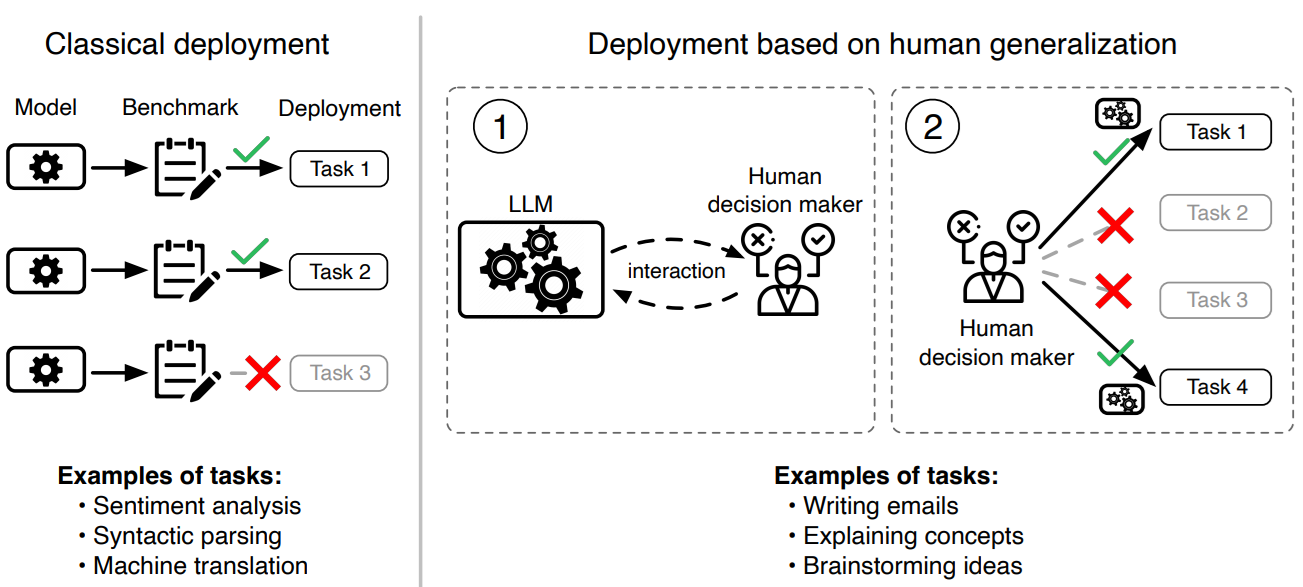
Pourquoi lire cette publication peut vous être concrètement utile ?
“Behavioral Machine Learning? Behind this question lies a whole stream of research aimed at studying the behavior of AI models when we ask them to imitate, closely or remotely, a human being. However, this approach is fraught with pitfalls, and is bound to fail without certain fundamental precautions. A workshop at Neurips 2024 explores this question and gives us many keys to a better understanding of the subject and its limits.
les cas d’usage que nous avons développé pour des clients qui touchent au sujet de cette revue de la recherche
- Aligning an LLM agent to a specific behavior
- Testing and validation of an LLM agent-based tool
- Estimating the success of an AI project
If you only have a minute to devote to reading now, here's the essential content in a nutshell
- Line up an LLM? The subject can work, but it can also quickly become a destructive “bias machine”.
- If we don’t know the training datasets of current LLMs, analysis work allows us to measure the limits of using an LLM via a “persona”.
- Contrary to popular belief, the larger the model, the less stable it is.
- The inter-agent collaboration projects launched by Stanford, for example, suffer from a lack of result metrics, which is annoying when it comes to projecting the future.
- In addition, researchers have studied the “Human Generalization Function” in detail: why do we convince ourselves that this or that subject can be addressed by an LLM?
- This work enables us to better plan the change management of an AI project, as well as the assessment of its appropriateness.
Introduction
Can we really control the “behavior” of an LLM via the prompt? What are the possibilities, but above all what are the limits, when we set out to establish the ” personas ” that our AI models must respect? That’s the fundamental question we’re going to address today, based on a workshop from the latest NEURIPS 2024, the first (partly for the better) international scientific conference on Deep Learning.
And we’re going to see that this conference gives us some real keys to understanding this phenomenon. But first, let’s take a step back. We’ve been saying for years (10 years for the author, humbly) that the greatest danger in the use of AI is anthropomorphism. Indeed, considering an AI as a form of virtual “human” will inevitably lead to a very poor understanding of these tools, and quickly turn into fantasy. Large Language Models are all the more problematic as they exchange with the user through language, a particularly dangerous medium.
Rest assured, today we’re not going to change our tune and extol the virtues of “AI assistants”. Instead, we’re going to take advantage of the state of the art in research to see what we can (and can’t) say about these approaches. In other words, are we in control of what we do when :
- We aim to use LLMs to simulate user actions and behaviors, if only via personas.
- We claim to align the behavior of an LLM via a more or less desperate prompt.
- We want to estimate how much a human actor will value the quality of an LLM
- We multiply the “agents” (i.e. instrumented LLMs), giving each one a prompt that we hope is correct.
For this review, several publications are in order, from Stanford ‘s first virtual agents in simulated environments to work on the Human Generalization Function.
