
Research Echoes #3
Reinforcement for football or Dark Souls 3, and new generative models
For our latest edition of Research Tracker, we're looking forward to talking a little about Deep Reinforcement Learning. This fascinating field is gradually becoming applicable to real-world problems, and we have identified two highly original projects. The first has already caused quite a stir on social networks, the second much less so. We will then continue our monitoring of generative models, moving away a little from diffusion models applied to images, which have already been heavily promoted, for two different approaches. The first is applied to sound (a more difficult subject than images), while the second heralds a new family of models...
Reinforcement, football and the boss...
Reinforcement is an area of AI that enables an autonomous agent to be trained using a reward system. This field has already produced a wealth of results (AlphaGo, World Models), but any new application is worth studying to better understand how to use these approaches. The first result here is that miniature autonomous robotic agents have learned to play football, which is quite an achievement. The other example shows how an agent gradually learned to play a recent and fairly complex video game.
What's happening?
When Deepmind releases a reinforcement learning publication, one feels somewhat obligated to listen, if only because they have already produced AlphaGo and numerous algorithms like Rainbow. Here, robots are learning to play soccer, and beyond the spectacle produced, many points are very interesting from a research standpoint.
Teach me football, and I'll come to the training sessions
In Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning by Haarnoja et al [https://arxiv.org/abs/2304.13653], the authors propose a comprehensive approach to address the subject. Among the notable points :
Two miniature autonomous bipedal robots face each other on a closed football field and must kick a ball into each other's goal.
The authors work on a classical approach where learning is done in simulation and application in reality. However, the problem of transitioning from one to the other, Sim2Real, has already caused numerous traumas in research or industry. Having a proficient agent in simulation is "easy." Having an agent that can generalize to real cases is much more challenging. One could argue (rightly) that here, the authors have optimal control of the real world, far from the conditions of a factory, for example. However, the application of Domain Randomization in this case is very interesting.
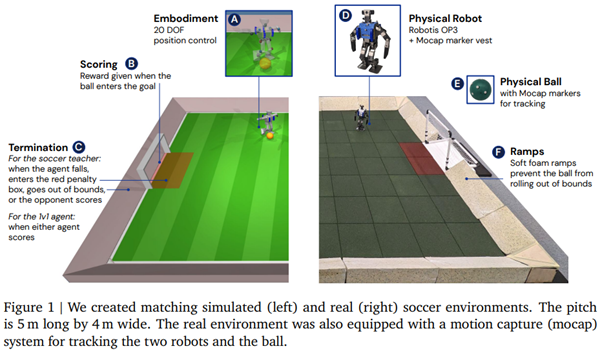
Another point of interest is the use here (in the initial versions) of observations based on numerical values precisely defining the behavior of the opponent agent, rather than a camera present on the robot. This point confirms that today, the use of vision in reinforcement learning still poses an impressively complex challenge. It is worth noting that the authors, in a later stage, tested learning directly from the captured image, yielding interesting but much less convincing results. This is crucial to emphasize because it implies that in practical applications, it is necessary to retrieve these absolute values (ball position, position and movement of the other player), with any measurement error leading to system failure.
The training process is also interesting, as it is tailored to the problem. Here, two separate and distinct initial trainings are conducted for two specific issues :
- The "soccer teacher" aims to train the agent to score as many goals as possible while in a standing position.
- The "get up teacher" trains the agent to stand up and remain upright.
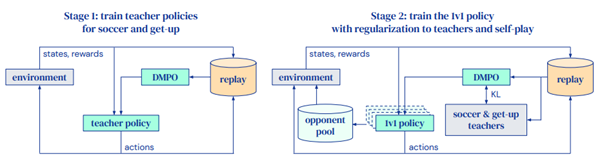
It is after these two trainings that we train the "1vs1 policy" that an agent will follow.
Each training obviously has its own rewards. The gradual approach isolates the main issues that cannot be taught globally. This leads to the already known conclusion: learning locomotion is a non-trivial problem.
In summary, beyond the feat and the spectacle, this work is a "must-read" to observe how DRL approaches have been decomposed to provide a functional solution in the end.
Dark Souls 3: when a player seeks a surefire strategy with the help of AI

Let's switch to a much less headline-grabbing application, but one that is just as rich in lessons and experiences. A merry madman set out to learn to play the game Dark Souls 3 and defeat the boss using AI!
