Pourquoi lire cette publication peut vous être concrètement utile ?
A better understanding of what neural networks learn is fundamental to our field of work, and here we have a relevant (if somewhat ambitious) publication showing that these representations are similar across architectures and modalities. Beyond this, new work is enabling us to process very high-resolution images with controlled memory consumption, opening up new applications.
Last but not least, two works provide a better understanding of diffusion models and architecture complexity, with new results on the now famous Mamba
Quels process métier seront probablement modifiés sur la base de ces recherches ?
The Foundation Models aim to learn generic representations through one or more modalities (text, image, sound, etc.). The fact that these representations are naturally similar makes it easier to envisage their use. Another issue is that the use of AI on very high-resolution images is currently blocked, making it impossible to interpret complex images correctly (satellite images, for example). Last but not least, diffusion models are increasingly emerging as an effective tool for modeling an environment and its dynamics. world models to continue positioning themselves as an effective and interesting tool for training autonomous agents.
If you only have a minute to devote to reading now, here's the essential content in a nutshell
- Researchers have observed that the intermediate representations learned by different neural networks are much closer to each other than might be expected, suggesting a “convergence” of these representations towards a general model. This convergence can be observed across models, but also across different modalities: text, image, etc. The more complex the models, the more important this alignment becomes.
- And now something completely different The management of very high-resolution images is still a thorn in the side of researchers, who are obliged to cut or degrade these images in order to work on them. However, these techniques potentially destroy the image’s global context information, which is indispensable in certain scenarios. Here, the authors propose an interesting generic approach that is stable in memory occupancy and can handle very large images. This approach is also an opportunity to test the Mamba on these issues.
- Another topic is world models are a technique for learning to model an environment and then training an autonomous agent to deal with this “virtual” environment. A new work exploits diffusion models to obtain a new state of the art. This work clarifies our understanding of diffusion models, in particular to verify the relevance of the approach recommended by NVIDIAbut also to compare their capabilities with other models such as the VA-VAE.
Finally, a study of the complexity of architectures Transform and Mamba to observe theoretical and fundamental limits in monitoring the state of a simple system (e.g. a chess set). In particular, it enables us to better characterize the fundamental capacity of an architecture.
Platonic" representation: Do neural networks learn the same representation of reality?
Attention, the publication The Platonic Representation Hypothesis, Huh et al. is to be handled with a grain of salt. While it poses some fundamental questions and raises some fascinating observations about what our beloved neural networks are learning, it’s important to separate scientific assertions from more philosophical speculations. But let’s not get ahead of ourselves, and put things into context: what are we talking about?
It’s been almost ten years since a fundamental research trend emerged in our field of Deep Learningthat of Representation Learning. The basis of this work is an observation: when a neural network learns to address a task (e.g. classification), it implicitly learns to represent the input data in increasingly simpler forms (i.e. with much lower dimensionality). Today, this learning process is probably the real “magic” of the Deep Learning learning to represent extremely complex data in a simplified form that is easier to handle. This is what Milokov et al who generated the first embeddings representing words. This trend then continued with the training of Foundation Models like our invaluable DinoV2which can represent an image with a highly expressive vector, sufficient to address a large number of specific tasks. We also did a webinar on the phenomenon of embeddings cross-modality, where the same concept presented in two forms (for example, image and text) is isolated as a single representation vector.
Nevertheless, if each neural network learns a representation of the input data, a fundamental question is how close two representations from two different neural networks will be. Put another way: Does each network learn a unique and specific representation during its learning, or is there a representation “destination” towards which each network undergoing learning would move? To return to the authors’ vision and their main hypothesis: Is there a single representation towards which neural network representations naturally tend?