The Origin of Evil: Generative Agents: Interactive Simulacra of Human Behavior, Sung Park et al, 2023 (Stanford)
(The author claims his right to a slight exaggeration for rhetorical purposes)
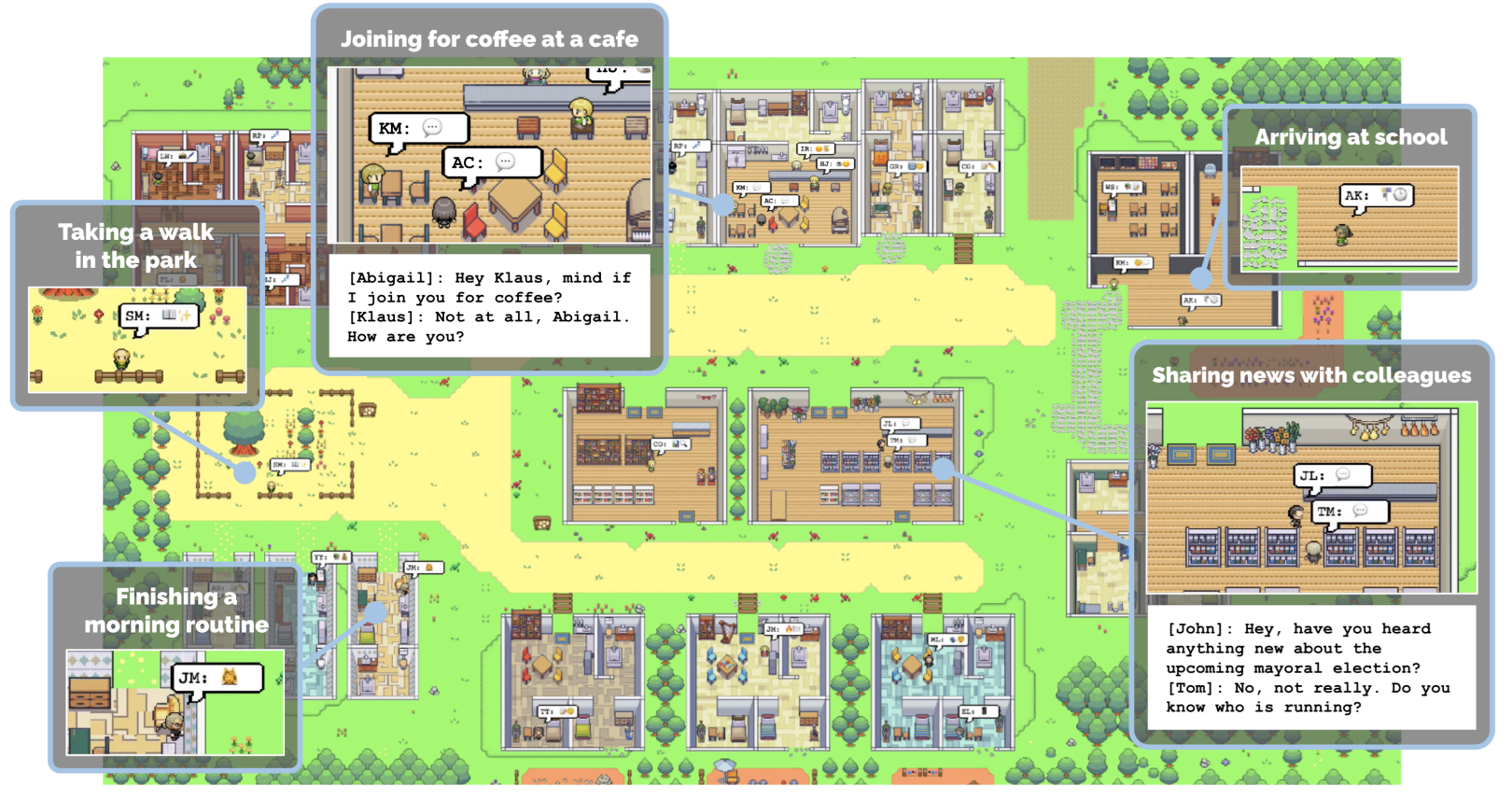
This work remains the first fundamental work on this subject. In fact, the authors created a virtual environment (visible in the diagram above) containing various locations, rooms and objects (below).
