
Research Echoes #10
Beyond Six-Fingered Hands :
Detecting AI-Generated Images, and Other Advancements
Download link for the article.
Detecting AI-generated images becomes (slightly more) credible, reinforcement learning is becoming industrialized, and we are a little less clueless about diffusion models.
If you only have a minute to spare for reading, here's the essential content in 7 points :
Detection of AI-generated images
- So far, solutions for detecting whether an image has been generated by AI have been particularly ineffective.
- The use of geometric logic on an image (shadows, vanishing points, etc.) allows for the implementation of a valid and relevant detection of generated images.
- These approaches are intended to be surpassed, but remain the best available solution to date.
Reinforcement and industrialization
- Reinforcement represents probably the next "revolution" in AI, and until now we didn't have a global and generic tool.
- Meta AI offers a comprehensive reinforcement framework that seems complete and modular, allowing to engage in a project while minimizing the risk of technical debt or over-specialization of tools.
- This framework goes beyond classical approaches (robotics, video games) to address much more concrete optimization problems.
Generative AI and interpretability
- Finally, we have new tools thanks to Deepmind to better interpret and control diffusion models, notably to extract a latent space for these models.
- What you can tell a colleague or your boss about it?
We can finally claim to detect generative AI images, which is excellent news if we have moderation issues with this type of tool. Moreover, we can much more easily apply reinforcement approaches, especially to "business" optimization problems like targeted advertising purchases. Finally, we have a better understanding of diffusion models that have been in the spotlight for the past two years, and telling you this deserves a raise, boss.
- What key technical concepts will be covered?
Detection of images generated by AI
Reinforcement: modularity and architecture
Diffusion models: latent spaces and control
- Which business processes are likely to be modified based on this research?
Detection of "fake" images.
Optimization of more or less blind processes.
Control of generative AI.
- What sentence to put in an email to send this research echo to a friend and make them want to read it?
You have the opportunity to practically understand the detection of AI-generated images, or apply reinforcement painlessly to your optimization problem.
- The use cases we have developed for clients at Datalchemy that relate to the topic of this research briefing include :
- Detection of toxicity in text messages and images.
- Control, robustness, and interpretability of Deep Learning models.
Here we go...
As every month, we offer you a presentation of the academic work from the past month that we find interesting and useful for short-term deployment.
Detecting images generated by AI becomes (somewhat) feasible.
The advent of generative AIs (notably: Stable Diffusion XL, Midjourney, etc.) is beginning to disrupt the role of artistic creation in our society, potentially for the worse rather than the better, considering the social and economic impacts of these new tools. Among the new questions that have arisen with these tools is the quick need to correctly identify whether a work was generated by one of these models or not. However, the tools available to date have not lived up to their promises of good detection, interpreting generated images as original as often as the reverse. It's worth noting that this problem also exists for ChatGPT and other Large Language Models, raising fundamental questions about the necessary evolution of current educational methods.
The fundamental problem with all these detectors is that they rely on a "global" Deep Learning approach to classification, facing a dataset accumulated by researchers that will necessarily be too limited to play a traditional role. Moreover, training a global Deep Learning model implies a total lack of interpretability in the results, producing a tool that can (as usual) succeed or fail in a blind and uncontrollable manner. Furthermore, the subject approaches the issue of adversarial attacks in that if an approach emerges that allows for minimal detection of synthetic images, subsequent generation models will take into account this detection method, rendering it useless.
However, a new study was published last month that seems to be a much more credible approach for detecting synthetic images: "Shadows Don't Lie and Lines Can't Bend! Generative Models don't know Projective Geometry…for now" by Sarkar et al. [https://arxiv.org/abs/2311.17138]. In this paper, the authors define a number of constraints that allow, without fail, to identify a "fake" image. These constraints are based on projective geometry (and therefore concern only photographs), with the following points :
- Perspective Line Analysis A photograph has a specific perspective with the existence of a unique vanishing point towards which the perspective lines converge. However, generative AIs tend to create distorted perspectives that can be detected.