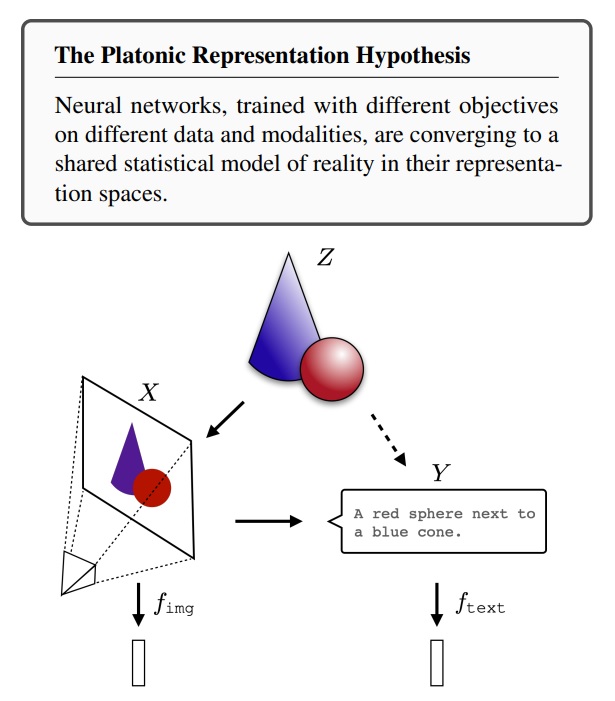
This work is a welcome opportunity to take stock of what the scientific community has discovered on this subject. A number of observations have been made in recent years. Typically, using the model stitchingwe already know that it’s possible, from two networks trained on the same problem, to extract n first layers from one and p This already implies that two such networks learn extremely similar representations (apart from one linear transformation). This already implies that two such networks learn extremely similar representations (apart from one linear transformation). This type of transfer between two networks has been pursued to the point of achieving “zero shot” methods (without any specific relearning) and, more particularly, between different architectures and even different problems to be addressed. This versatility is already interesting, especially in our field where theoretical deficits continue to limit our understanding. The authors therefore studied the extent to which two different models, trained on different problems, have similar internal representations. To do this, the logic was to compare, between the two representations, the nearest neighbors of the same element and observe whether these groups of neighbors are close or different. While not absolute, this approach has the merit of minimizing the problems of metrics which, when faced with fairly complex vectors, can quickly lose their meaning. A first interesting result shows, through 78 different image classification models, and therefore through very different architectures, the extent to which these models are “aligned” in their representations. On the left, we can see that the better these models perform on the VTAB (Visual Task Adaptation Benchmark), the closer their representations are. On the right, a dimension reduction ( UMAP) projects these models in two dimensions:
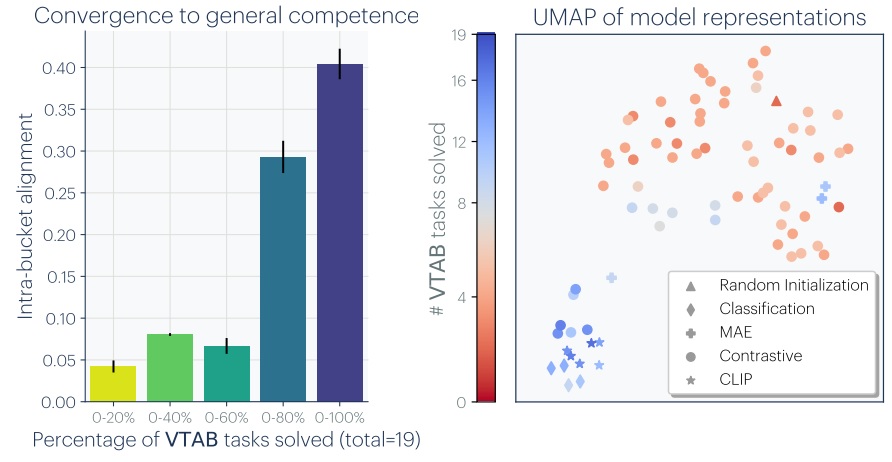
This idea that inter-model alignment improves with performance is a very interesting point. Beyond this, the authors assert that these representations converge across different data modalities. We already knew that it was possible to “glue” a vision model and a language model at the cost of a linear transformation. Here, the authors observe a more global alignment between vision models and language models, with the more powerful the language model, the greater the alignment. The authors also observe that CLIP d’OpenAIwhich is also trained on textual content, has a higher degree of alignment, which deteriorates as soon as a fine tuning to ImageNet.