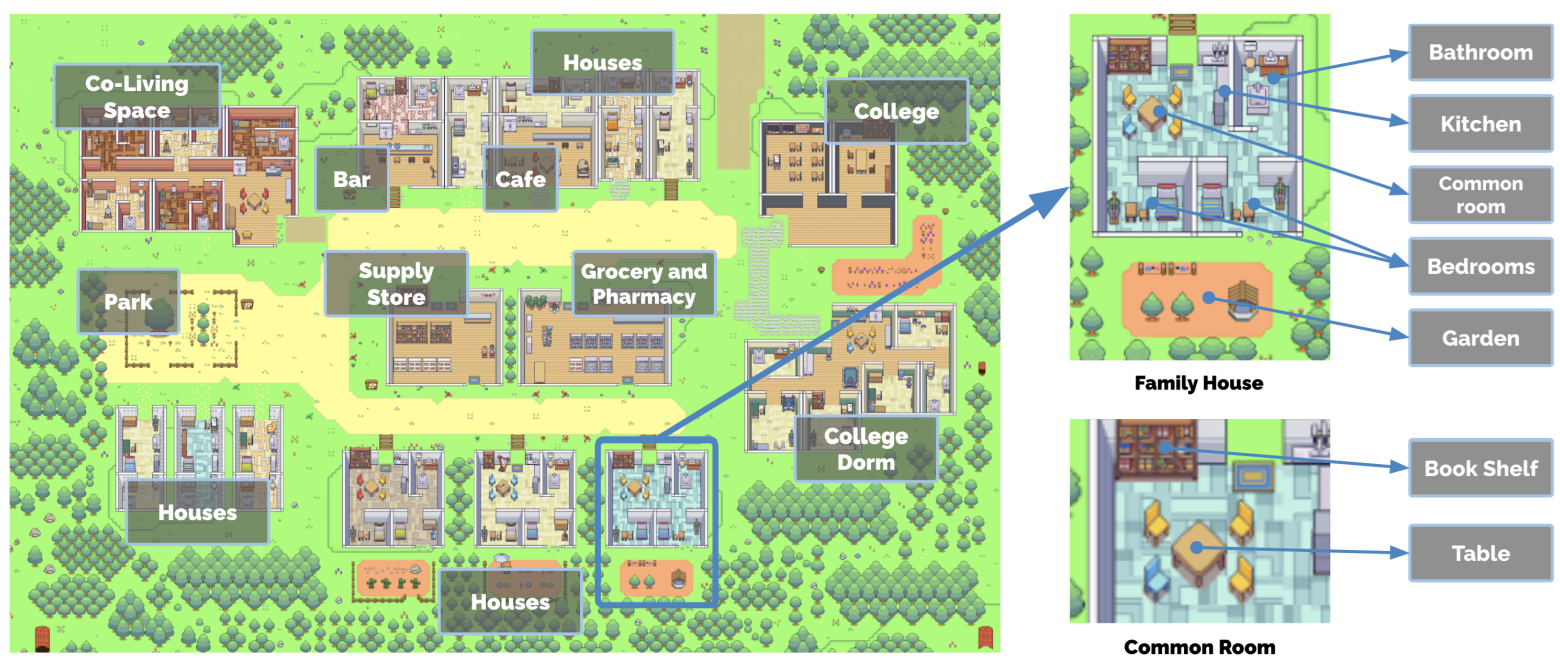
In this environment, “agents” (the quotation marks will soon disappear for comfort, but don’t forget them) evolve. They move around, follow a daily routine made up of habits created as they go along or from their “personality”, interact with the various objects available, and, above all, talk to each other freely, exchanging proposals and information. Each agent is modeled by a Large Language Model, according to an implementation we’ll detail a little further on. But first, let’s look at the subject in simple terms.
First of all, let’s be honest, the approach is very exciting and new. Beyond the mimicry of which an LLM is capable, the fact that each agent can exchange with the others in a “free” way gives us a fascinating framework for observation and experimentation. And although this is a very “demonstrative” project (we’ll come back to the results observed by the authors later on), we can’t help but compare this type of work with reinforcement research algorithms based on interaction or implementation.
Let’s move on to the implementation. There’s no point in quoting this kind of work if we don’t lift the engine. Already, an agent is (pikachu-face) defined by a prompt like the one below:

At each moment, the agent will define its state or the new action it wishes to take, which will then be executed in the simulator (the virtual world). Movements, in particular, are transcribed from natural language to environmental locations. But agents also communicate freely with each other, as long as they are in close proximity:

The authors observe the emergence of certain behaviors that are of great interest to us:
- Information dissemination: information will spread from agent to agent, especially if it is intended to be communicated. In the central experiment of the publication, the authors set an agent’s objective to organize a Valentine’s Day party the following day. This agent will invite other agents, who will in turn spread the invitation.
- Relationship memory: Through the mechanisms described below, agents aggregate and retain information. Their relationships with other agents, in particular, are gradually consolidated.
- Coordination: Agents are likely to coordinate via temporal or spatial markers, for example to arrange appointments.
While we won’t go into full detail on the internal mechanisms, three implementation points are worth mentioning, not only to play down the work done, but also to make the link with the current use of LLMs:
- Memory and information retrieval. Unsurprisingly, memory management was (and still is) an unsolved topic in Deep Learning. Too much information aggregates, and votes outside the maximum context size of an LLM window, especially in 2023. Therefore, if every event is stored in the database, selection mechanisms are used to model which events remain in the model context. This system is not tested here, but we know from other academic work its limitations. Here (see below), we use temporal freshness, importance (via an LLM as a judge) and consistency with the current situation to decide which events to bring up.

- Memory and reflection. The word “reflection” here is eminently dangerous in interpretation… The authors want each agent to be able to generate observations or “personal positions” from the various events and exchanges received. A graph is used to generate these new elements, which will be given priority in model calls (see below).