- Consistency of Lights and Shadows Generative AIs tend to not create geometrically valid shadows relative to the directions of light, with anomalies in the length or brightness of the generated shadows.
- Consistency of Element Dimensions : The size of an element should decrease as it gets farther from the viewpoint. This fundamental notion of consistency is an interesting analysis axis.
- Geometric Element Distortion : Basic geometric shapes should retain their properties despite being projected onto the image plane. Otherwise, improper projection signals a synthetic image.
- Depth Analysis : Many elements help convey the notion of depth in a standard image, such as texture gradients. Analyzing these elements is another axis for discriminating synthetically generated images.
Here, the interest lies in identifying discrimination criteria first, and then attempting to detect whether these criteria are met. Thus, we have a tool that will not assert monolithically that an image is false, but will be able to "justify" its prediction, particularly by extracting the most important elements to present them to a user who will make the final decision. This approach is much more constructive, even though it has some limitations.
The main limitation is that the application of these detection criteria is done by neural networks themselves, which are fallible, making complete automation in application difficult. Below is an example with two images generated by StableDiffusionXL and the detections of shadow and perspective compliance. The "colorimetric" images come from the fairly standard GradCam approach in Deep Learning.

The above diagram shows the ROC curve of different detectors across three datasets. The first dataset consists of images correctly classified by a "classic" generative AI detection approach, the second consists of images where classic approaches rely on chance, and the last consists of images considered by classic approaches (incorrectly) as natural images. The red curve indicates the results of the classic approach, while the green, yellow, and blue (solid) curves indicate the results of the various geometric criteria described in Sarkar and al.'s approach :
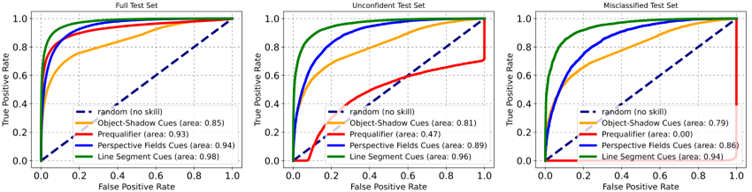
Obviously, we cannot ignore the end of the publication title: Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry…for now. This approach is fundamentally intended to be invalidated when work takes into account these criteria to train generative models. That said, considering the cost of such training, we have a viable heuristic here for detecting a certain number of synthetic images.
The reinforcement is (probably) the next "revolution" of AI
Reinforcement learning (Deep Reinforcement Learning or DRL) is the domain of Deep Learning that regularly makes headlines in terms of scientific achievements, but which, in practice, proves difficult to industrialize. AlphaGo, the alignment of ChatGPT, and numerous works in robotics rely on this paradigm which, due to its extreme freedom, allows solving many very different problems. Indeed, defining a problem in reinforcement learning involves considering an autonomous agent that must succeed in accomplishing a task to obtain a numerical reward, thus abstracting away many constraints such as the use of a mapped dataset , the exploitation of a differentiable objective function (loss function), etc. Virtually all imaginable problems can be modeled as reinforcement learning...
Of course, things are not as simple, and three major difficulties exist in this field today :
- The need for a simulation environment in which to train the agent, which is not essential but often necessary. This environment then replaces the training dataset in modeling the problem, but all the doubts and questions that one must pose about a dataset are thus transferred to the environment, notably to what extent it represents reality in all its variances. However, a perfect simulator generally does not exist (unless considering highly constrained problems like the game of Go), and the transition from simulation to reality is often the main point of complexity that many researchers still struggle with.
- The heaviness of the training. In the majority of cases, training in Deep Reinforcement Learning will be much heavier (and therefore much more costly) than traditional training. Moreover, the hyperparameters used to adjust an algorithm are here less straightforward to study and adapt (although simplicity is relative even in traditional Deep Learning ).
