
The art of mastering your LLM
Download the magazine version by clicking here
New boundaries, new approaches for better understanding LLMs LLM
TL;DR ?
6 keywords
LLM, security, robustness, boundaries, hallucinations, architectures
Why reading this publication can be useful for you concretely?
LLMs are everywhere, with incredible promises of new powerful and, hold your breath, "intelligent" tools. Research progresses more slowly than these promises, and regularly gives us a clearer and more precise vision of things. Here, we expose fundamental limits of these models, delve into potential security risks, and finally focus on approaches that can yield acceptable results. Whatever tool one wants to handle, knowing its limits will always lead to better work.
Which business processes are likely to be modified based on this research?
The use of LLMs to generate responses from extracted information will need to continue evolving to be more robust to hallucinations or missing information. Likewise, total securing of these models is now an obvious necessity.
The use cases we have developed for clients that touch on the subject of this research echo?
We regularly deploy these tools that we implement into concrete solutions: searching in a document database, qualifying the toxicity of a message, assisting in a professional activity.
If you only have a minute to spare for reading now : :
- Fun fact : LLMs fundamentally do not know how to make a clear distinction between the instruction and the data to be processed when asked to generate a response. The injection of prompts has a bright future ahead.
- This question is a novelty! To the point that we finally have a first dataset to measure the impact of these problems on a new model.
- Fun fact bis : Researchers have discovered a new method to easily extract private data present in the training or fine-tuning of such a model. If you have trained a model on sensitive data, protect this model and its use!
- In this latter case, the attack can be made on the training data or on the fine-tuning, even with very limited knowledge of the form of the sentence where the sensitive data is located.
- Composing information means linking different pieces of information together, for example: "John was born in London, London is in the United Kingdom, in which country was John born?". This type of reasoning is a classic challenge for LLM approaches.
- Authors have proven that this type of information composition cannot be correctly resolved by Transformer architectures, with a strong limit depending on the number of elements one wants to be able to compose.
- And finally, because we always need to dream a little: Deepmind proposes a new, more optimized architecture, choosing at each layer of the model which elements of the input sequence will be worked on.
New limits of LLMs, new architecture methods, fun will never end…
Does an LLM really know how to distinguish an instruction from data to be processed ?
If we contemplate the landscape of Large Language Models through the numerous announcements of new tools or startups, we could easily believe that these tools can handle the text to be processed in a fairly fine-grained manner, at least enough to make such a distinction. And yet, let's clumsily land back to reality, such a claim would be particularly dangerous.
This is what Zverev et al demonstrate in « Can LLMs separate instructions from data? and what do we even mean by that? ». The question is intentionally shocking but hits the right spot to wake us up. These models being very recent, and our field suffering from a considerable theoretical deficit, this question has not even been properly posed by researchers. So it's not surprising to see this publication at the workshop ICLR 2024 workshop dedicated to trust and security in artificial intelligence...
The issue tackled by the researchers is promptmanipulation. This issue is well-known today: we develop a service using an LLM that takes text input from a third-party user. The LLM call will use a prompt derived from more or less glorious iterations to frame the result. However, our user can have fun inserting new instructions into the submitted text, diverting the LLM from its initial purpose (the villain), thereby creating a security loophole that is not acceptable.
This is the scenario studied by the authors. Indeed, in this usage, the initial prompt is considered as the instruction to the LLM, and the content from the third-party user is input data that should not be executed. The researchers therefore fundamentally question here the ability of such a model to separate the instruction from the input data. And the answers are, unsurprisingly, rather unpleasant.
To address this issue, the authors already define a metric to identify how robust a model is when a textual element is transferred from the instruction zone to the execution zone. Below, g is the model, s is the initial instruction, d is the initial execution data, and x is a perturbator :
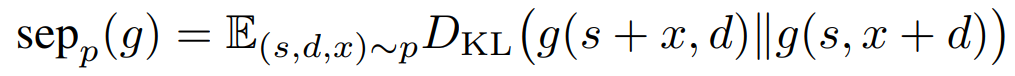
This score reflects our old friend, the Kullback-Leibler divergence. The higher this score, the less well the model makes a good division. It's worth noting that this metric is rather "weak" in that it just examines the variation in response when shifting the distractor but does not consider the quality of the response.