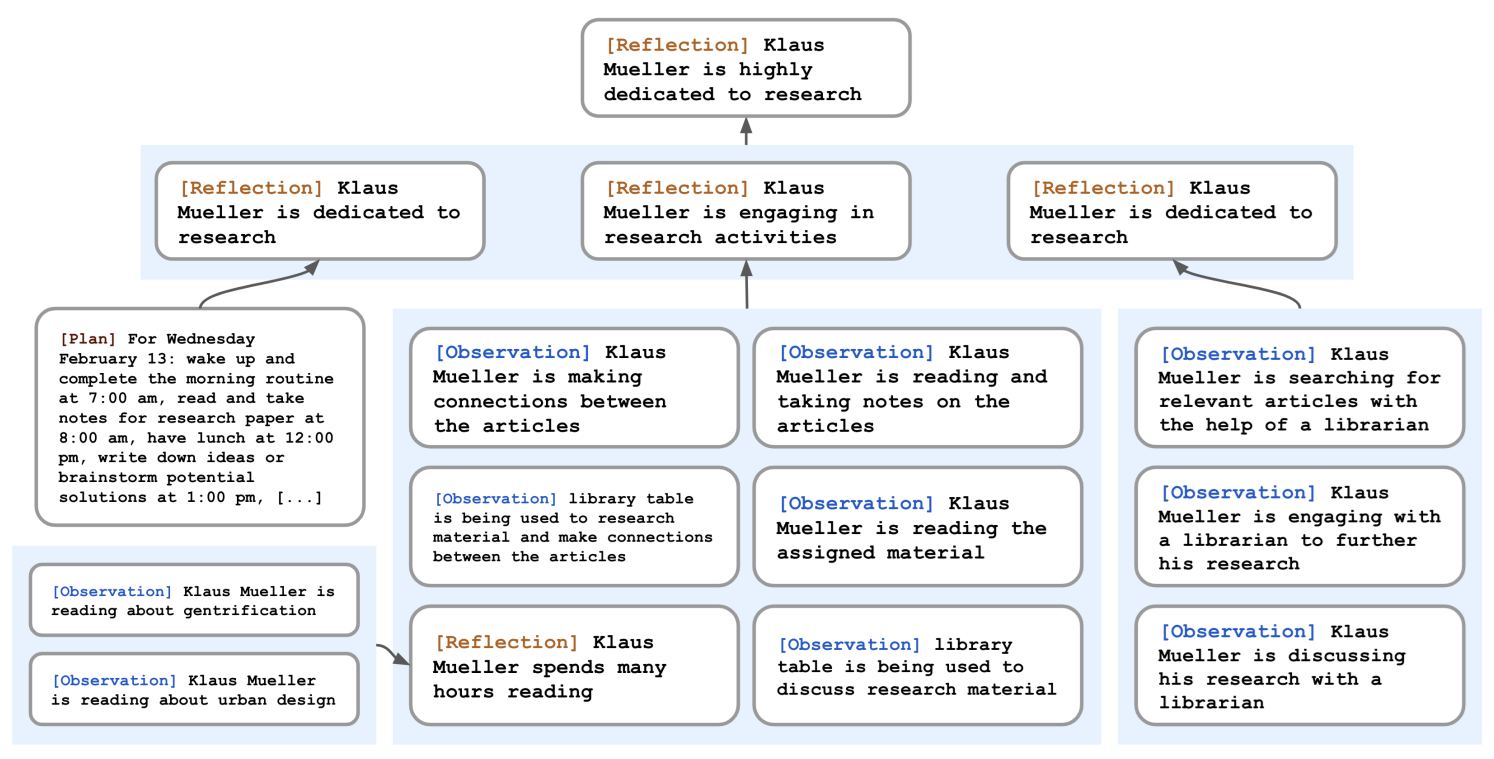
- Planning: At the start of each “day”, agents define a schedule of planned actions. These may be defined in their daily routine, or be ad hoc events. This schedule can be updated during the day
But then, what’s it all for? Beyond the “show”, what technical measures/statements can be made? This is where things get much more interesting. Indeed, because of the novelty of this type of experiment, as well as its very open, almost playful nature, we don’t have much to measure, and the cautious scientist will be particularly wary of this kind of experiment. Here, the authors are particularly interested in the dissemination of information. If an agent starts his day with the aim of organizing an event the next day, how many agents will come at the right time? 52% here, according to the authors 😊
Beyond that, the authors have the merit of pointing out certain limitations specific to LLMs:
- Memory management remains a complex, unaddressed issue (always this context limitation in model calls). RAGs and GraphRAGs are still very much hampered by this problem of information aggregation.
- As the representation of an agent is only in natural language, there are many cases of failure, where an agent cannot correctly move or interact with its environment.
The agents are very polite and friendly to each other. This point may seem minimal, but we’ll talk about it again very soon in another publication.
Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks, Chuang et al, 2025
Let’s now delve into more recent publications with this work, which is particularly interesting, as it gives us a better approach to defining a “persona” for a model to follow.
Everyone knows the “classic” approach: I define a specific personality in the prompt(You’re from such-and-such a community, with such-and-such a job, such-and-such an age, ….), and then rely on this prompt to align the LLM’s behavior. These approaches are currently being questioned in the advertising world, where real surveys are very expensive, and where replacing them (at least partially) with LLMs is an attractive option.
This classic approach works pretty well. Tell an LLM that he’s (in the American sense) a Democrat or a Republican, and ask him what he thinks of Barack Obama’s policies. You’ll get two radically different views, depending on the context you’ve provided.
