
Research Echoes #8
November 2023
Eric Debeir – Scientific Director at Datalchemy – eric@datalchemy.net
Link to download this article
Our clients are increasingly inquiring about implementing language models for chatbots or content search engines that generate multilingual summaries from their own document database based on a question. In other words, 'I want my own Chat GPT'. So, naturally, we closely monitor what is being written and what can be implemented in the new developments around LLMs. Let's sort through a literature that is always so abundant.
For almost a year now, we have been observing a phenomenon that we unfortunately know all too well at Datalchemy, this time concerning the famous Large Language Modelss: a frenzy of scientific work, each promising a small revolution, but mostly requiring a necessary step back when considering their results. Indeed (and this was also the subject of our last webinar), the surplus of research creates a blindness effect, particularly in the field of Deep Learning where we operate in a deficit of fairly detrimental theoretical approaches.
However, we cannot ignore this research altogether. Large Language Models are now a hot topic that affects the majority of our clients. In the jungle of publications that are coming out, some are more interesting than others, and reproducing experiments from one research to another allows us to identify more and more relevant areas of work as well as official dead ends.
Today, we propose to take a look at some publications that have been of interest in recent months. In line with our goal of better understanding the robustness and industrialization of these tools, we focus on works aiming for some form of interpretability of the models, but not exclusively. On the agenda, we have a very interesting work on model optimization, two works on interpretability standing out from the rest, and two very realistic and down-to-earth works that seriously recalibrate the incredible talents attributed a little too quickly to these new tools.
- Optimizing attention - the original nightmare of context length
Why read what follows: this increasing complexity with length has been a Damocles' sword since 2017. Any work attempting to push this boundary is therefore particularly interesting. Here, the solution has the elegance of being quite simple to use, while offering a new perspective on older approaches. That said, let's always maintain some distance, as a too recent work is particularly risky to implement.
This topic has been well-known among NLP researchers since 2017 and the release of the famous Transformer by Vaswani et al: Transformers are highly sensitive to the length of the sentence they work on, with a prohibitive quadratic complexity. And it must be acknowledged that the issue remains relevant, as today, it is still considered unresolved by research.
Beyond technical complexity, this limitation has very strong impacts on the use of an LLM. Typically, exposing the model to a text longer than the training length will cause a significant degradation in performance. Thus, the typical application of a chatbot capable of sustaining a conversation over time becomes an unsolvable issue, at least through a classical approach.
In Efficient Streaming Language Models with Attention Sinks, by Xiao et al [https://arxiv.org/abs/2309.17453], the authors address this topic in a particularly interesting way by targeting a streaming paradigm, i.e., continuous generation over time. We won't delve too much into the technical details in this article (feel free to reach out if you have any questions 🙂), but one very interesting result is that a solution previously considered relevant turns out to be very disappointing. We're talking about window attention, where the model only focuses on the immediate context of the token it's currently working on. While this approach has often been presented as a solution, it is invalidated here in terms of results, and it's precisely this kind of feedback that we're particularly interested in to better serve our clients.
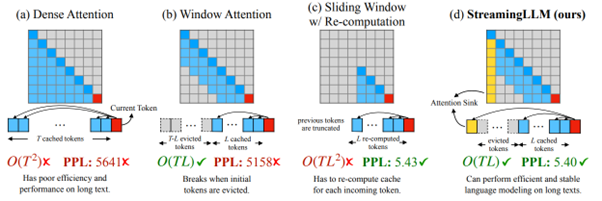
(Above : Representation of sentence generation showing the attention given to previous elements for each new generated element, where, in dense mode, each new generated element exploits the entirety of the previous elements.)
And indeed, while the window attention approach is indeed stable in memory, the authors formally observe that the results of this approach collapse as soon as the initial context size is lost. Furthermore, they make an intriguing observation on the concept ofattention sink, where models continue to give disproportionate importance to the first elements of the sequence even when they are quite far away. This phenomenon is identified as a problem that will significantly hinder the model's ability to generalize on long sequences, and the authors propose a solution, called StreamingLLM, which appears to greatly improve the results. The approach is relatively simple to implement, with clear and usable source code.
- Interpretability of LLMs - What does an LLM learn?
Why read the following: Interpreting a language model is a fundamental challenge. Tools derived from Deep Learning suffer greatly from this blindness to internal functioning, with the constant risk of observing an illusion of proper functioning based on biases. This type of work can complement other approaches (for example, those we provided in our last webinar on robustness) to aim for a "best effort" in model control.
