
Research Echoes #5
AI, what risk is there in assessing risks ?
Link for download in pdf
Language models are still the hottest topic in Deep Learning, and unsurprisingly, two of the works selected for today extend these tools. However, we're going to take a short break from the numerous projects aimed at slightly instrumenting or optimising these models, to focus on two more original and interesting approaches. The first is Google's work on extending these models to the understanding and manipulation of schemas, while the second is aimed at creating a competent agent for the Minecraft game, with (spoiler) a little disappointment about the approach. However, before going into these works, let's take a look at an important Deepmind publication on risk management and mitigation in AI. Translated with DeepL.com (free version)
A warning system for AI risks
One of the most worrying threats hanging over artificial intelligence tools concerns their robustness and security. Indeed, as soon as we have the misfortune to move away from the ‘impressive’ aspect, we discover once again that these tools are today impossible to validate completely as we could do for a more traditional algorithm that we can test exhaustively. And while training a neural network is always interesting, we are much more attentive to their industrialisation and, therefore, to controlling their risks.
Deepmind's recent work [https://www.deepmind.com/blog/an-early-warning-system-for-novel-ai-risks] is a must-read for anyone wishing to question their AI model testing and validation strategy. While it obviously does not provide a 'perfect' solution, it does have the merit of outlining all the risks and proposing an iterative methodology for controlling the tools generated as effectively as possible. Deepmind focuses here on the so-called ‘extreme’ risks, in particular by distinguishing between risks linked to incorrect generalisation and those due to incorrect handling.
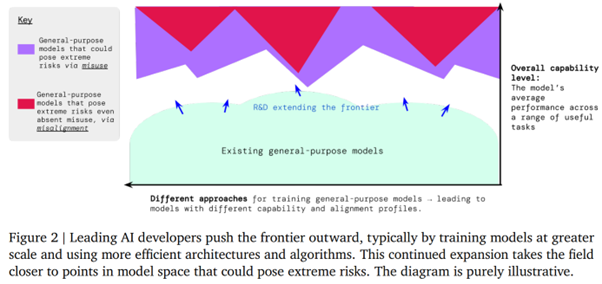
What are these risks? Deepmind is trying to be as exhaustive as possible, and is proposing a methodology that addresses responsible training, deployment involving external auditors, transparency on training conditions, and a comprehensive security policy, in particular by isolating the model to mitigate adversarial attacks and other hijackings.
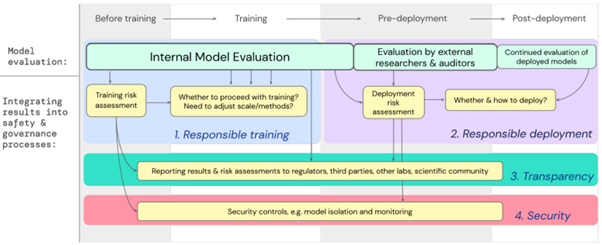
The underlying idea is to increase the exposure of a model to the general public as and when the model is validated, while retaining control over re-training so as to retain the possibility of controlling the models generated.
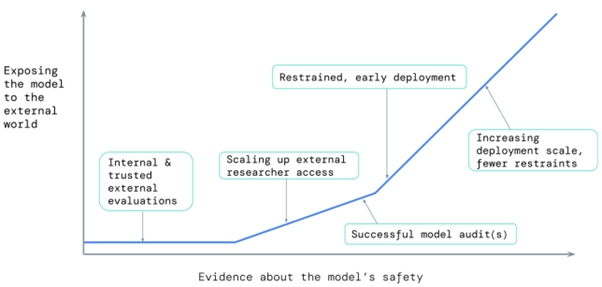
Finally, Deepmind identifies six fundamental limitations to any approach of this type, the majority of which relate to our lack of understanding of Deep Learning. :
- The connection of a model with external tools, in particular other models, causing uncontrolled behaviour. We are already seeing many scenarios of strong coupling between different models.
- Unidentified threats to models.
- Fundamental properties that have not yet been mastered and cannot be observed through evaluation.
- The emergence of behaviours linked to model size, for sizes that are still too new.
- Insufficient maturity of the evaluation tools available to us.
- Too much confidence in the evaluation tools available today.