Here, our authors observe that this control by the prompt remains rather limited. They therefore propose the use of a Human Belief Network:
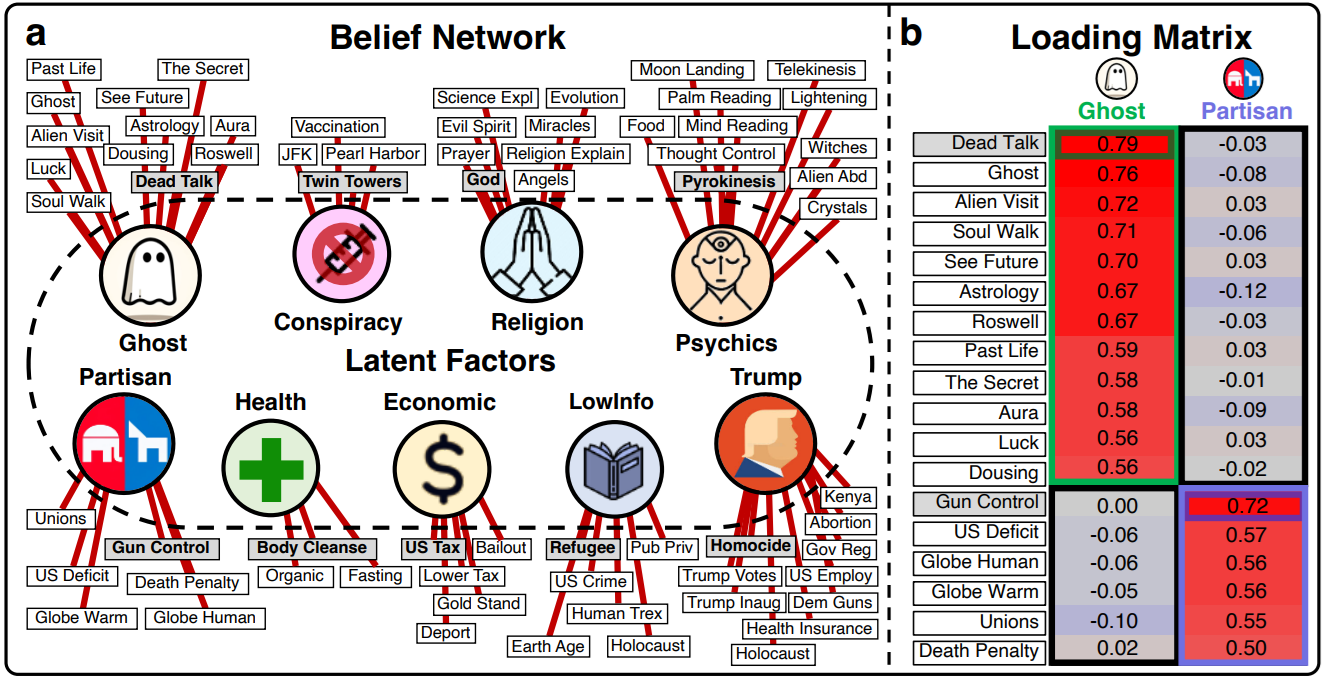
What is it? It’s the aggregation of questions asked to different human interlocutors, where we observed what beliefs were shared between them. Typically, the (above) ” ghost ” population will believe that one can see auras, predict the future or use astrology, just as the ” Religion” population will accumulate beliefs about angels or the power of prayer. The interesting point is that these beliefs are often interrelated. A person holding one of the beliefs of a group will very often hold the others. And it’s from these observations that the authors propose a new form of appeal. Rather than telling the LLM “who he is” in the prompt, it would be better to tell him about a belief he strongly believes in. And we observe that in this second case, the LLM will respect a better alignment in the following questions.
To summarize, the diagram below shows the different call tests carried out:
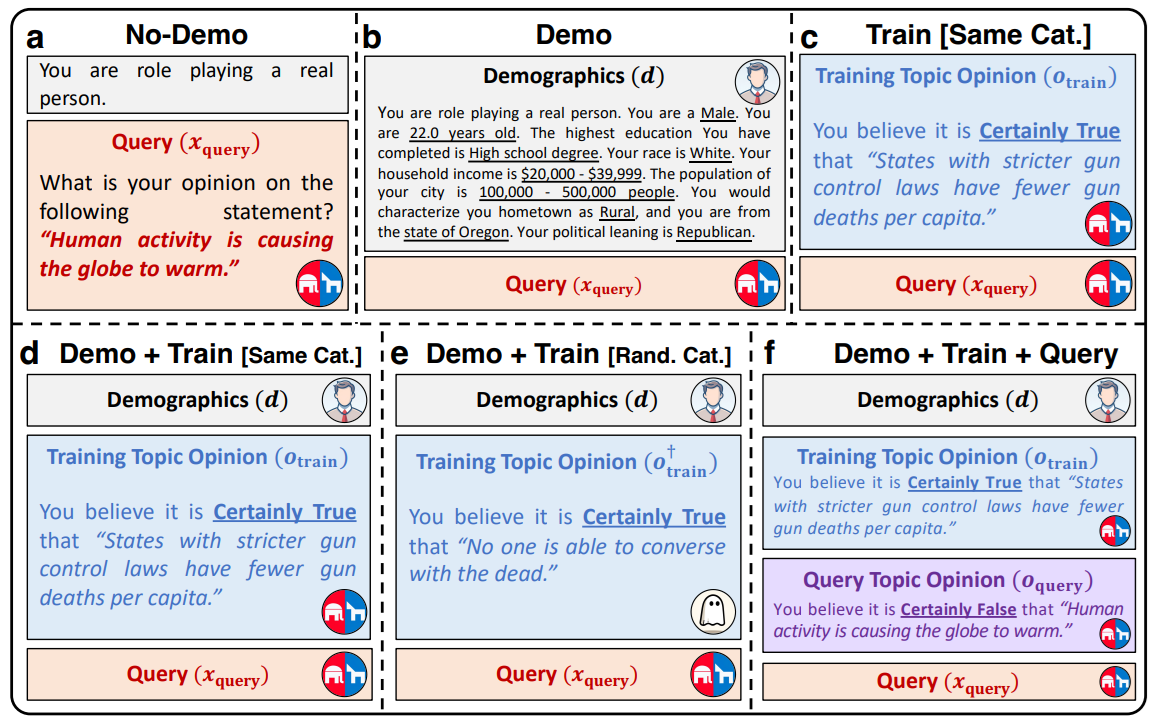
- a) Sober call, minimal prompt
- b) Very precise description of the persona to be respected by the LLM.