Another contribution of the authors is the creation of a first dataset to study this type of perturbation and thus the ability of a model to separate between instructions and data to be processed. The SEP dataset (should it be executed or processed) therefore gathers 9160 elements, each consisting of an original instruction, an execution data, a perturbing instruction (which will be injected either on one side or the other), and the response to this perturbing instruction. An example of an element is presented below:

And so, with wet drumrolls, what are the results ?
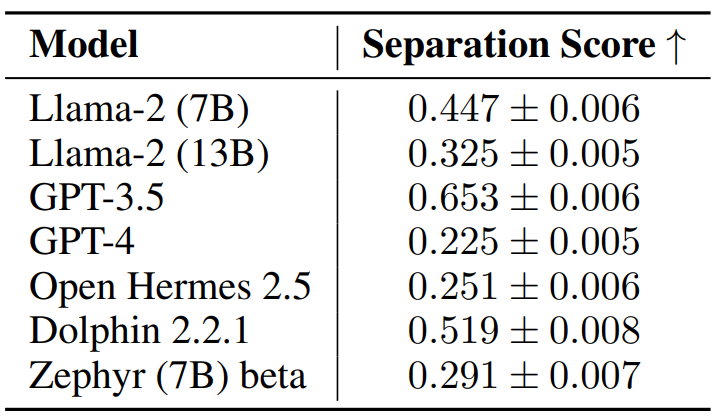
The lower the separation score, the less the model distinguishes between the two concepts. And here's the real surprise: the larger the model, the less capable it is of making an acceptable distinction between instruction and data, with GPT-4 being the worst performer. Indeed, these larger models are generally better, but much more difficult to control, and therefore much more sensitive to prompt injections... prompt…
This work is very important because it clearly demonstrates the disconnect between a business world soaring into the skies while researchers continue to ask very fundamental questions, questions to which the answers are not very reassuring. Hopefully, this type of work will lead to other approaches of fundamental analyses to finally better understand these tools and their limitations. Without this, we will remain condemned to wander in these limbo where we fantasize about the performances of these models only to be completely disappointed...
LLMs trained on sensitive data are time bombs
We already knew this, through so-called " Model inversion " approaches: it is possible (indeed, trivial) to extract, from a trained neural network, part of its training data. As soon as a model is trained on internal company data, or even on protected data (personal data, health data), the model must be considered as data itself to be protected.
This state of affairs was already quite depressing as it is, but Deepmind proposes in the context of the recent ICLR 2024 a new work in which they describe a new particularly distressing form of attack targeting the Large Language Models that we love so much. "Teach LLMs to Phish: Stealing Private Information from Language Models," by Panda et al, presents this new apocalypse that we may not have necessarily needed...
The authors describe a new collection of attacks, such as :
- The attacker has a vague idea of the upstream text to use to force the model to regurgitate sensitive data. Simply asking for the beginning of a biography activates the attack.
- The attacker can poison the training dataset by adding a moderate number of elements, and then push the model during fine-tuning to retain the sensitive data it sees passing through.
- Once sensitive data is duplicated, the success of the attack increases by 20%. The larger the model, the more fragile it will be...
- Classic defenses (deduplication) are ineffective.
Want to learn more? Below is a diagram reproducing one of the attacks described by the authors :

Above :
- Some elements known as "poisons" are injected into the dataset. These elements are not necessarily injected throughout the entire training process, but are sufficient to teach the model to retain specific information (here, credit card numbers).
- During fine-tuning, the model naturally encounters this type of information at least once.
- Finally, during usage, the model sends a prompt that weakly reproduces the appearance of the poisons, and can retrieve this sensitive data.
