transform everywhere “. This approach was also favored in the Diffusion Policies.
- Proprioception is encoded by a multilayer perceptron classic
- These representations are used as inputs for a Transformer to generate a global representation of the scene at time t
- Finally, the robot control actions will come from the decoder, via a broadcast approach (iterative denoising). 50 passes are required to generate the next actions to be generated.
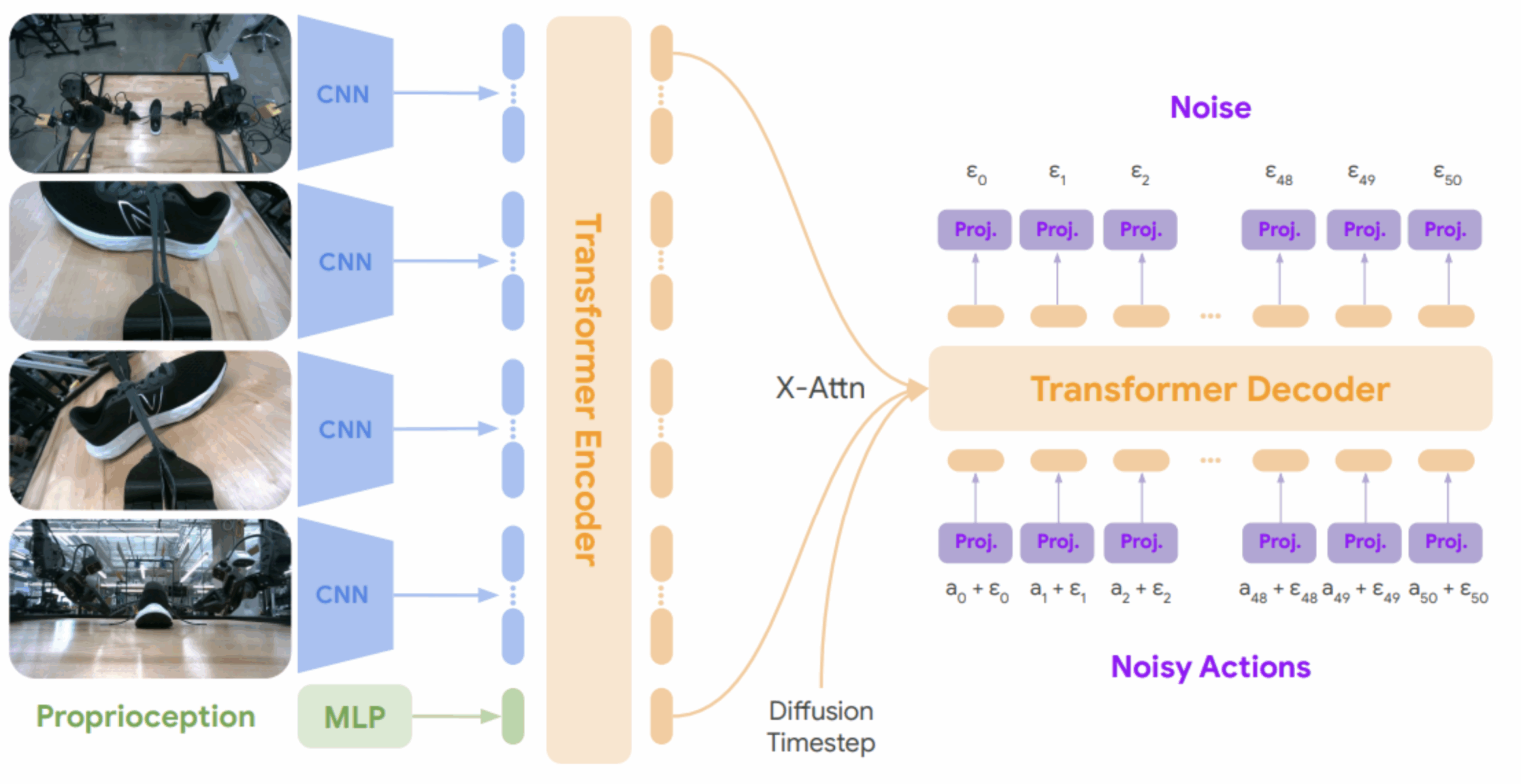
To go into the essential details, we’re here (unlike previous approaches) on a very heavy workout. Based on the framework JAXframework, the drive uses 64 TPUv5e for 265 hours. If we want to reproduce it, it’s a small budget of 500k€… ( Note: if this budget for a single training session is acceptable to you, contact us – we’d love to talk to you!)