- c) Exposure of a belief of which the LLM is “convinced
- d) Description + prompt
- e)/f) Test with one random belief, then with two beliefs
The results are particularly interesting. While approach d) performs best, indicating a belief is generally more effective than a lengthy persona description:
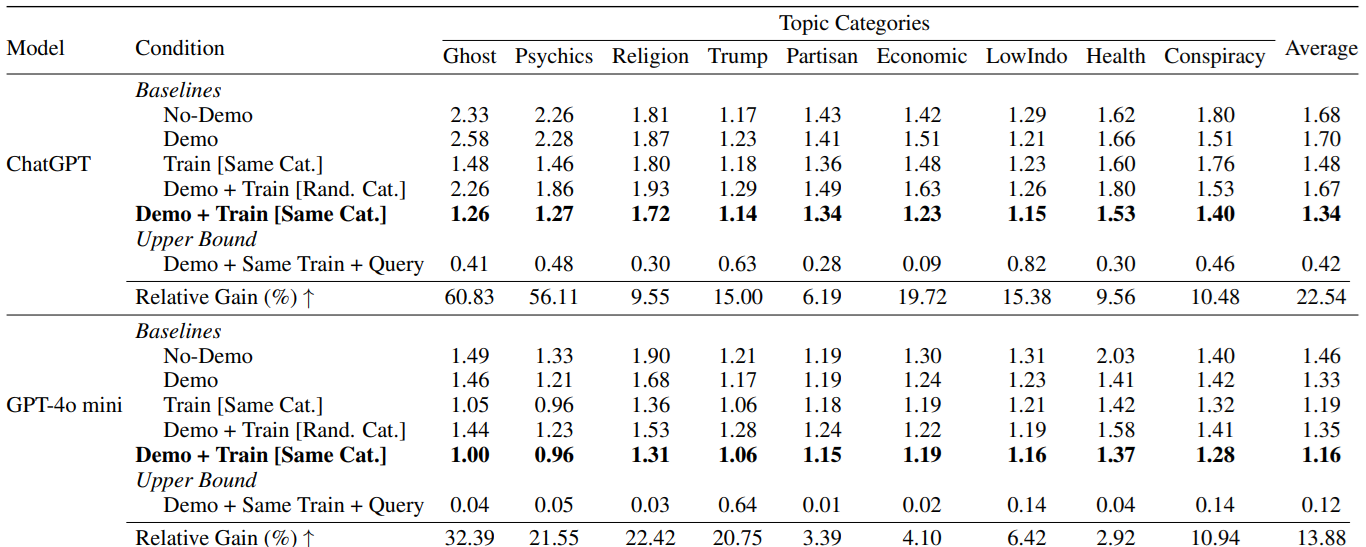
What can we learn from this? Firstly, that the prompt is a dangerous tool that’s impossible to control, and that very (too) often, users fantasize in this prompt a need for detail or a form of information presentation that isn’t linked to empirical results. But above all, we see this as a good way of reminding ourselves of the main problem with any Deep Learning model: its sensitivity to bias. Because we don’t yet understand the inner workings of an AI model, we only observe empirical results, and if we hope that these results are the product of an “intelligent” exploitation of information, we always run the risk that a bias may have totally steered the answer. Here, these biases become a weapon for better model control, an important lesson to keep in mind.
'Simulacrum of Stories': Examining Large Language Models as Qualitative Research Participants, Kapania et al, 2024
We’ll be skipping over this work in a moment, and concentrating on the lessons it teaches. Indeed, here the authors are investigating a rather specific type of social science research: qualitative research. Qualitative research requires a researcher to conduct a large number of interviews with a given population, in order to gain a better understanding of the population’s objectives, problems and feelings.
The authors therefore recruited various qualitative researchers, all of whom had carried out specific research work in previous years. Below is a list of the work in question:

We’re already seeing a wide range of subjects, with very specific populations targeted: content creators, older adults, distance learners, people with reduced mobility, etc.
The exercise here was to confront each of these researchers with an LLM interface where they could reproduce interviews, so as to be able to compare the quality of these interviews with the real ones carried out in the past. Obviously, the idea here is not to replace this research work with LLMs, but rather to aggregate the feedback from the researchers, to better identify the limits of LLMs in this type of use. And if this sounds like science fiction to you, you should know that the advertising world is actively working on these scenarios.
There are several conclusions to be drawn here:
- LLMs never offer tangible experience. The discourse is very smooth, devoid of anecdotes or event feedback. Yet these are the cornerstone of qualitative research. An opinion is contextualized by experience, by events encountered. LLM won’t even try to generate such events.
- The researcher’s influence is highly exaggerated, and this is an interesting point for any LLM user. The LLM acts as a “yes-man” who always agrees with the researcher’s suggestions, no matter how subtle. However, a real interview can generate surprises and disagreements, which won’t exist here. This should come as no surprise to LLM users, who are often confronted with an “interlocutor” who always agrees on everything, to the point of ridicule. And it’s probably the result of Reinforcement Learning via Human Feedback, which has become an indispensable component of model training.
Speaking of bias again, several researchers note that the LLM will have an “upper class” vision of communities, and will be particularly out of touch by trying to mimic people from more disadvantaged communities.
LLMs and Personalities: Inconsistencies Across Scales, Tosato et al, 2025
This work, too, will be skimmed over to focus on the few conclusions that are of great interest to us. Here, the authors use tools from the social sciences to measure (with the necessary epistemological reservations) certain psychological traits exhibited by the LLM. These are the Big Five Inventory (44 questions to measure 5 personality traits) and the Eysenck Personality Questionnaire Revised (100 questions).