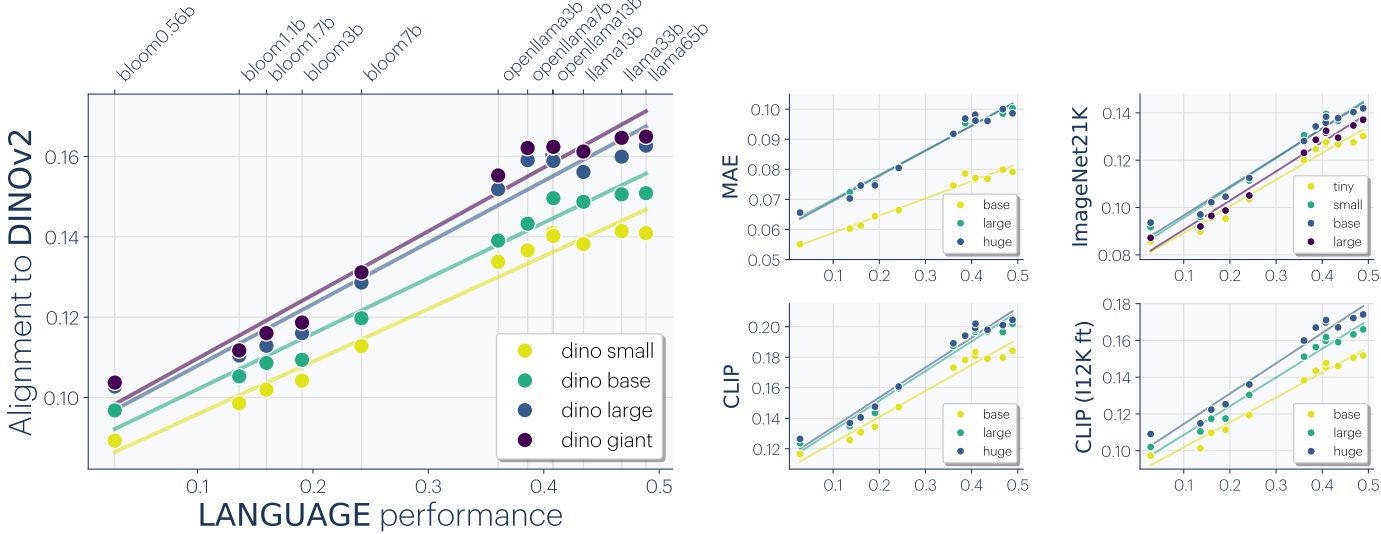
Last relevant experiment: the authors compare the correlation between alignment of a language model with the vision model DinoV2 and performance on specific language tasks. Hellaswag shows a relatively linear correlation, while GSM8k shows (visually, mind you!) a form of emergence.
This work is of remarkable interest, as the question of the representations learned by a neural network is a fundamental one linked to the interpretability and our understanding of these models. Here, there’s something very reassuring about observing that these representations “come closer” as a function of model complexity. Faced with the intellectual chaos of Deep LearningThe idea that our models learn more or less well a “universal” representation of information, through text or image, is very good news. However, we must also be wary of rushing into things too quickly. The authors’ Platonic hypothesis is, precisely, a hypothesis. And while the authors speak of convergence of representations (a term that tickles the mathematical vocabulary), we’re just observing a correlation. What’s more, these representation vectors may be a simplified version of the input data, but they’re still very complex (vectors of dimension 500, 1000…) and each comparison method (in this case, nearest neighbors) has its qualities and shortcomings, without imposing itself definitively over the (many) other methods. That said, this direction of research is particularly important, especially in the age of Foundation Modelsa subject to keep a very close eye on.
Very high-resolution images: the Achilles heel of Deep Learning
This point is well known to all practitioners who have developed Deep Learning architectures at Computer Vision The vast majority of existing models are fundamentally incapable of handling a high-resolution image. For example, a 4K quality image (approx. 8 million pixels) will not naturally be processed in a single block by a conventional neural network. This image will have to be either resized or cropped, so as to fit within the input resolutions of the models.