- The lack of a modular and stable framework, allowing for algorithmic choices to vary with equal architecture. Different works on the subject are indeed very isolated from each other, and even if frameworks exist today, they remain limited in their generality. Notable examples include Robosuite, which is an effective encapsulation of the Mujoco simulator, and the famous OpenAI Gym, which offers a consistent interface, but only for defining a learning environment.
This latter point is what MetaAI is now addressing in a recent publication: Pearl: A Production-ready Reinforcement Learning Agent by Zhu et al. [https://arxiv.org/abs/2312.03814]. It's already surprising to see Meta AI working on this reinforcement topic from which they had, until now, kept themselves quite distant. But more importantly, this work is by no means aimed at proposing yet another new reinforcement algorithm, but rather a global, modular architecture, allowing to address many different problems in a single working context. This type of work is fundamental for engineers (like us 🙂 ) wishing to move towards greater efficiency.
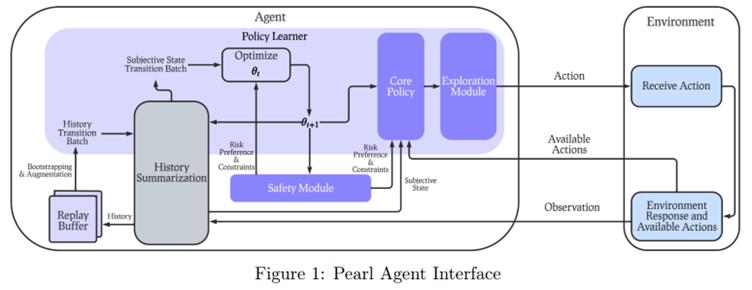
The diagram above presents the overall approach, which summarizes a number of very important modularity points. It is noted that the agent's design (on the left) takes into account numerous possible learning scenarios, including the possibility of offline learning (or pre-learning), based solely on accumulated data. The Core Policy encapsulates a number of ready-to-use reference algorithms, whether in classic Q-Learning (where experts will regret the absence of Deepmind's Rainbow), in Policy Gradients (the reference approach in robotics control) particularly with Proximal Policy Optimization or Soft Actor Critic, but also (more rarely) in distributional approaches, or via bandits algorithms that are more effective for optimizing a categorical process (we'll talk about this very soon). Similarly, the Exploration Module allows for exposing different exploration methods, the latter being a fundamental axis in reinforcement, an agent must be able to explore different possibilities to generate a valid action policy. Of particular interest, the integration of a Safety Module is a welcome originality, reinforcement approaches being potentially very dangerous until they are strongly limited in their action catalog. Finally, the History Summarization and Replay Buffer blocks are relatively standard elements, allowing to structure and manage the experiences encountered by the agent to improve learning.
Note that classic reinforcement benchmarks are applied here to present the results obtained by the framework according to the strategy chosen for the agent. Below: four tasks of continuous control (very close to robotic control) with different algorithms used :

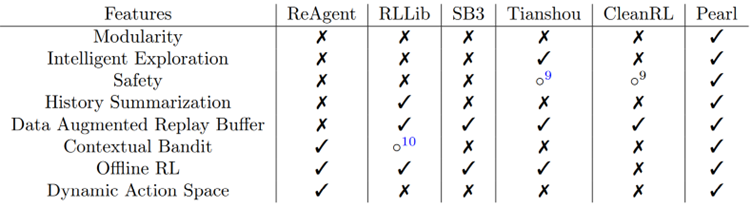
The interest here is not the discovery of an "amazing" new algorithm, but the provision of a complete toolbox, something that was sorely lacking in the field. The table below provides a comparison of existing solutions :
One last point of strong interest lies in the applications. Here, researchers are moving away from the "classics" that are as fascinating as they are useless for 90% of the economic landscape, and propose implementations based on Bandits (modeling of random phenomena similar to "slot machines") for three relevant problems: a recommendation system for an auction framework, the purchase of advertising space facing a provider offering variable prices and targets, and a creative selection module to offer users suitable content. Such problems are rarely addressed in "pure" research work but correspond to issues that can be addressed by reinforcement learning and where there is a real need for a solution.