But let’s not stop there and look at another important aspect of Deepmind the multiplication of demonstrations. Indeed, following the unglamorous but true adage that more data is always better, the authors have industrialized the recording of demonstrations by non-expert actors. A total of 26,000 demonstrations were recorded for the 5 tasks. Note that a protocol has been set up so that non-expert users can interact with the system correctly (you can consult an example protocol at this address ). And this is a point worth studying.
Being able to retrieve many demonstrations on a task and then use them together is still a complex topic in Deep Learning. Nevertheless, the accumulation of such information can be projected into many business areas, where technical experts perform a complex business gesture. By replicating this type of protocol, it becomes conceivable through a Imitation Learning then generate a model to confront the target subject. We’re getting into a collective intelligence approach, so stay tuned.
PhysGEN: modeling physical forces from an image
A short video to introduce the subject 😊
In our webinar last July about GameGENwhich generates a two-dimensional video game from a static image. Here, the subject is quite similar and was the focus of ECCV 2024. Starting from a static image with a background (background) and objects in the foreground, the system will be able to detect elements that can move and assign them an initial force, then observe the resulting movement in a video. The rendering quality is quite impressive, but beware, you who enter here wanting to dream of Generative AI! The work presented here fundamentally works because it minimizes artificial intelligence where it is strictly necessary – an unavoidable condition for success if you want a functional result.