This is the subject addressed by xT: Nested Tokenization for Larger Context in Large Images by Gupta et al. The stakes are high. Being able to process a high-resolution image makes it possible to correctly qualify a subject according to its entire context. For example, I’m unlikely to understand the behavior of a footballer if I can’t see all the other players in an image that’s precise enough to observe their poses. Similarly, if you’re working with satellite imagery, detecting a small feature can be complex enough, but the context of that feature plays an important role. This problem is illustrated in the diagram below:
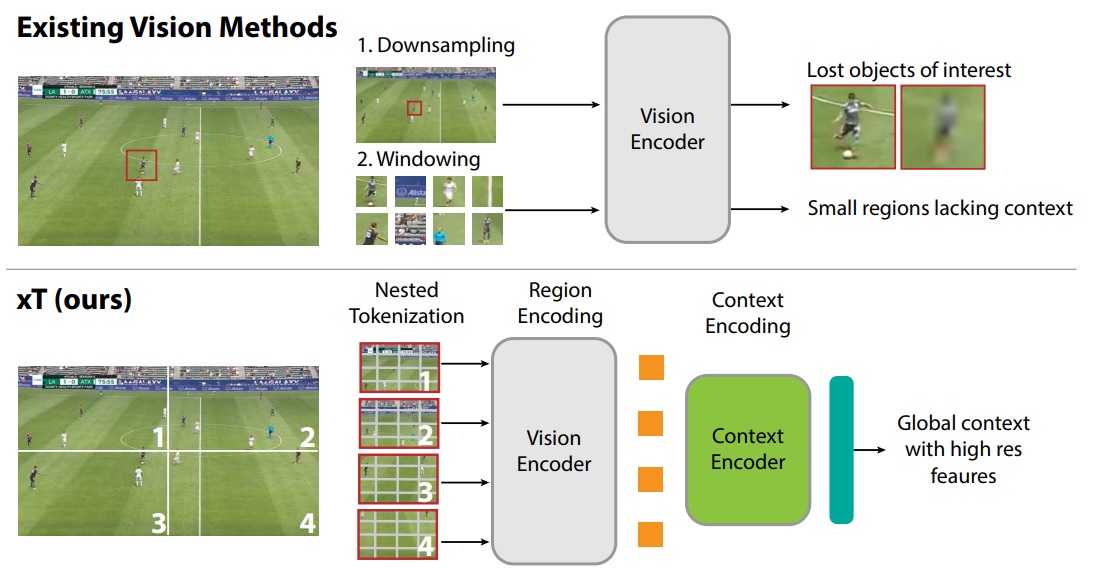
The fundamental problem is, of course, one of available resources. The complexity inherent in the internal processing of a neural network (whatever the architecture) is such that most of these tools take input resolutions of around 500 pixels, and already occupy a substantial amount of memory space. The issue is therefore one of architecture, and we’ll see that this approach raises some interesting questions. Shown in the diagram below, the xT will already split the image into patches and sub-patches (Nested Tokenization). Each patch will be encoded using a neural network to represent the patch (we were talking about representations earlier 😊). This encoding will be independent for each patch, and will simplify image representation. So that the model can use each patch and therefore the entire context, the third part will consist of a Context-Aware Encoding which will receive the encoding for each patch and, finally, a final prediction based on the problem addressed via a decoder decoder.

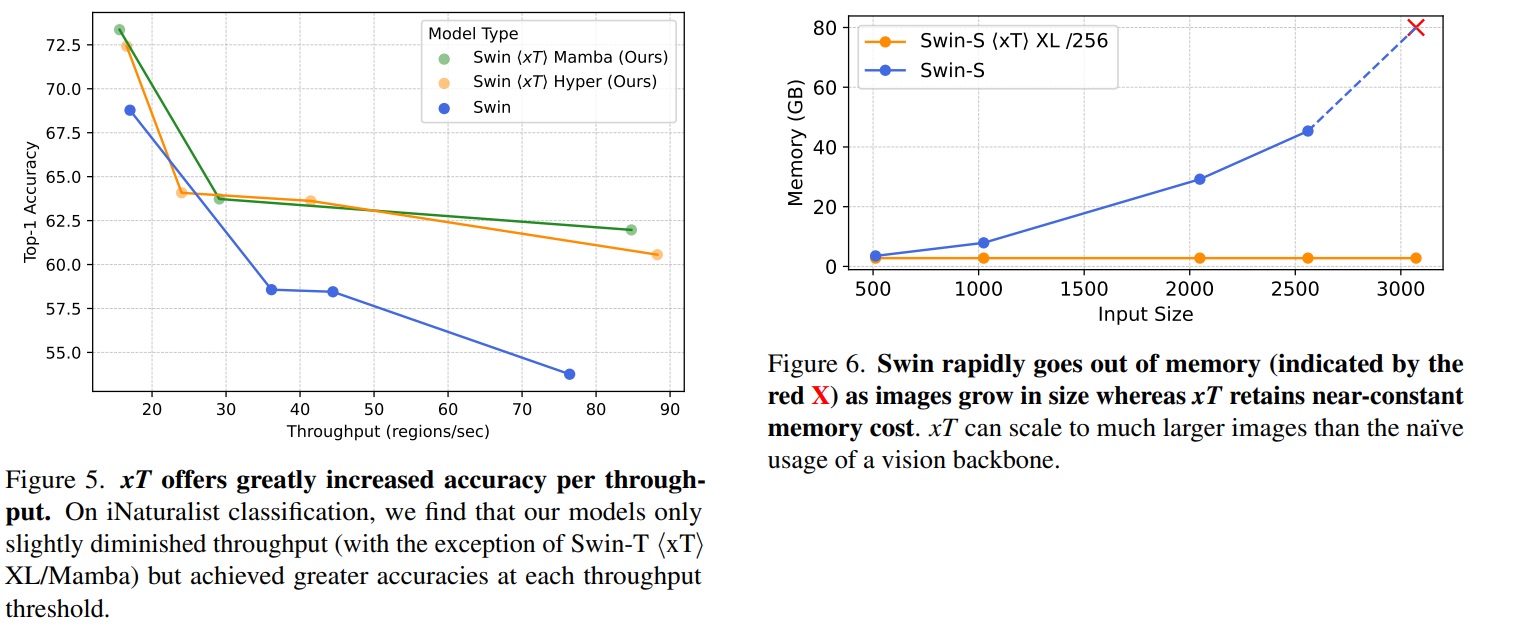
The results are interesting for two reasons. Firstly, the authors tackle the issue of dataset iNaturalist xView3-SARThis is a very high-resolution satellite image (29400×24400 pixels), where features are highly dependent on a global image context. But beyond that, the authors test the dataset iNaturalist dataset and various types of Context-Aware Encoding. One of the types tested was good old Mamba. If you don’t know what we’re talking about, feel free to have a look at the research review dedicated to this architecture, which has been the talk of the town for several months, offering an efficient and more memory-efficient selection mechanism. This architecture is a relevant choice here, and without standing out totally, it often presents final scores that are competitive with or better than the Transform.
