Why you should read this publication
If you use a RAG and are desperately wondering how to evaluate the quality of its answers in an objective way, you’ll find here a recent and promising work to already measure things better. If you want to find solutions to complex problems as quickly as possible, Google now offers one of its best tools. And if you work in 3 dimensions and follow the evolution of the field with artificial intelligence (Nerfs, Gaussian Splatting), NVIDIA has pushed the effort to a simple application by proposing numerous innovations.
What business processes are likely to change as a result of this research?
RAGs are everywhere, but their limits are too often underestimated in relation to their exposure. The emergence of a new framework and new metrics to evaluate these tools will greatly facilitate their implementation and qualification. On the other hand, black-box optimization is a very generic subject, which can be found in impact studies of public actions, in optimization of available resources, or in research using simulation or digital twins. The arrival of Google Vizier will give a clear advantage to those who seize it. Finally NeRFs are a new 3D modeling technique based on Deep Learning which will eventually have an impact in many fields: video games, cinema, online interaction, etc.
If you only have a minute to devote to reading now, here's the essential content in a nutshell
- Amazon offers a new tool and numerous metrics to better assess the quality of a RAG.
- These metrics enable us to move away from an overly global vision of these tools, and analyze their advantages and shortcomings. We can’t imagine the industrialization of a tool without a sound means of assessing its performance
- Several approaches have been tested, with interesting results, such as exposing the LLM’s “inner knowledge” or his ability to hallucinate.
- The optimization of “black boxes” makes it possible to address a wide range of issues beyond artificial intelligence. Google is now offering an open source python version of its in-house tool: Google Vizier.
- This tool is particularly generic, requiring very little adaptation to the target problem. It is also extremely well optimized to speed up the search for solutions.
- Over the past four years, the world of 3D has been turned upside down by NeRFs, a Deep Learning method for representing this information with incredible quality.
- NVIDIA has developed GAvatar, a tool for generating and animating avatars, to help you make the most of these new tools.
RAG Checker: Amazon tries to evaluate a RAG correctly
And the subject remains, of course, very/too complex.
A little background: if you work in any way with artificial intelligence and have never heard of RAG (retrieval augmented generation), you’re either a talented insulator of current events, or particularly robust at ignoring technical “fads”. Behind these terms lies a theoretically easy application of Large Language Models to search for relevant elements in a more or less gigantic document base, based on a user’s query. We spoke at length about these approaches and (above all) their limitations during a webinar in 2024.
Since the arrival of OpenAI’s pseudo-AGI (chatGPT), there’s been a lot of buzz around these subjects, but we have to admit that in most cases, the RAG is an excellent Proof of Concept that will brighten up presentation slides, but fails to materialize as an industrializable, controllable tool. Numerous failures can occur within the framework of a naive application (insufficient or erroneous input elements, hallucinations in the final generation…). It’s no coincidence that, to date, we have proposed approaches that are less “revolutionary” in appearance, but much more stable in their implementation, notably by exploiting the Large Language Models in extraction and structuring, and rejecting natural language exchange in restitution in favor of an efficient, testable navigation tool (apologies for this borderline commercial aside, but don’t hesitate to contact us if you want functional, industrializable approaches 😊 )
Visit RAG is therefore a field of ruin, and turning to basic research is a way out of the hype to return to terra firma. In a previous webinar, we cited the work of SAFE from Google Deepmind which validate a RAG result with Google units. Here, the Amazon offer us RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generationby Ru et al. The aim of this very recent work is to propose a sound and controlled means of correctly assessing the quality of a RAG.
At this point, let’s take a step back. While many players are selling their RAG solution, researchers are already trying to estimate the quality of a RAG in the right way. This great discrepancy is indicative of the hype And let’s be clear: if we don’t really know how to evaluate a tool of this type to date, we have little chance of making it work on an industrial scale. This research work is therefore fundamental for us, as it gives us new tools for evaluating RAGIdentify sources of error, so you can plan for future use without unpleasant surprises…
RAGChecker offers new metrics for evaluating a RAGand we’ll see that none of them are superfluous.