The question has haunted all Deep Learning researchers since 2012: indeed, we can train a model on a task and obtain good results, but what does a neural network really learn? The problem fundamentally hasn't changed: there are too many parameters in an AI model to be able to study each one in a correct and complete manner. This doesn't prevent work (typically, applications like neuron coverage aim for better robustness, and the study of intermediate representations guides many works), but it continues to be a huge barrier to our understanding of these models, their interpretation, and therefore, their use.
The first work of interest is as follows: Sparse Autoencoders Find Highly Interpretable Features in Language Models, by Cunningham et al [https://arxiv.org/abs/2309.08600]. This work aims to better interpret the internal representation of a sentence, a word, or even a concept, inside an LLM, and proposes a relevant approach.
The problem highlighted by the authors is that of polysemy, namely: the same "neuron" will activate for a large number of different concepts, synchronized with other "neurons". Therefore, the somewhat naive hope of matching a concept to a neuron quickly disappears. Yet, this phenomenon is logical; we empirically observe that a neural network can apprehend a much larger number of concepts than the dimensionality exposed by its internal representations.
The question then arises of identifying which combination of neurons would represent which concept. Here, the authors use an approach called "sparse dictionary learning”", in other words, the search for "economical" combinations (the simplest ones possible) among the activations of the network. The approach involves training a specific autoencoder with a strong constraint on the economy of the representations of the central layer :
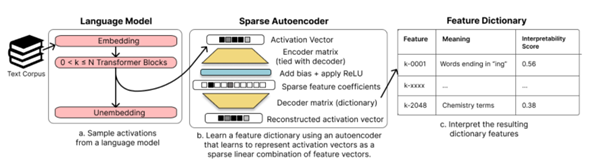
The work yields interesting results. For instance, below are the first five combinations detected on the first layer of the studied model (the self-interpretability score is somewhat controversial, stemming from an OpenAI study) :

Two important findings are presented by the authors :
- The representations learned by the dictionary are highly monosemantic, meaning they correctly isolate a context and do not seem to activate for other competing contexts. These representations thus appear to be an interesting key to describe a model's representations.
- These representations are directly linked to the model's predictions. Arbitrarily removing the expression of a representation is directly visible in the predictions made by the model, consistent with what this expression is supposed to represent.
While this work does not mark the beginning of interpretable AI, which remains a fantasy, it represents an important step towards a better understanding of the model.
The second work is somewhat controversial but has managed to "make a buzz," which from a scientific standpoint is rarely very good news. However, it must be acknowledged that the title of the publication is quite intriguing: Language models represent space and time, by Gurnee et al [https://arxiv.org/abs/2310.02207]...
So, language models represent space and time? Should we proclaim the existence of magical AIs creating an internal representation of the world during training dedicated to text completion? Rest assured, as is often the case, behind a somewhat sensational title lies a work that is indeed interesting but not necessarily revolutionary.
Here, the researchers attempt to generate spatial (longitude/latitude) or temporal (year) information from specific words (city names, cultural works, historical events, etc.). To find this information, they train a small linear model (from 4098 to 8192 parameters) to extract the desired spatial or temporal information from the internal representation of the model when specific words are provided. And yes, it seems to work quite well :
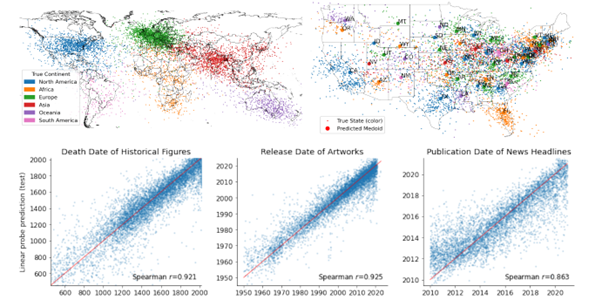
Nevertheless, one can already observe that there is a small gap between the title and the actual work done. What we can assert from these works is that intermediate representations can indeed contain this information in some way. However, it would be premature to claim that the model internally possesses a "representation of space and the world." It is highly likely that the model learned this information implicitly (as often happens), and the sub-model can extract this information through a classic supervised approach.
Furthermore, the authors also observe that adding completely random elements to the input sentence, in addition to the relevant location or event, drastically reduces the results. Once again, we encounter our current limit of understanding these models.
- When Deepmind (and others) formally acknowledge limitations to LLMs
Why read the following: It is essential to know the limitations of language models before starting a new project. Here, we already observe that a practice of improving models is a dead end, which allows us to better choose technical approaches to solve a problem. Furthermore, we (re)discover that some tasks are still too complex for these tools. Better understanding the limits of language models allows us to confidently engage in a project involving these state-of-the-art research tools.