Another argument concerns the efficiency of this method. The authors measure the final accuracy obtained as a function of execution speed (here in terms of the number of regions processed per second). Here, the efficiency of this approach is much more interesting for the same quality (left). In the second diagram on the right, the approach occupies a constant memory resource despite the input resolution, where conventional models stalled and could no longer respond.
These approaches remain very important since the problem raised (impossibility of managing an image with too high a resolution) is a constant challenge for applying Deep Learning to the design of effective tools. To date, these subjects have been addressed by slicing the image and then applying specific heuristics, and while these approaches are likely to prevail for some time to come, the ability of a model to address high resolution is a major issue in moving towards more efficient tools, particularly when it comes to learning them.
World models & diffusion: a quick update
Visit World Models are a research topic created in 2018 by the famous Ha and Schmidhuber which revolutionized reinforcement approaches, i.e. those where we want to train an autonomous agent to maximize an arbitrary reward in an environment. These approaches are widely used in robotics, but more generally to solve optimization problems. At the time World Models had been a huge breath of fresh air. Previously, this field had been trying to train a single neural network under horrific conditions (anyone who has trained these models, whether you call them Q Learning or Policy Gradienthas shown a strong post-traumatic syndrome in the face of reward curves and a GPUwhich was perfectly readable but depressing). One problem was the desire to drive a single network. Visit World Models have proposed a much more structured approach, based on three successive stages:
- The training of a model responsible for compressing and mapping the agent’s observations in its environment (at the time, a good old-fashioned Variational Autoencoder)
- Training a model to model the dynamics of the environment (what happens if you perform a given action in a given state), this model working only on the vectors derived from the first model.
- Finally, the development of a controller that will use the first two models to solve the overall problem.