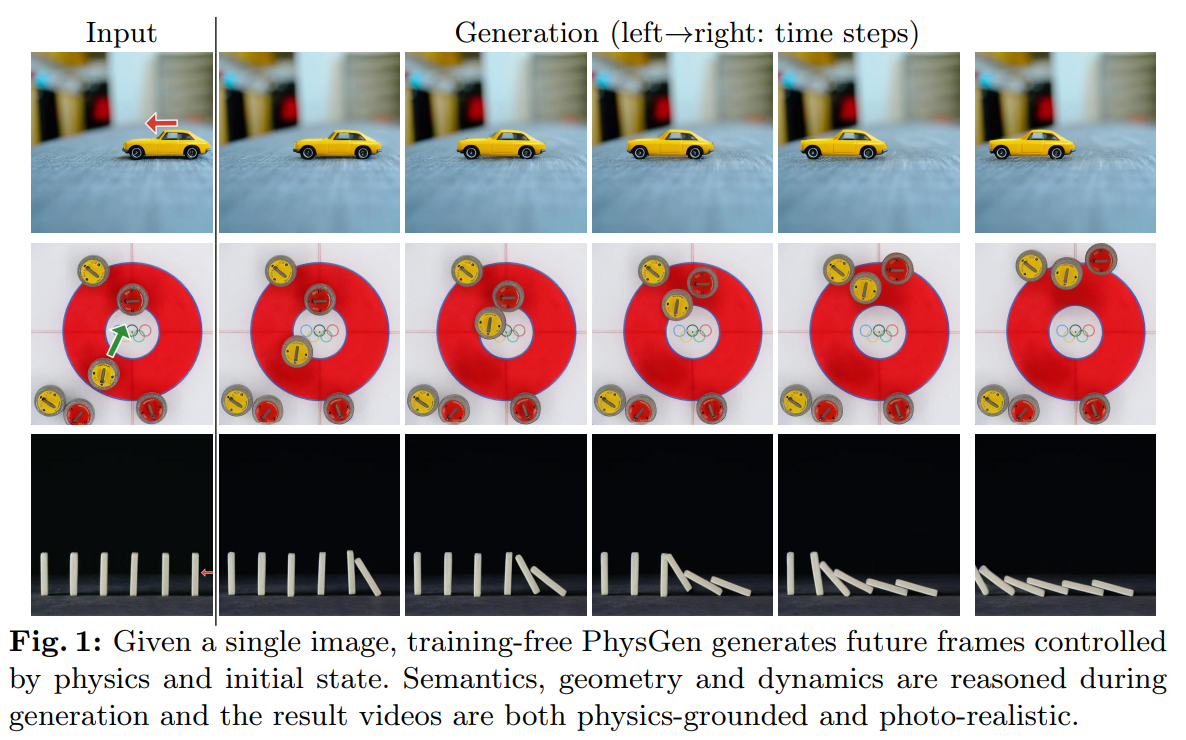
Let’s go into more detail and study the method used:
- From the still image, the first challenge is to identify the relevant elements, in particular to distinguish the background (with potential collision-causing elements) from foreground elements, which may receive an initial force or react to the collision of another element. Two different models are used for this purpose: GPT4V to categorize objects and generate physical information, and GroundedSam to delimit these elements correctly. Note that GPT4V may be a perfect hallucination here, but let’s face it, few cross-modal models can match its quality to date.
- Once the elements have been defined, we’ll need to calculate the movement of each element. No artificial intelligence here, and that’s good news! A classical differential equation approach is used to generate the movements.
- Once this movement has been achieved, improvements to the generated images will be applied, before moving on to a diffusion model generating images that are aesthetically more pleasing over time.
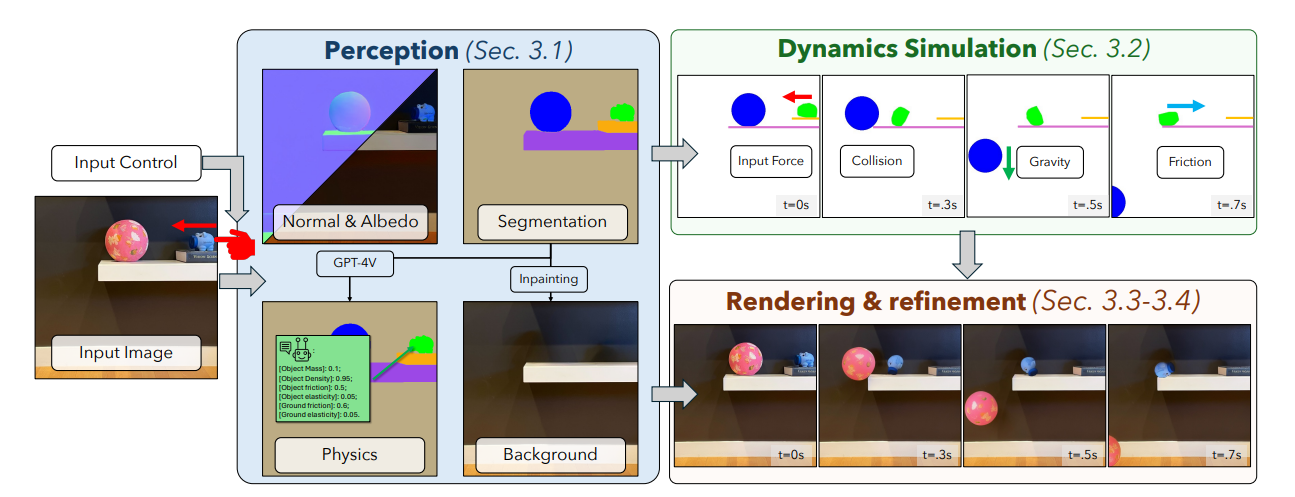
In conclusion, this work is particularly interesting in its combination of classical methods (dynamic simulation) and AI (input feature detection, output image enhancement). Remember that a phase without AI is a secure and controlled phase. 😊 And this type of approach can be similar to that used in digital twins, where artificial intelligence is used to initialize the simulator and then let it do its job properly.