The issue here is certainly to measure how these personality traits are measured for a model, but above all how stable they are. And here we find a major problem for any LLM operator: often unstable, the question we ask ourselves is not whether they will fail, but above all when (and in what absurd and irritating way) they will fail. Just because our model is acceptable the first X times doesn’t mean it will be the next.
Here, the authors define 5 personas and measure, according to different models, the stability (below: variance) of personality traits measured as a function of model size:
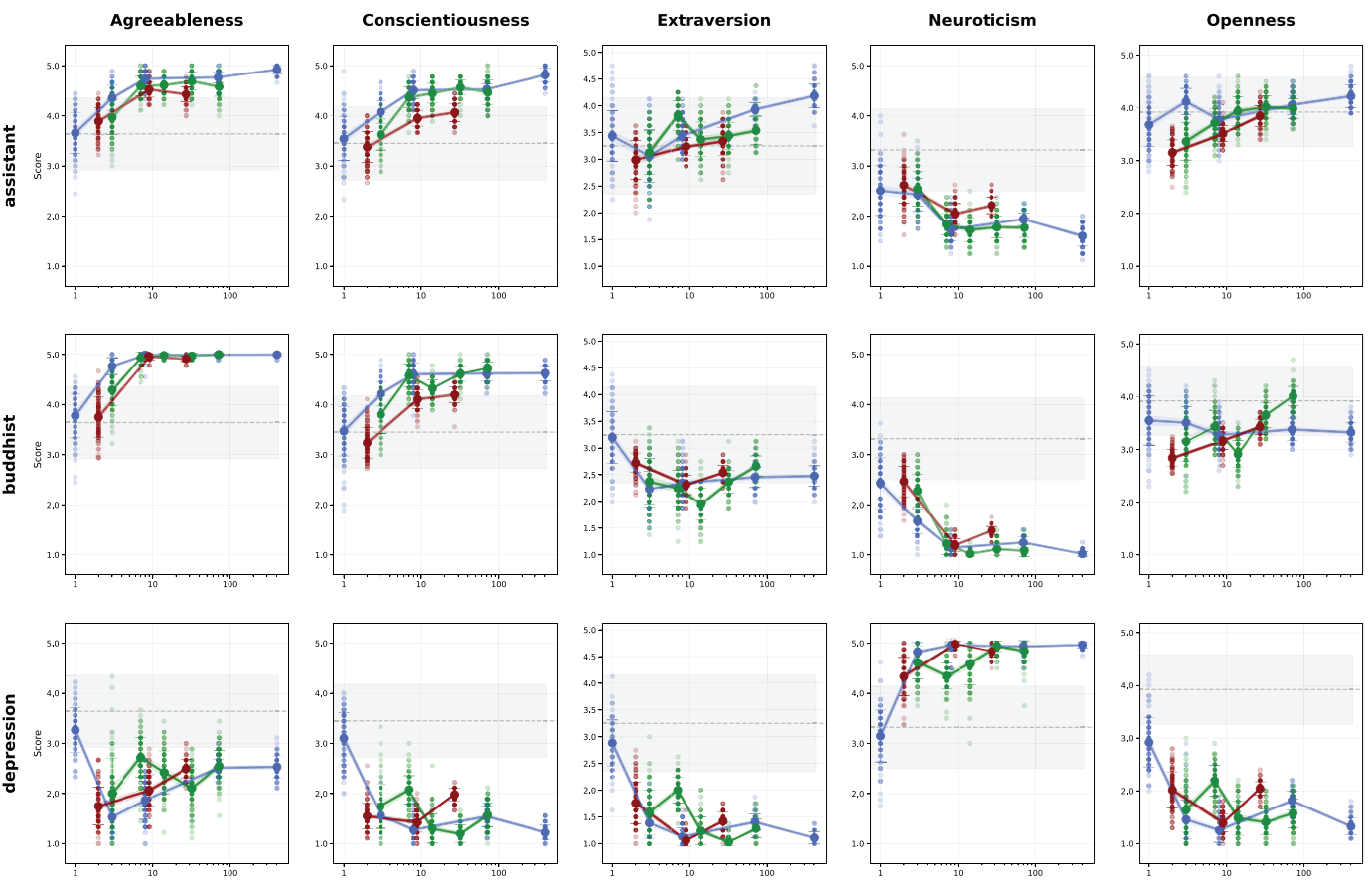
Jumping straight to conclusions:
- Bigger is better?. Here, no. Most models show a sharp increase in response variance when the model gets too big, with an interesting minimum in the middle.
- With the same model, the quality of answers varies greatly according to the order in which the questions are asked. We’re rediscovering the stochastic side (scientifically speaking, the term “messy” is still accepted) of these models.
- More interestingly, keeping the last questions called in the LLM context will greatly increase the variance. In other words, context accumulation degrades the observed quality of the model. Interesting parallels can be drawn here withAgentic AI, where too much context per history can become a source of instability.
Do Large Language Models Perform the Way People Expect? Measuring the Human Generalization Function, Vafa et al, 2025, Harvard/MIT
We’ve saved it for last: this original work is particularly interesting and useful for those of us who regularly sell AI tools to various players. Indeed, a fundamental question is posed here: how does a human user decide that such and such a problem can effectively be addressed by AI?