This division allows the right questions to be asked in an iterative way, and thus the subjects to be better distributed. And the authors, at the time, had achieved the feat of using the first two models as a virtual environment, training an agent solely in this virtual environment, and finally using it in the real environment.
These World Models are therefore designed to “simulate the world”, or at least the working environment. They are thus very close to the “universal simulator” work presented last month in the magazine. We’re following this approach very closely, and have watched with great interest the recent Diffusion for World Modeling: Visual Details Matter in Atari d’Alonso et al. Continuing the work in this field, this approach questioned the architecture used to “model” the environment, and today we’re back to our good old diffusion models! The very ones that revolutionized generative AI in images, and which we were talking about just last month. While these models are indeed very powerful, they are still poorly understood, and any feedback is of great interest.
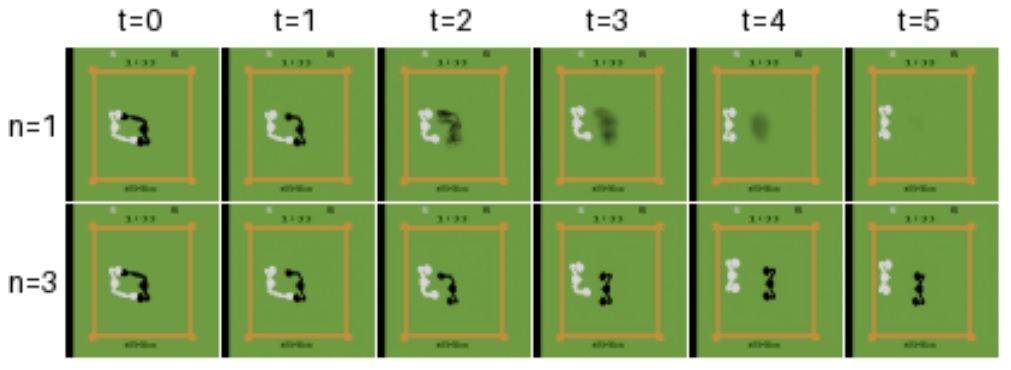
A notable point here is that the authors question the most effective method for training a diffusion model. In particular, they observe that the EDMpopularized by NVIDIAis much more effective at accurately simulating the visual evolution of an Atari game. The value n below corresponds to the number of denoising of the diffusion model. Quality evolves with the number of steps.

Here, the diffusion model plays a role in “predicting the future” of the environment. This publication is thus remarkable for assessing the accuracy of these predictions, and in particular the importance of the number of steps on the quality of the generation (below).
Another point of interest is that this article provides an opportunity to compare diffusion models with another architecture widely used for these visual modeling problems: the VQ-VAE which, since the 2019 hierarchical version, has taken up the torch in image modeling (the Stable Diffusion of Rombach et al is based on a VQ-VAE to transform the image into a vector, which was then subjected to the diffusion process). Below, on the left, a world model based on the VQ-VAE and on the right the broadcast model version. The VQ-VAE (see below: IRIS) shows inconsistencies (in the white squares) not present in the broadcast version:
- Top line: game Asterix An enemy (orange) becomes a reward (red), then alternates between these two states.
- Middle line: game Breakout inconsistency between the score estimated by the model and the bricks destroyed.