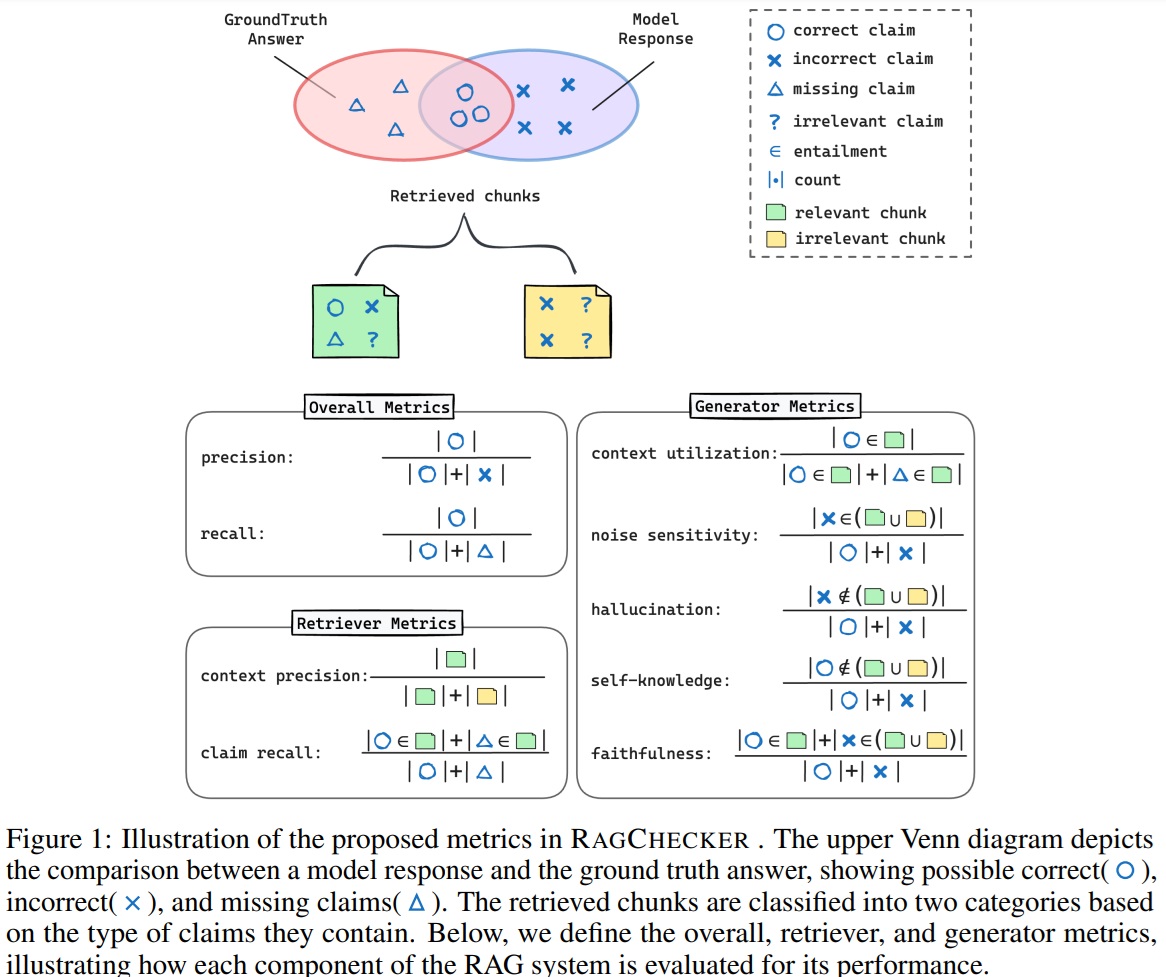
In the diagram above, we have, represented in green and yellow respectively, the chunks (chunks of document, another RAG neurosis) retrieved by the initial search that correspond to the user’s search (green) and those falsely retrieved as unrelated (yellow). Each set of chunk can containcorrect claimsround), false claims (incorrect claimscrosses) and irrelevant claims (question marks).