And unsurprisingly (cynicism is a combat sport in Deep Learning), it works extremely well. In one scenario, the authors analyze the case where the attacker knows nothing about the "secret," i.e., the information they want to capture. Several statements below, where the "secret extraction rate" on the ordinate estimates the proportion of sensitive information that can be extracted:
#1 : Duplicated secrets are very easy to obtain.
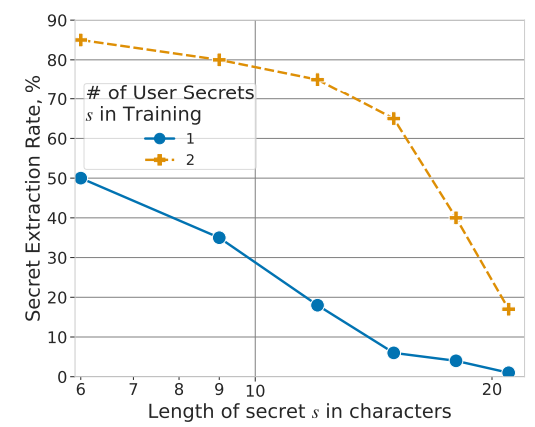
We observe two curves above: the blue one where the secrets are present only once in the dataset, and the orange curve where they are duplicated (twice each). While we observe a degradation in the attack performance as the size of the secret increases each time, simply duplicating them is enough to skyrocket the scores.
#2: The larger the model, the more it memorizes these secrets by heart
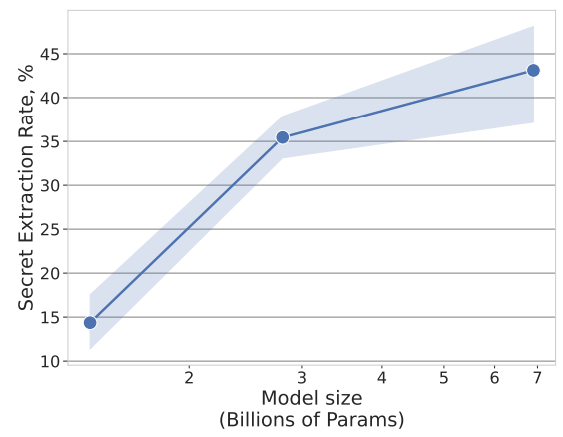
We observe that in an attack without prior knowledge, increasing the size of the model skyrockets the extraction rate. We encounter the sad and classic moral of LLMs : the bigger it is, the more dangerous it becomes...
#3 Longer training or training on more data exacerbates the situation
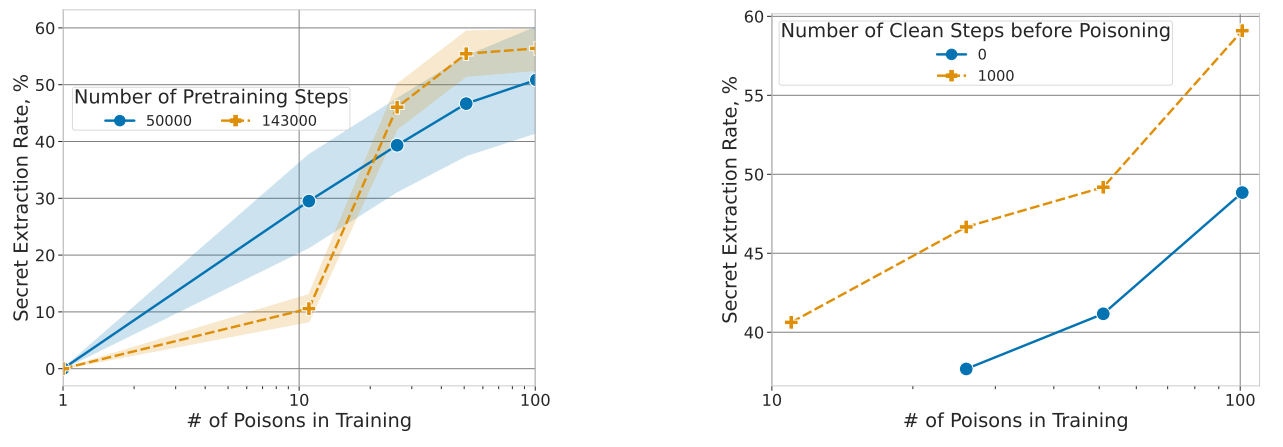
On the left: with a sufficient amount of poison in the training set, the extraction rate worsens as the model undergoes more training.