- Bottom line: game Road Runner rewards (small blue dots) appear and disappear
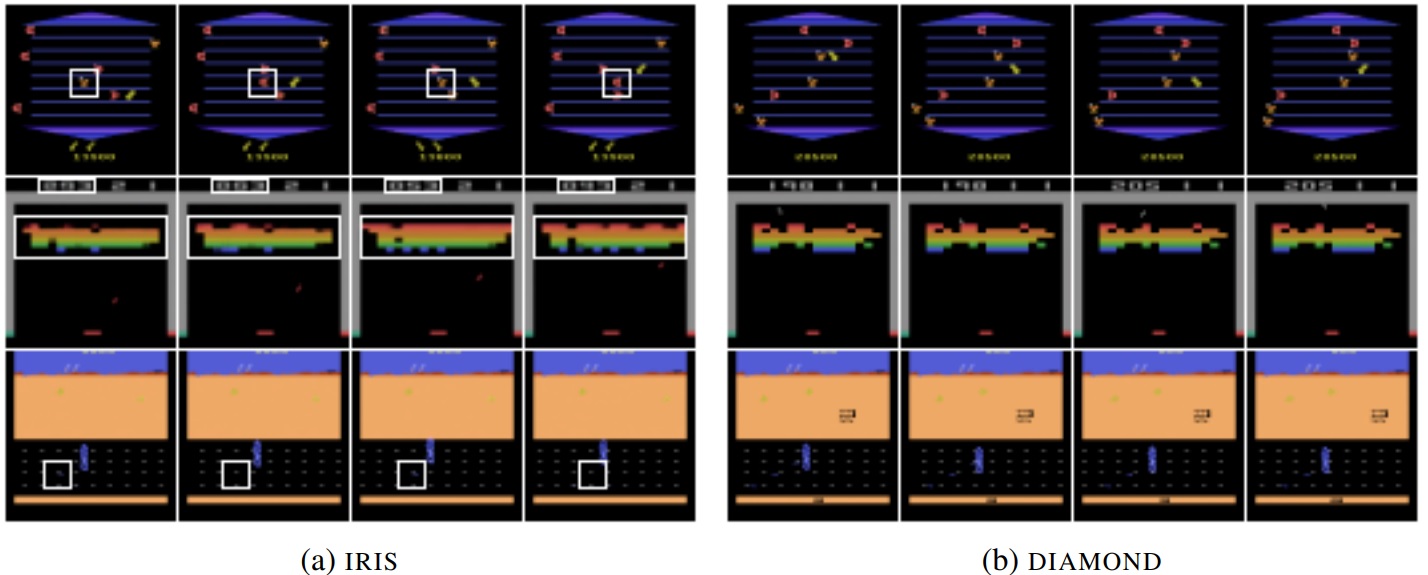
This shows that for modelling internal dynamics, the diffusion model seems to be much more accurate than the VQ-VAEThis makes these models even more useful for generalizing mechanics and behaviors. In a recent review of research devoted to the Imitation Learning in robotics, diffusion models (which we were able to test and validate) were surprisingly excellent for modeling the control of a robotic arm …
Let's talk about Mamba again!
A few months ago, we brought you a research review dedicated to a new architecture that had caused quite a stir in the scientific community: the Mambathe result of structured space models. This architecture boasted a singularly interesting selection mechanism, potentially robust to very long sequences, constituting a huge Achilles’ heel of the Transformers that underpin our cherished language models. Even then, if we drew attention to this work, we urgently recommended waiting to see how the scientific community would reproduce and criticize it.
We have seen below an approach using the Mamba to handle very high-resolution images. The work we highlight here raises the question of these architectures to calculate the state of a system through a long sequence, with a rather provocative title: The Illusion of State in State-Space Modelsby Merrill et al.
An illusion? Visit Mamba already in the garbage can? no, no, no 😊. This publication raises some very interesting questions that go beyond this simple architecture, without invalidating the use of this model.
The central question here is whether the Mamba architecture is more effective than Transformers for monitoring system status. Before going into detail, let’s look at a few examples. A state tracking problem ( state tracking if you have sunglasses) is a problem where the model receives a list of modifications to the state of a system, and must finally provide the final state. Typically, let’s imagine that I have 5 balls placed from 1 to 5, and that I then have a series of instructions of the type: swap ball 3 and ball 2, swap 1 and 4, swap 2 and 5, etc. The challenge is, at the end of the sequence, to be able to give the final position. The challenge is, at the end of the sequence, to be able to give the final position of each ball. The authors are working here on a similar problem of modifying the state of a chessboard, where the model receives a series of moves of pieces and must at the end give the position of each piece:
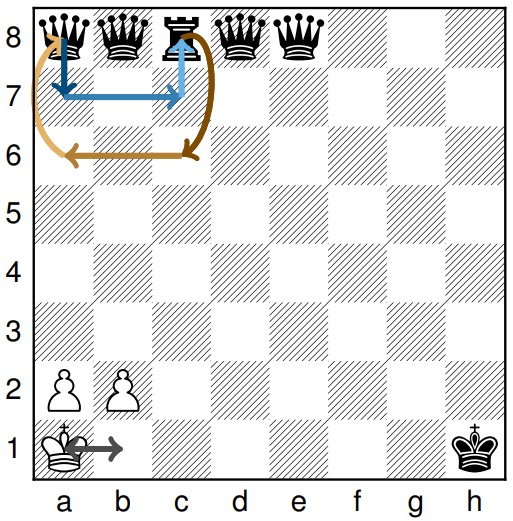
It has already been shown that Transformers are incapable of solving this type of problem in a general way (remember the “general”, we’ll talk about it later). In this case, the authors use a fairly recent and exciting mathematical theory, the Circuit-ComplexityThe aim is to express, for a given architecture, the complexity of the problems that can (or cannot) be solved. The Transformers were already condemned to a fairly simple class of problems, the TC-0 (We won’t go into too much detail here, but we’re thinking about a research review dedicated to this topic). Visit Mamba was an ideal candidate for addressing more complex subjects. Alas (or so much the better, after all, in research, every result is worth taking), it is demonstrated here that the structured space models and the Mamba belong to the same complexity class. They are therefore incapable of addressing a subject of state tracking.