Relief : the latent spaces lost by diffusion about to be found again.
The latent space (also called embedding space) is a fundamental axis in Deep Learning, which has led to a whole research trend. To recap, training a neural network to perform a task will involve the network implicitly learning to simplify the input information, via intermediate representations inside the network that become increasingly simpler (with a reduced number of dimensions). This point is crucial for several reasons. Firstly, it represents one of the best axes of interpretability in Deep Learning by studying this simpler space into which the neural network projects its information. But more importantly, many unsupervised approaches (outlier detection, clustering) are based on these intermediate representations. Learning these representations is a generic axis in Deep Learning, with one of the most well-known examples being the work of Lord Milokov, nicknamed "word2vec," where a word is transformed into a much simpler vector for processing, and where Milokov at the time discovered that simple geometric operations on these vectors had a genuine semantic meaning in the space of studied words.
This approach is all the more fundamental as several families of Deep Learning models aim exclusively to learn these correspondences between a simple latent space and a complex data space. We are talking here about approaches in generative AI, for example, through Variational Autoencoders (or their smaller cousins, the VQ-VAE) or Generative Adversarial Networks.
The fundamental problem is that research progresses much faster in discovering new architectures than in analyzing these architectures. Already, the transition (criticized, see our latest research review) to Transformers in image processing has led us to lose a lot in the "understanding" of the models used. Where we could easily match a spatial area of the input image to an area of the latent vector (the famous spatial bias) for a convolutional network, the exercise becomes much more perilous when it comes to Vision Transformers. But it was the 2021 revolution on diffusion models that totally challenged these works. Indeed, while these new models have created some quite staggering new state-of-the-art results, the process of generating an image (learning denoising to start from a noise sample) in diffusion models does not directly involve simplifying the image (in terms of reducing its number of dimensions), and our latent spaces are thus lost at sea. Note that in the original work Stable Diffusion, Rombach et al. first learned a latent space via a VQ-VAE, and then applied diffusion to the latent vector derived from an image.
Good news! Things are improving with a new work from Deepmind that we discussed during our last webinar on cross-embeddings. SODA: Bottleneck Diffusion Models for Representation Learning, by Hudson et al. [[https://arxiv.org/abs/2311.17901], is a work by the renowned Deepmind aiming to integrate the learning of a latent space into the training of a diffusion model. What's interesting here is that the authors enhance diffusion by training an encoder to generate a latent vector from an input image, which is then utilized by the diffusion to generate an image corresponding to the original one. Several scenarios are considered for the corresponding image, including image completion, generating a new angle, etc.

Let's note that the authors leverage the encoder to enforce the learning of variances directly, typically, the pose of the generated element, or the texture/color of the image. And having this latent space directly enables the creation of relevant and smooth interpolations of a generated image :

The authors succeed in identifying directions (in the latent space) allowing controlled modifications of the generated image: size and structure of the generated image, lighting and viewpoint, maturity, length of fur, etc :

The fact that these modifications are made on the latent space is interesting because they become much more controllable. A point of attention is notably on the distinction between what the encoder learns compared to what the diffusion process learns. Indeed, the encoder will learn to model high-level variances (semantically speaking) on the generated image, whereas diffusion seems to learn to manage localized details (at higher frequency) of the image. This allows for a first intuition that a diffusion process learns representations radically different from what a traditional Deep Learning model can learn.
Author : Eric Debeir – Scientific Director at Datalchemy – eric@datalchemy.net
And here's a little surprise for some fun, related to the first topic of these Research Echoes... an image spinning on X :