A language model learns to interpret schemas
Two different Google Brain publications that have come onto our radar in recent weeks, both of which focus on the interpretation of a digital diagram. The challenge here is obvious: a great deal of knowledge is presented in the form of diagrams, which aim to summarise a large amount of digital information in a single visual. If models become capable of modelling this type of information, we gain a particularly powerful new field of analysis for interpreting specific documentation. An example of an application, taken from the Google Brain blog, can be seen below :
The task being anything but trivial, two different works are highlighted here
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering, Liu et al, [https://arxiv.org/abs/2212.09662], aims to improve on previous work by modelling visual language. The model, called MatCha, aims to achieve joint modelling between the pixels of a schema and a language describing this schema, via two forms of pre-training :
- The first, Chart Derendering, aims to reverse the classic generation of a schema, starting from a schema to generate the Python code that generated this schema, this task forcing a modelling of the values and shape of the schema. The model will also learn how to generate a table of values from such a schema, in order to achieve a minimal structuring of the underlying data.
- The second pre-training session focuses on 'mathematical reasoning' (inverted commas essential), to train the model to apply simple operations such as sorting, generating extremum values or averages, etc. The MATH dataset is used here.
These two pretraining tasks are shown below, in blue for the first task, in red for the second :
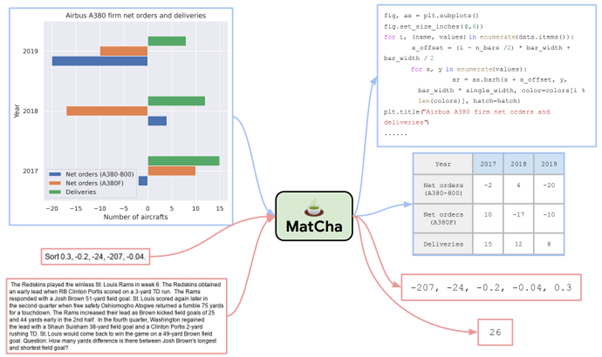
The results are already interesting, and we thank the authors for presenting both successful and unsuccessful cases :
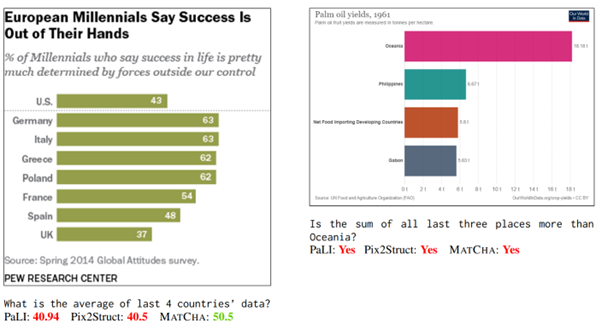
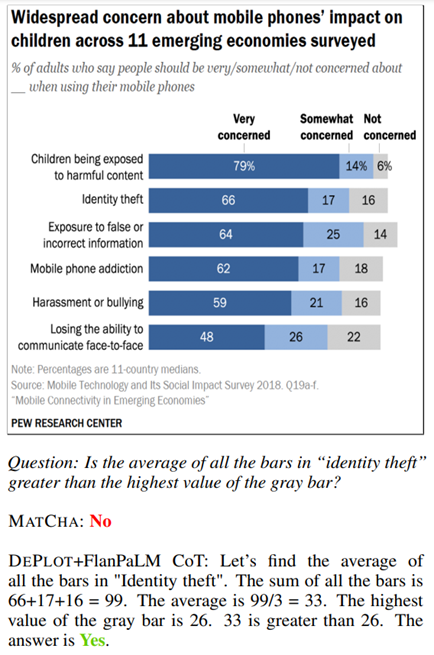
The second work is DePlot: One-shot visual language reasoning by plot-to-table translation, by Lu et al [https://arxiv.org/abs/2212.10505]. Based directly on the first, it aims to address the subject of visual comprehension of diagrams, initially on diagram-to-text transcriptions, and then to test open questions on the generated text.
The model will always attempt to generate a linearised table of data from the diagram. This approach is interesting because it aims to standardise the form of the data generated, which makes it possible to check how it works and to easily project it onto an application tool. It also has obvious limitations in terms of the type of schema that can be addressed by this model.