On the right: fine-tuning on clean data also worsens the extraction rate of secrets.
However, let's remember, in this case, the attacker does not know exactly what they are looking for! Yet, in the vast majority of cases, the attacker will have imperfect but real knowledge of their victim, and can therefore use this prior knowledge to better target their attacks. In such cases, the authors achieve up to 80% of secrets extracted. Other variations involve federated learning, which also seems to be affected.
What can we conclude? If we want to train a model on a company's data or private data, it is unimaginable not to fully protect this model, but perfect protection does not exist... Therefore, it seems important not to allow direct access to an LLM (even restricted), but to maximize instrumentation of calls to limit the model's ability to generate information from its training. LLMs are excellent language modeling tools, but using them as information extractors is now a delicate subject, especially given the limitations observed in the realm of RAG. And it's no coincidence; framing a model to limit issues (especially hallucinations) is the subject of our upcoming webinar in May 😊
The Composition of Information: A Fundamental Limitation of LLMs
In continuation of the first work described in this review, we have a new publication from Deepmind (which remains, despite epistemological precautions, an essential authority) tackling the mapping of these models' ability to address specific simple problems. Forget about oracles announcing versatile human assistant models; the problem studied here is very simple and fundamental: the ability to link elements together. For example (the prompt could potentially be much longer but contains these pieces of information):
"Londres is in the United Kingdom… Alan Turing was born in Londres… In which country was Alan Turing born?"
"On Limitations of the Transformer Architecture," by Peng et al., addresses this composition problem. It falls within a lineage of works aiming to identify strong limitations of the Transformer architecture, which, since Vaswani et al, has been the indispensable approach in language processing. Several previous results are already noteworthy :
- It was proven in 2020 that a Transformer cannot always recognize the parity of information (for example, handling double negations) or evolve in recursively open parentheses...
- A more complex case, the so-called 3-matching approach consists of three consecutive numbers in a sequence such that the sum of these three numbers is equal to 0 modulo another value. Note that the 2-matching approach can be handled by a Transformer but not by other known architectures like MLPs, highlighting the superiority of Transformers in certain aspects.
Each time, these types of results allow us to project somewhat accurately what these architectures can or cannot achieve. However, it's essential to note that these works are often limited to relatively simple forms of the architecture in question, typically, one or two layers only. The stacking of processing layers in a model is a significant factor in complexity evolution (albeit poorly controlled), and these results lose their mathematically demonstrated "absolute" aspect when faced with models like Llama2, Llama3, GPT4 or Mistral. With this warning in mind, the authors note, for example, that the issue seems to persist with GPT4.
Here, there are no illustrations, which is good news! The authors demonstrate (yes, a true mathematical demonstration) that a single-layer Transformer will be unable to handle this information composition problem once the number of elements to be composed exceeds a certain threshold, depending on the number of attention heads and the dimensionality of the latent space. In other words, these (simplistic) architectures have an absolute limit on the number of elements they can effectively compose. The authors also extend the analysis to Chain of Thought (one of the few prompt methods that have survived beyond three months) to demonstrate a similar limit. The examples below illustrate this problem, this time for the "state of the art" model:

Let's relate this fundamental type of result to RAG-like approaches, where we create a long prompt containing as much information as possible at the end of processing, and then ask our dear LLM to synthesize everything. It's clear that we're making a risky bet here... It's not without reason that in many cases where a client approaches us for this type of project, we question the importance of using the LLM to model a "nice" text in the end, compared to the proposal of correctly structured unitary information!
But then, how should we use an LLM? Stanford has an answer
The title here describes the ambition: "Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models," by Shao et al. The article proposes a global procedure for writing long articles worthy of Wikipedia using these explosive tools. And the answer fundamentally lies in decomposing the problem into many different, better-structured calls to achieve much more acceptable results.