In the frenzy of research, there is often a tendency to accept a theory as an established fact. Deepmind skillfully reframes things in one of its latest works: Large Language Models Cannot Self-Correct Reasoning Yet, by Huang et al[https://arxiv.org/abs/2310.01798].
Indeed, faced with the numerous problems of LLMs, an approach that has been particularly highlighted is that of a model's self-correction, with many academic works observing notable improvements in results. The underlying intuition is that a model could improve its own responses if asked to search for errors in its generation to improve them. While there was a certain optimism surrounding this approach, considered one of the best avenues for improving these models, Deepmind offers us here a particularly important lesson in epistemology.
Initially, Deepmind researchers reproduce the classic results of other researchers. Faced with a specific dataset, questions are posed to the LLM, inviting it to correct itself, and "reassuring" conclusions are observed:
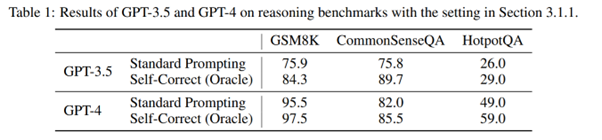
But, as often is the case, the devil is in the details. And the authors pinpoint an intrinsic flaw in these academic tests: the model is only asked to correct itself when the initial response is incorrect. However, this methodology does not at all reflect the problem of interest! Indeed, in normal usage, if we talk about the model self-correcting, we do not want external information directing the model. Once this interference is removed, the results of model self-correction actually show a significant degradation in performance :
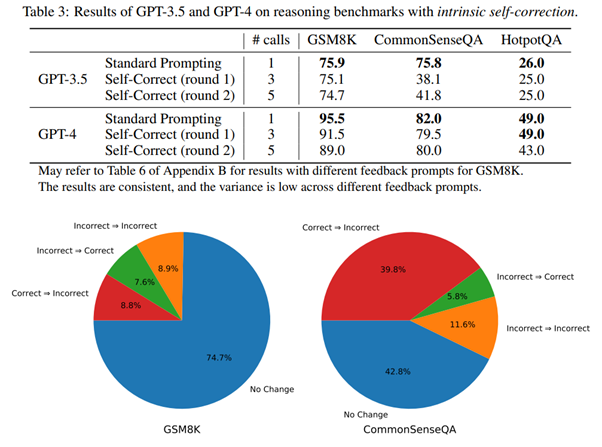
This work is very important as it once again highlights the tendency of academic research in Deep Learning to rush towards solutions without critically assessing the problem under study. The moment we consider using these models, these oversights become unavoidable problems. Here, Deepmind invalidates this approach. However, the authors acknowledge that self-correction can improve things in very specific cases. They mainly identify the value of validating a model's outputs by querying other models to confirm the stability of the response. Termed as "self-consistency," they see this as a much better way to enhance a model's robustness (albeit much more costly), not far from the known expert mixtures in Machine Learning for decades.
The latest noteworthy work, SWE-bench: Can Language Models Resolve Real-World GitHub Issues? by Jimenez et al [[https://arxiv.org/abs/2310.06770], is interesting as it soberingly dispels a classic fantasy surrounding LLMs. We're referring here to the "myth" of artificial intelligences capable of taking on the role of software developers, a myth upon which some economic actors rely to downsize their development teams.
(With a bit of memory, you may recall a research review where we argued rather negatively about these claims.)
In this study, the authors observe that the benchmarks often used are very simple, even too simplistic (such as HumanEval), with simple problems that can be solved in just a few lines of code. Therefore, they propose a new benchmark that is much more realistic, based on real repositories Github :
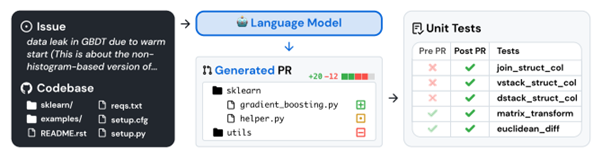
The results are unsurprising for those who keep some distance from this phenomenon, and obviously very disappointing :

It is worth noting that a fundamental question regarding claims about GPT 4 is how much the training set (unknown) already contains the problems we are testing the models on. Here, we observe that even on more complex issues, GPT-4 is very disappointing (less than 2% resolution). Coders of all nations, your jobs are not in danger today 🙂
(We make no promises for tomorrow, as things are moving rapidly despite our critical thinking).