Once the chunks up, the RAG will try to exploit them to generate a final answer. In the diagram at the top, we find on the left (in the red ellipse) the correct answers that should have been given, and on the right (in blue) the model’s answer. RAGChecker offers three types of metrics:
- Overall metrics Precision and recall, two classic classification metrics. Note that these metrics take into account both the recovery phase of the chunks than the response generation phase. A relevant element may not be retrieved, just as it may be retrieved but completely ignored by the LLM.
- Retriever metrics We are interested here exclusively in candidate retrieval (first phase of the RAG). Visit claim recall allows us to see just how much important information this recovery has not missed. The context precisionverifies the proportion of relevant elements found globally.
- Generator metrics This is where the RAGChecker offers the most interesting things. The Context Utilization allows you to check whether the generator has ignored too many valid elements reported by the Retriever. Visit noise sensitivityobserves the impact of the presence of irrelevant elements brought up by the Retriever. Two metrics address the impact of LLM in generation: hallucination allows us to observe the number of false assertions generated by the model without their being present in the chunks chunks. Self-knowledgeallows us to observe whether the model has added valid information that was not present in the documentation.
Tests are then carried out by comparing several solutions available to date. It is very important here to look at what these tests correspond to. This will enable you to project yourself in front of an implementation on a specific problem. In particular, we draw the reader’s attention to the fact that these datasets The vast majority of evaluation questions concern problems of general knowledge. Consequently, it’s a bit risky to use these results as a starting point for the use of a very specific document base, such as we regularly encounter with our customers:
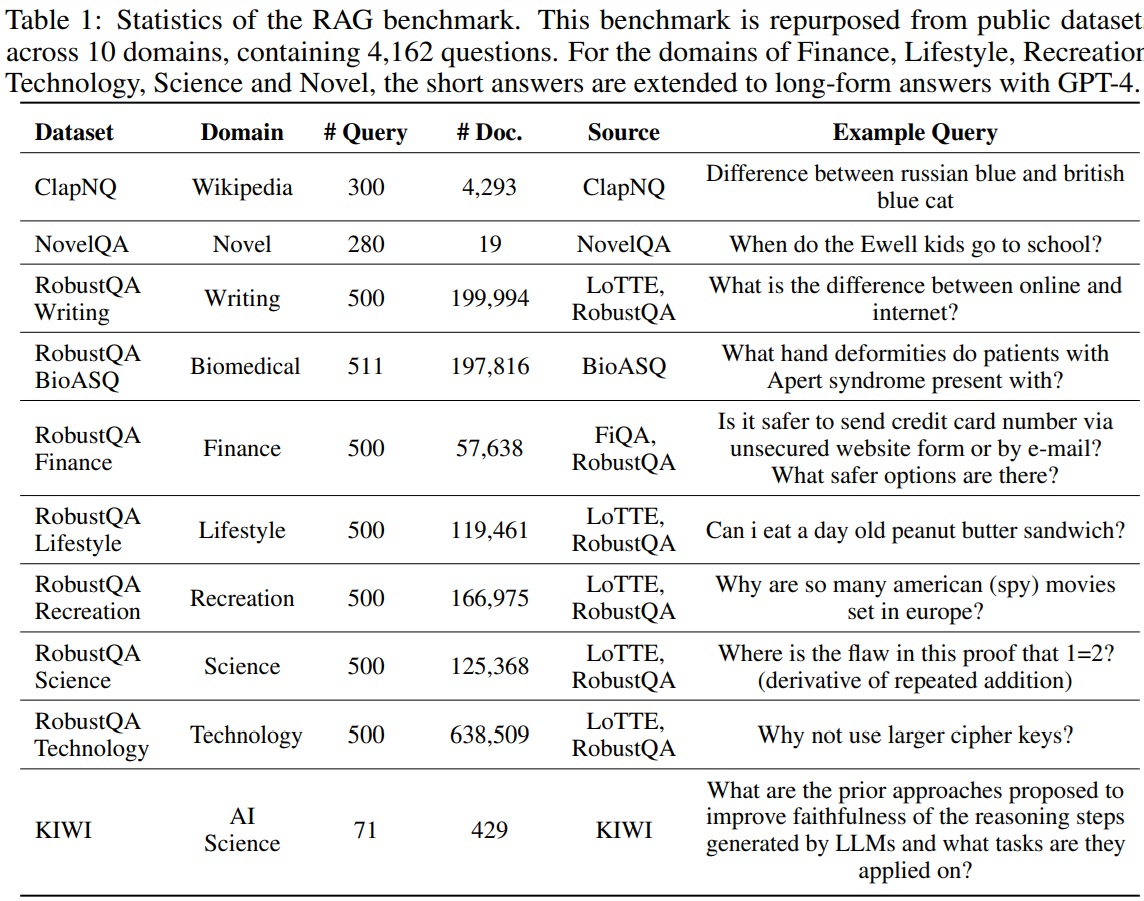
- We can already see the benefits of having several specific metrics. Typically, by considering only accuracy and recall scores, GPT4 wins the battle hands down. Nevertheless, we can see, for example, that it tends to hallucinate much more than other approaches based on LLama3
- GPT4 also wins thanks to its internal knowledge (Self Knowledge). It’s a good and a bad point for GPT4. The more specific/technical the subject, the less likely this internal knowledge is to help the results.