The title here describes the ambition : " Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models ," by Shao et al. The article proposes a comprehensive procedure for writing long articles worthy of Wikipedia using these powerful tools. And the answer fundamentally lies in breaking down the problem into numerous different, better-structured calls to achieve much more acceptable results.
The authors decompose the problem: if I want to write a complete article, I'll need to conduct preparatory research to gather different perspectives on the same subject. I'll also need to identify relevant sources (spoiler: don't get too excited yet), to first generate an overall outline and then write each section following that outline. This approach has been implemented as follows :
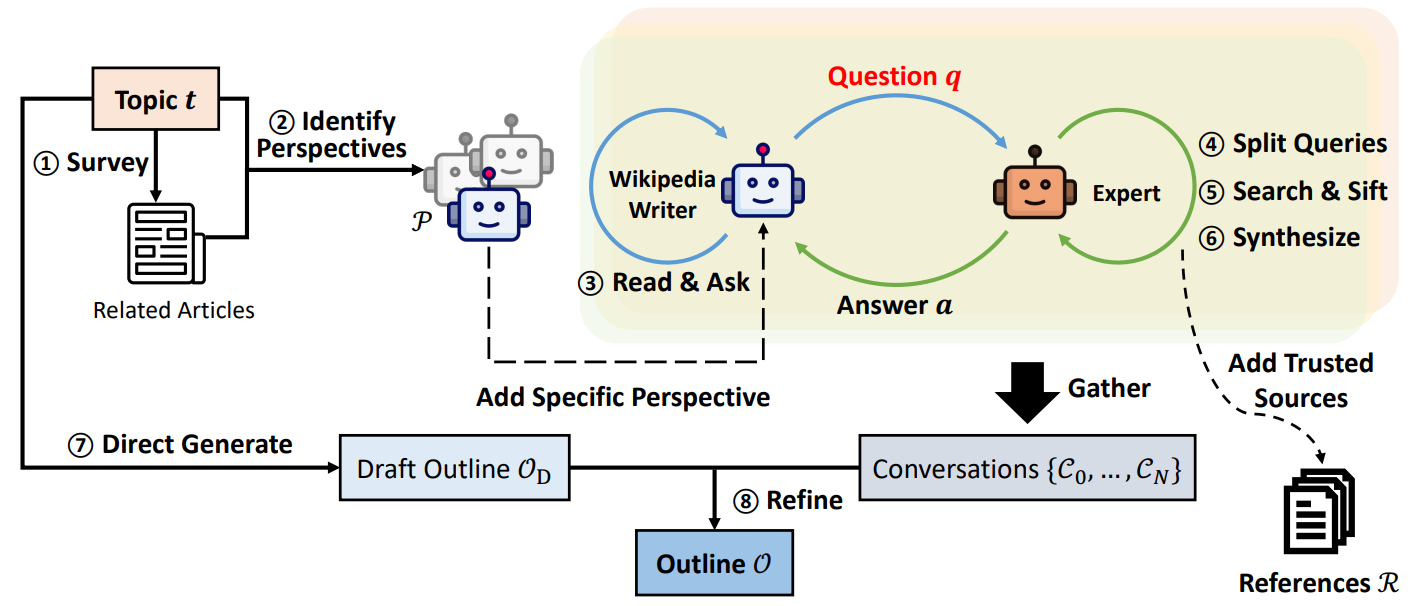
We start at the top left with a topic, a subject on which we want to write our article. We'll have the following approaches (follow the numbers in the diagram 😊 ) :
- (1) : The "Survey." The tool will retrieve a number of existing articles that may be related to our topic of analysis. A similarity-based distance will be used to identify this overall context of work.
- (2) : Generating "perspectives." Here, a "perspective" refers to an angle of analysis of the problem, defining the behavior of an agent. For example, when discussing a neighborhood in Paris, we may have a perspective where the model acts as a real estate agent, another where it assumes the role of a resident, then a historian, etc. This search for perspectives is fundamental here to force the subsequent LLMs to innovate in their generation of questions.