In this article: [https://soulsgym.readthedocs.io/en/latest/?badge=latest], he notably extended the OpenAIGym environment to integrate the game as an environment. Unfortunately, he does not work on the game's image but on numerical data representing the enemy and the player's situation. What is fascinating here is to observe which techniques worked for an amateur far from Deepmind/OpenAI. And it must be acknowledged that his approach works, using rather simple algorithms (here in Q Learning, Duelling Double Q Learning). The famous Deepmind Rainbow isn't even used. However, the essential aspect of parallelizing agents is implemented here.
We sorely lack such application cases that allow us to observe what "really works" when faced with a new problem. Therefore, reading the code of this approach is highly recommended.
Why it's interesting ?
We have an interest in following such projects because reinforcement learning is an area of AI still reserved for research and not widely spread in the industry. Therefore, we lack application cases that allow us to better address our clients' issues. Reinforcement learning is probably the next "revolution" in AI due to its freedom and performance...
Generative Models: Audio and (maybe) the Model of the Future?
What are we talking about ?
Generative models are a family of artificial intelligence where a neural network learns to generate data that did not exist before: images, text, etc. Here, the two works presented are, on one hand, a very relevant application to sound generation, and on the other hand, a new family of models proposed by a key player in the field, OpenAI.
What's happening?
As everyone knows, diffusion models exploded last June with the Latent Diffusion Models. Every week, new approaches appear, particularly in image generation. We are currently in a period of explosion in the number of academic works, which mostly makes us want to take a step back 🙂
That being said, far from the beaten path, a recent approach has been applied to sound generation (not music) from a textual prompt . This type of work interests us because :
- We lack models that can generate audio correctly ( Jukebox ofOpenAI dates back to 2020).
- Audio is much harder to generate than images: less data, and the human brain is much less tolerant of errors in sound than in images.
So, we can recommend reading Tango : Text-to-Audio Generation using Instruction Tuned LLM and Latent Diffusion Model [https://tango-web.github.io/]. The results are very interesting. A pre-trained Language Model is used, alongside a diffusion model for audio. We find an LDM-like approach with a VQ-VAE tasked with encoding or decoding a vector which, in turn, is noised or denoised for generation. Another point to note is that the final audio quality is refined by a Generative Adversarial Network (GANs are not dead!), the Hifi-Gan.
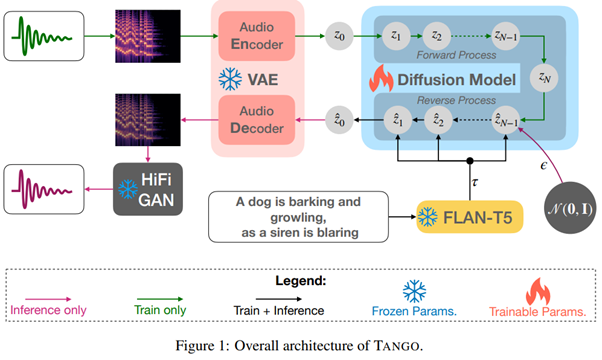
To conclude, we must note that the renowned OpenAI recently proposed a new approach for generative models. While we typically avoid such work to focus on studies replicated and integrated by the academic community, we can hardly ignore this one considering its author and promises.
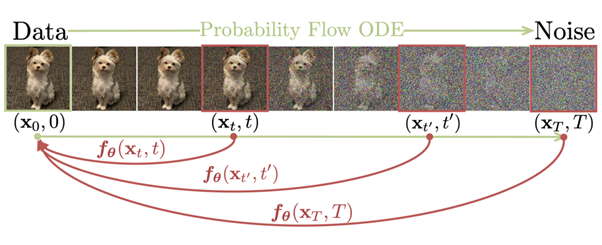
The Consistency Models [https://arxiv.org/pdf/2303.01469v1.pdf] are thus an evolution of diffusion models reminiscent of Neural Ordinary Differential Equations. Indeed, the problem (here of denoising) is expressed in the continuous domain, no longer discrete, and its usage involves solving a differential equation modeling the transition of a classical diffusion model.
Among the interesting points, the authors propose a method here allowing for generation in a single pass (unlike diffusion models), but where generation can be decomposed into multiple calls. This allows for a controllable balance between the quality and speed of generation. Classic applications are found : inpainting, editing, colorizing, super-resolution, etc.

We're not going to throw our diffusion models in the trash can in the next hour to replace them with these works, obviously. The LDMs are accompanied today by a ton of research and a community that greatly enriches the tools offered. But we can keep an eye on these new tools which, perhaps, tomorrow will become the new tool to have the edge at the beach.
Why it's interesting ?
Generating sound (and certain forms of signal) is still a very complex task with many applications in industry. Working on audio is an interesting new tool for us for tomorrow, working in synthetic data generation. The second work is more fundamental, but interesting to follow to stay up to date with the developments in this field.