(Very) bad news: feature visualization doesn't work
Small apocalypse: already, the interpretability techniques of Deep Learning are based on a hobbled hand generated by a diffusion model, now the main technique we know is violently invalidated by Deepmind. The price of working in an innovative field like artificial intelligence, you might say, and we can only agree dutifully.
What are we talking about? Deepmind has dropped a bombshell at the ICML 2024 via the publication ” Don’t trust your eyes: on the (un)reliability of feature visualizations, Geirhos et al. “. This publication looks back at the” feature visualization “a central interpretability technique that we’ll have told you about if you’ve taken one of our training courses. 😊. This technique, dedicated to image-based AI models, identifies the activity of a “neuron” in the model via an image representing that neuron. A small example from the ” Lucid “ says it all:
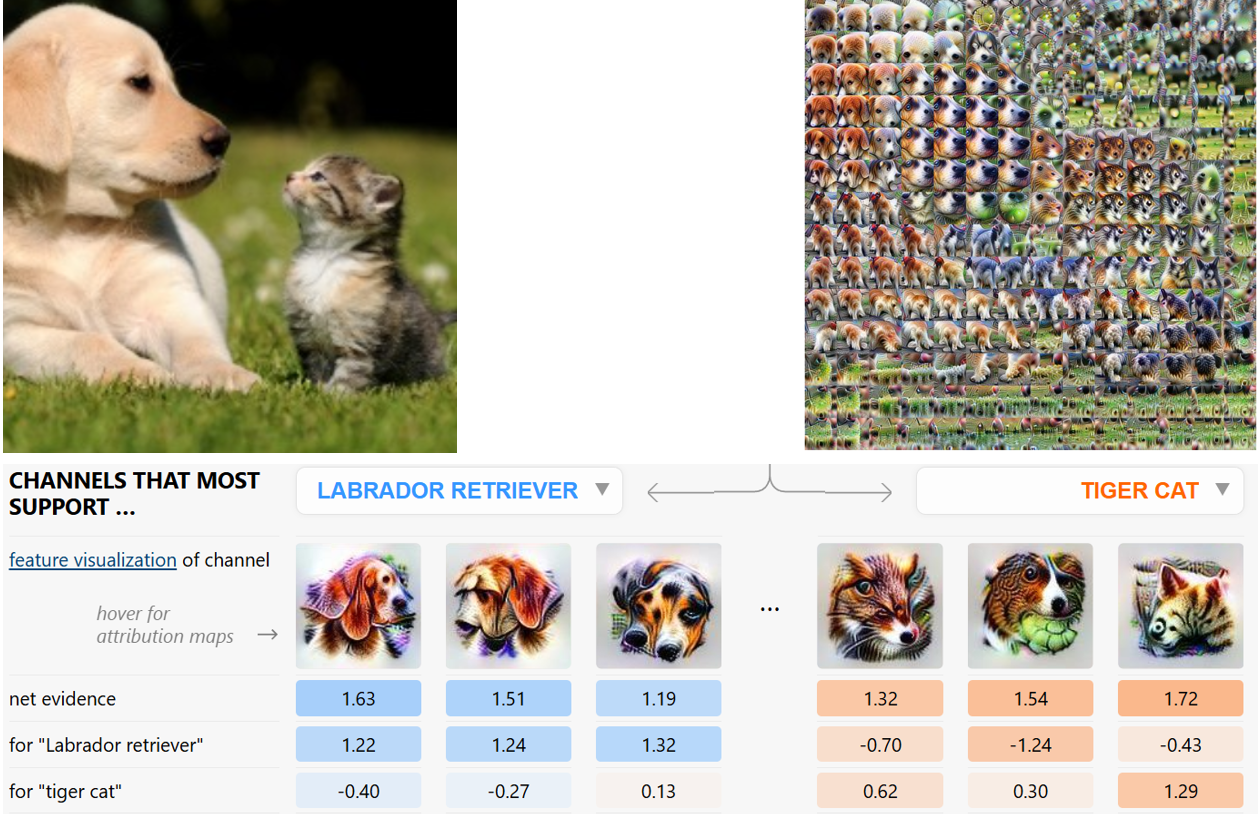
Above:
- Top left, input image
- Top right: the image as “seen” inside the neural network. Each square is precisely one feature visualization of the intermediate pixel.