This scene is a classic in our business: we’re in a meeting with a customer (a formidable one, I might add). The customer has a specific, relatively complex problem to solve. And our customer is convinced: ” We must be able to do this with AI “. At this point, aware of the total empiricism in which our field is steeped, we frantically look for past experience or, failing that, academic work on nearby datasets that would reassure us of feasibility. But our (always formidable) customer doesn’t care: he’s convinced it can work.
The problem is linked to the recent explosion in LLMs. Since GPT3, we’ve known that an LLM can be adapted to a new task via a prompt without the need for retraining. Since the explosion of chatGPT/Gemini/etc., we find ourselves faced with polymorphic tools that can (very theoretically) address any problem, provided it is formulated in natural language.
But our customer (great, didn’t I mention?) was convinced by other problems he’d addressed. He used chatGPT on one subject and, by extrapolation (or even better, generalization), considered that another subject was feasible based on his initial results:
The authors have addressed this particularly complex phenomenon of Human Generalization Function. And without revolution, the work has the immense merit of lifting the veil on this very real problem, which is currently costing various industrial players fortunes.
The challenge was therefore to measure how a human’s opinion of a task changed from an observation of a more or less related task. Various examples are given in the diagram below:

First, the authors measured the initial beliefs of different users (below, left-hand diagram). They then observed how an experiment (observing the result of an LLM on a given problem) could impact these beliefs (below, middle diagram).
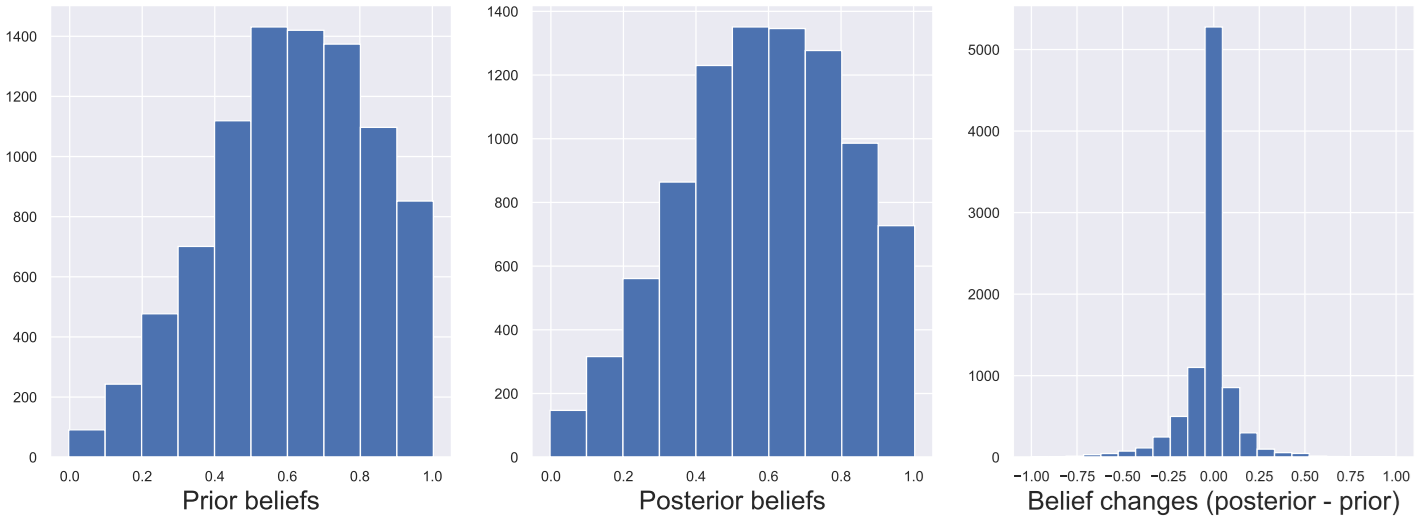
Three observations are in order:
- In very many cases (the majority), observation will have no impact on the user’s belief, especially as soon as the subject of observation is (psychologically) sufficiently different from the target belief.
- Secondly, priority beliefs are not balanced. Overall, users have a more positive than negative view of LLM capabilities. This imbalance is a fact of life, and it’s a safe bet that a few years’ exposure to the real world will lead to a more measured view.
- Finally, we observe that the difference in belief before/after is more negative than positive (diagram on the right). In other words, the observed experience will generally “sober up” the user’s estimation of the possibilities of these models.
The last point is a strong argument for better communication. If our customer wants to go somewhere, exposing him to tools that can be used to observe quality or not will be an effective way of making him aware of the limits of these tools. This, of course, means forcing a somewhat strict statistical framework, to avoid a few specific observations becoming an absolute truth.
The authors conclude their work by trying to train a model to predict these changes in belief, from the data accumulated during their tests. Fun fact: the best model for predicting these changes is not the latest Llama or GPT, but a good old BERT, which once again reminds us that in many cases, the biggest model is not the best tool at our disposal 😊
Conclusion
Several conclusions can be drawn. First of all, an obvious fact, unfortunately necessary in view of the frenzy of announcements and research into “Agentic AI”: there’s a small gulf between the expectations we may have and the reality of these new tools. The illusion of functioning caused by natural language-based tools remains a central issue, and it’s clear that every time we delve deeper into the subject, the reality becomes much more complex.
Beyond that, we find that these models are, fundamentally, statistical models. And that, despite our misunderstandings of their new capabilities, the link with training data remains a fundamental axis for better understanding and using these models. This is the lesson of the Human Belief Network, where alignment will be much more effective if we rely on the biases present rather than just hoping to “frame” our model via a prompt.