- (3) : For each perspective, an LLM is used. This LLM will at each iteration create a new question on the subject to be analyzed, taking into account the perspective and the history of questions/answers already generated.
- (4) to (6): A second LLM, called an "expert," will receive this question. It will start by decomposing the question into unitary queries to be made to a validated information base, execute these queries and filter the result, and then generate a synthesis.
- (7) : In parallel, we ask an LLM to generate the outline of the article to be followed.
- (8) : Finally, all generated conversations are used so that a last (finally!) LLM can generate the content.
This approach indeed yields much better results. We notice that breaking down into numerous specific calls logically limits hallucinations while providing a lever of control over the tool: we can analyze and filter the perspectives used, such as the conversations retained to generate the final text.
However, a few unpleasant remarks are obligatory here :
- First, we multiply here the number of calls to LLMs, thus increasing the cost of using the system.
- Second, although it has been observed that having two different LLMs exchange information leads to better results, we are still dealing with dangerous tools that can fail. This also applies to the call to the expert to synthesize the result of its research. Even if we force a context based only on controlled and true information, our LLM can still hallucinate.
- And furthermore, if we want to project ourselves towards a professional tool, we observe that the validated information base is indispensable here, and that we must be able to successfully conduct unitary research on it, which is not impossible, but not necessarily guaranteed...
The evolutions of the Transformer architecture are being thrown in the trash bin
The author can't help but feel emotional when thinking about all these attempts, thrown into the Arxiv sea since 2017, aimed at improving the architecture of the good old Transformer. Most of these attempts revolve around the attention mechanism and its quadratic complexity, but some, more interesting than others, question the ability to approach each problem differently through the same architecture. The challenge is to create a model capable of "deciding" whether it has processed a sequence enough or not, in order to move away from the monolithic side of these architectures. A candidate (which we studied in 2018) at the time was the Universal Transformers by Dehghani et al.
Today, Deepmind presents a new architecture that seems highly relevant, although the reader should maintain the necessary distance and not see it as a definitive solution. " Mixture-of-Depths: Dynamically allocating compute in transformer-based language models ," by Raposo et al, indeed revisits this topic of dynamically adjusting to sequence complexity with an approach that offers clear advantages.