But then, the data-scientist a little despairing of this intellectual chaos, should the Mamba in the trash? Absolutely not. It’s in this context that we can judge the title of the publication to be a little “provocative”.
In fact, impossibility is here demonstrated theoretically for a class of problems, which in itself is very interesting. This doesn’t mean that these models are incapable of handling these subjects, only that for a given complexity (a number of layers in the model), beyond a certain sequence length or complexity, the model will begin to err. It is therefore possible to use these tools for more restricted problems. But even if an architecture is considered theoretically capable of addressing these problems, we have no guarantee of total success. Deep LearningThis is the domain of empiricism, where a model can fail (hallucinate) at any time. And the authors observe here, empirically, that for an equal number of layers, the Mamba is more effective than the Transformer for these state tracking.
The following diagrams show the minimum number of layers required to achieve over 90% accuracy, as a function of sequence length. The first two diagrams relate to simple problems (TC-0), the third to a more complex problem.
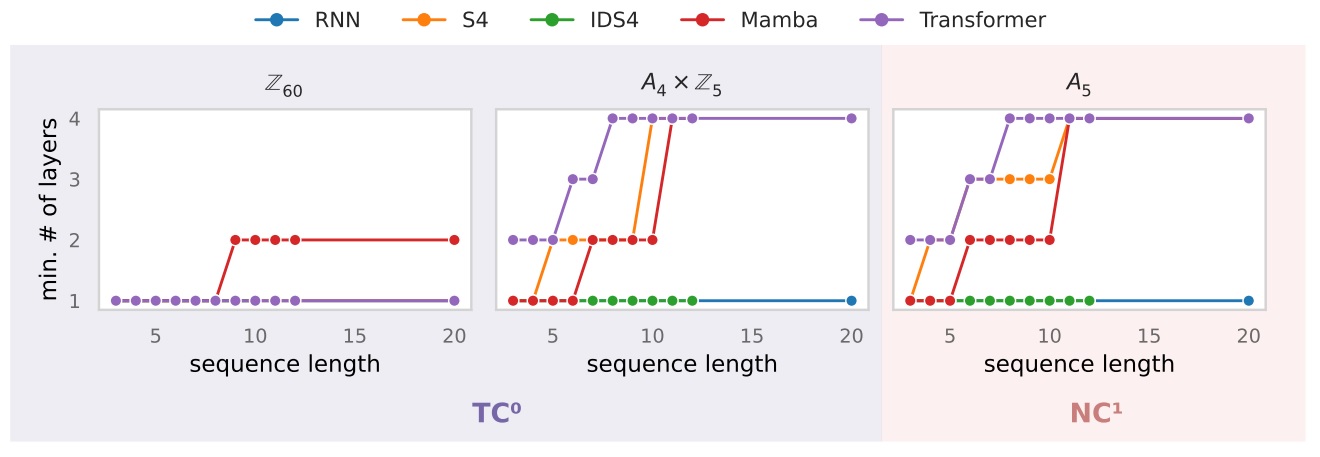
Finally, the authors propose a modification of the Mamba (above: IDS4) which should improve the quality of the architecture. Whereas a new version of Mamba was released last month, these works are rather positive signals to continue monitoring the progress of this architecture and prepare its arrival in our toolbox. 😊