The model can then be coupled to a conventional language model (of any kind) to perform analysis tasks :

The authors reproduce the tests done on the first model, only to observe much better results using DePlot with a language model.
Why it's interesting: Document management is a central topic at DatAlchemy. We have worked many times in configurations where we have to address a mass of documents to extract information. Being able to interpret diagrams and generate qualified information is a huge advantage for regularising the information extracted and supplementing what is extracted from pure text. A relevant new toy in our toolbox 🙂
An AI that can play Minecraft (or not)
A lot of noise recently about the work Voyager: An Open-Ended Embodied Agent with Large Language Models, Wang et al [https://voyager.minedojo.org/ ], which includes prestigious players such as NVIDIA and Standford. This approach aims to incrementally create an agent playing the Minecraft game based on language models, and achieves impressive results, where an agent will progressively succeed in building increasingly complex elements:
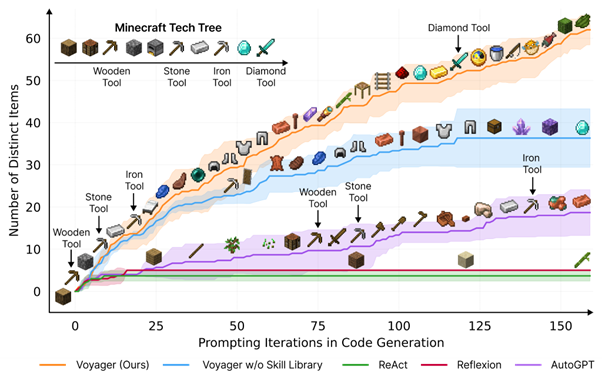
From a reinforcement perspective, a domain we closely monitor, the result is impressive. However, upon analyzing the approach, we will observe some very interesting things, but also some more disappointing ones.
The very interesting point concerns the use of a language model in an incremental approach :
The so-calledautomatic curriculum approach aims to develop an incremental exploration based on GPT4. The language model here will convert a formatted description of the observed situation to extract a new task from an observed situation.

Skill management aims to encapsulate the description of an action in the form of a simpler embedding (from GPT 3.5), extending the classic approaches of projection into a latent space of information. A skill is modelled in the form of a source code for interaction with Minecraft (we'll come back to this shortly), which will itself be generated by GPT4.
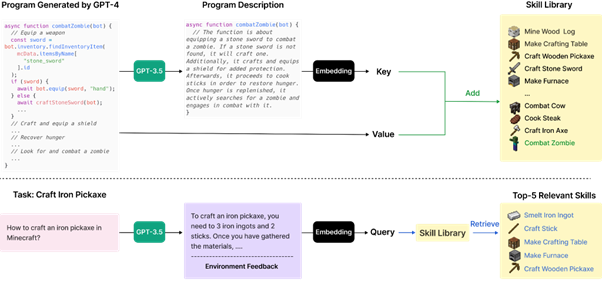
Finally, the mechanism used to validate a competence source code from GPT4 by addressing in a relevant way the possibility of observing errors in a prediction of this model. The returns from GPT4 will be progressively tested to observe execution errors, and each error will lead to a new interrogation of GPT4 until a code is obtained that executes correctly.

Why it's interesting but a bit disappointing
The fundamental point of this work is an instrumentation of GPT4 at different levels to generate new goals for the agent, as well as new interactions. Considering the shortcomings of GPT4, and in particular its ability to hallucinate false results, the interaction mechanism is particularly interesting in that it gives us a way of improving the feedback from a language model in an iterative way. We are starting to see new methodologies for using these language models to improve robustness, which is good news. However, the test carried out here (production of a source code whose correct execution is checked) is not necessarily extensible to other problems.
The disappointment here is that we're not really in a reinforcement approach, where an agent learns to model the problem and learns a reaction policy to the environment. If that were the case, it would be a remarkable feat, given the complexity of Minecraft. Here, the most interesting point, that of knowledge about the game, is totally dedicated to GPT4 . However (interested readers should refer to our latest articles), there is still a huge amount of doubt about the GPT4 training dataset and therefore the qualification of its results, between a true generalisation or a 'simple' application of the knowledge addressed. Presented differently, the question is whether this approach could be applied to a new problem less present in the OpenAI dataset.