- Below: main predictions and feature visualizations of neurons contributing most to predictions
This technique has been in use from 2017 to the present day, and was considered one of the few “valid” techniques. But were these visualizations really effective, or was it because there was no credible competitor that we settled for them? The answer here is unpleasant.
Indeed, researchers at Deepmind are already trying to see if it’s possible to actively make one of these visualizations lie. The idea is to force arbitrary visualizations on an equal model, and to prove that the output information can be totally uncorrelated with the reality of what a neuron is doing. Here, the authors introduce “silent” units into the model that will disrupt the visualization. Note that this is a case of malicious action, where an attacker would deliberately lie about these observations:

The visualizations on the left are “normal”. Those on the right are of the same network, but manipulated, and we have to admit that interpretability won’t get very far.
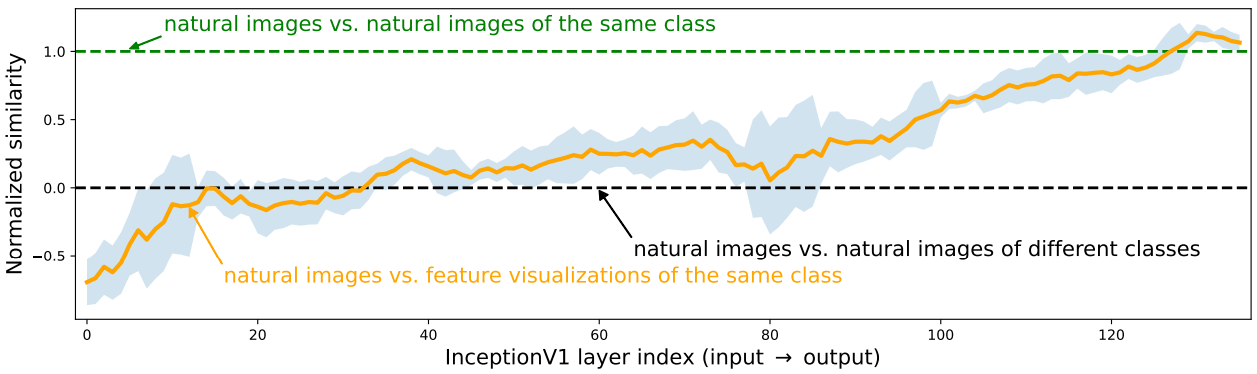
Taking an approach that is no longer “malicious”, but focuses on the reliability of these visualizations, the authors have carried out a comparison of the extent to which these feature visualizations can represent certain classes of images. The diagram below shows that in the first layers, the representation of an image of a crocodile, for example, will be as close to other images of crocodiles as to images of flowers or cars, for example. Things improve towards the end of the network, with better discrimination, but these results already show that visualization on the first layers makes little sense in terms of discrimination:
But the real result is mathematical, and raises the question of interpretability. featuressuccessively :
- Predict the result of a model from an input?
- Predict this result with limited noise?
- Predict this result by estimating the minimum and maximum?
The answer, as demonstrated here, is negative. In the majority of cases, these techniques will not be able to answer these questions correctly, thus cordially invalidating the approach.