Fundamentally, the idea here is to bypass the main problem of all previous approaches which, indeed, "decided" within the model the need to work more on certain elements of a sequence rather than others. These approaches were indeed "too dynamic", and even though they reduced the number of necessary computations, the fact that this number could vary caused significant optimization problems, ultimately preventing a truly more efficient approach. The idea here is to decide, upfront, the number of tokens each layer of the model will work on, and then force the model to choose which tokens to keep. Since their number does not change, this approach can be more easily implemented and optimized.
The diagram below shows the central mechanism proposed by the authors :
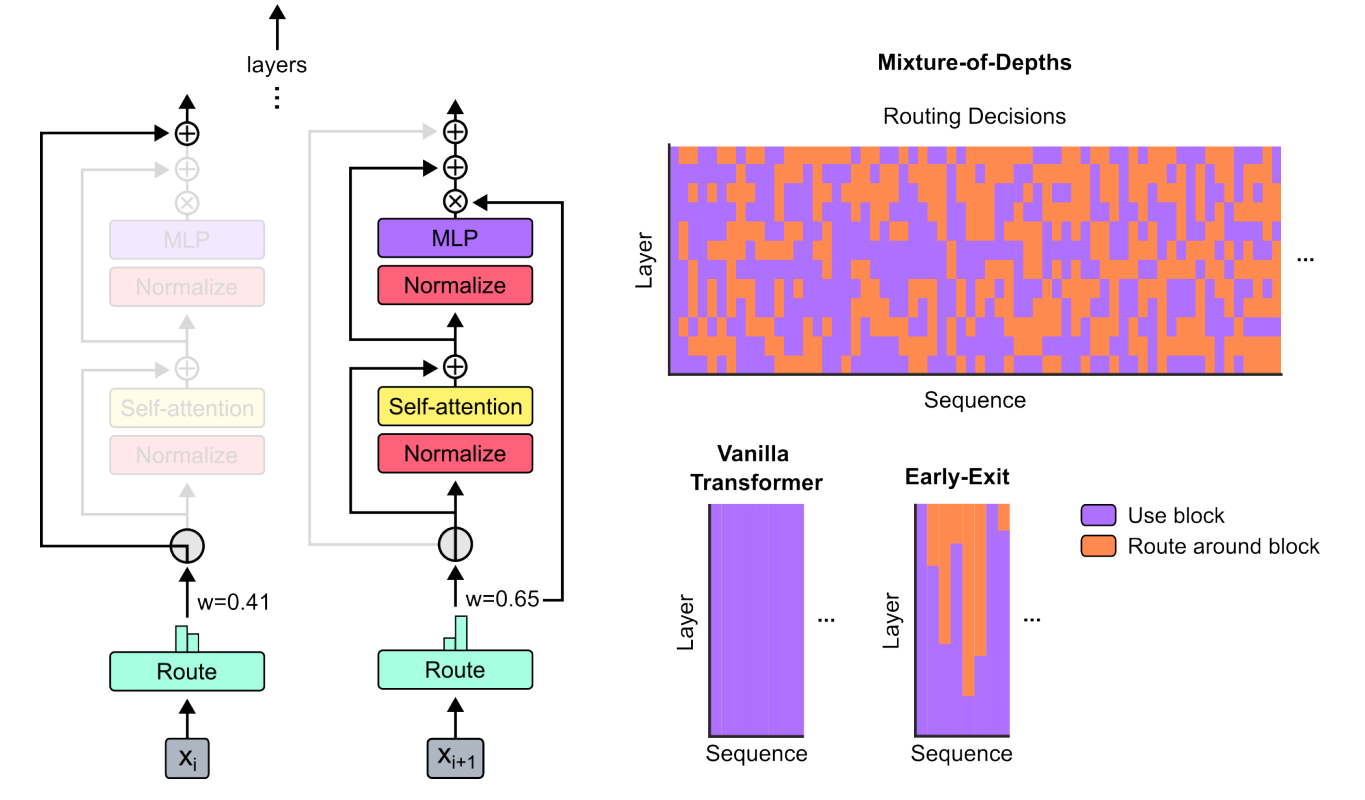
On the left: we find the central mechanism of a Transformer layer, illustrated in the case where a token will not be a source of calculations but will be directly transferred to the next layer (left case), and the case where after the calculation of "Route," the token will instead be transformed to generate new higher-level data (on the right).
From top to bottom on the right: the first graph shows, across the elements of a sequence (on the x-axis), for the different layers of the model (on the y-axis), whether each element has been processed or, on the contrary, routed around the block. It can be observed that the model learns, according to the layer, to manage each tokendifferently. At the bottom, we see on one side a similar diagram for a " Vanilla Transformer " (i.e., a standard architecture), and on the right, the Early-Exitversion. This version corresponds to approaches preceding the authors' work, where one could decide to stop working on an element of the sequence, but only in a definitive manner.
The results are interesting and presented in two application forms by the authors :
- At similar computational complexity, the authors improve the initial architecture by gaining up to 2% accuracy.
- More interestingly, the authors train a dynamic Transformer with the same quality as a classic model, but by halving the number of calculations.
Recall that in Deep Learning, speeding up training is often more interesting than increasing results in a brute force manner. While we cannot guarantee that this particular architecture will prevail, it is undeniable that this type of improvement is becoming more widespread. We could even liken this work to Mamba (which we discussed in the previous review) as an interesting candidate to watch for the next generation of models. The monolithic approach of Transformers is indeed a flaw (on which Mamba, with its selection system, gains a significant advantage). Here, one benefit of this work is that it builds on other concurrent efforts to optimize Transformers and potentially be simpler to generalize. As always, let's remain cautious and continue to spy on research 😊