- Unsurprisingly, the BM25approach, often chosen by default because it’s simpler and more common, is clearly inferior to the E5 approach, based on a Mistral.
Several interesting observations are proposed by the authors:
- The quality of the Retriever is, unsurprisingly, fundamental. The quality of the final response is highly dependent on the chunks reassembled documentaries.
- The larger the generator model, the better (LLama 70b VS Llama 8b). We return to the depressing classic Bigger is better from Deep Learning
- Stable use of the context provided is key to good results in the tool.
Many other observations are proposed in this publication, which we suggest you read if you are interested in the subject. This type of work is fundamental: a better assessment of a tool’s quality is always a relevant means of improving that tool. To put it another way, the current blindness surrounding the ability to qualify a RAG is the source of numerous problems in the implementation of these tools in companies or with the general public.
Black box optimization: Google makes its flagship tool, Google Vizier, open source
“Black box optimization? Behind this somewhat barbaric term lies a collection of fundamental tools which, while of course of interest to any practitioner of artificial intelligence, goes far beyond in terms of interest and applications. And before we dive (happily) into the technical side of things, it might be a good idea to remind ourselves of the scope of the subject.
In IT, a “black box” is an input/output system that is too complex for us to analyze its inner workings and draw effective conclusions. Optimizing such a “black box” means looking for the best way to exploit it, despite the intrinsic blindness of its operation. This type of approach is very generic, and concerns a large number of applications. In Deep Learningto use this type of tool to optimize hyper-parameters that strongly define the convergence of a neural network, but beyond that, they can be used to study the impact of a public policy or advertising campaign, or to optimize a simulation (like a digital twin) to solve a specific problem. The same applies to searching for a better solution, for example in resource allocation, even if these cases are usually better handled by a good old constraint-based optimizer ( hello Timefold, our long-time friend).
Obviously, such an optimization tool represents a challenge technical scope. Having so many different applications makes it impossible to specialize the search for a solution. But a number of tools have appeared in recent years, and if you’ve been in front of one of our trainers, you’ll probably have heard of the good old Optuna
Today, we welcome a new candidate, and clearly not the least important, as a new string to our bow. Google Vizier is a tool that has been used internally at Google to successfully solve extremely different problems. One version open source was recently released, and the publication The Vizier Gaussian Process Bandit Algorithm by Song et al is an opportunity to explore the approaches and results of this optimization tool. It is estimated that tens of millions of problems are managed in-house at Google by Vizierand if the initial version was implemented in C++ (a great technology if you’ve already lost your youth, but quite complex and requiring skills and neuroses rarer on the job market), a new version has arrived in Python based on TF-probabilitywhich takes advantage of GPUs to speed up the search for a solution. And we’re about to see that the results are quite impressive.
*** Warning, beginning of technical immersion, skip the next few paragraphs if you want to stay at a high level.. ***
The overall approach is based on Bayesian optimization of Gaussian processes, a classic in this field. This approach is presented below:
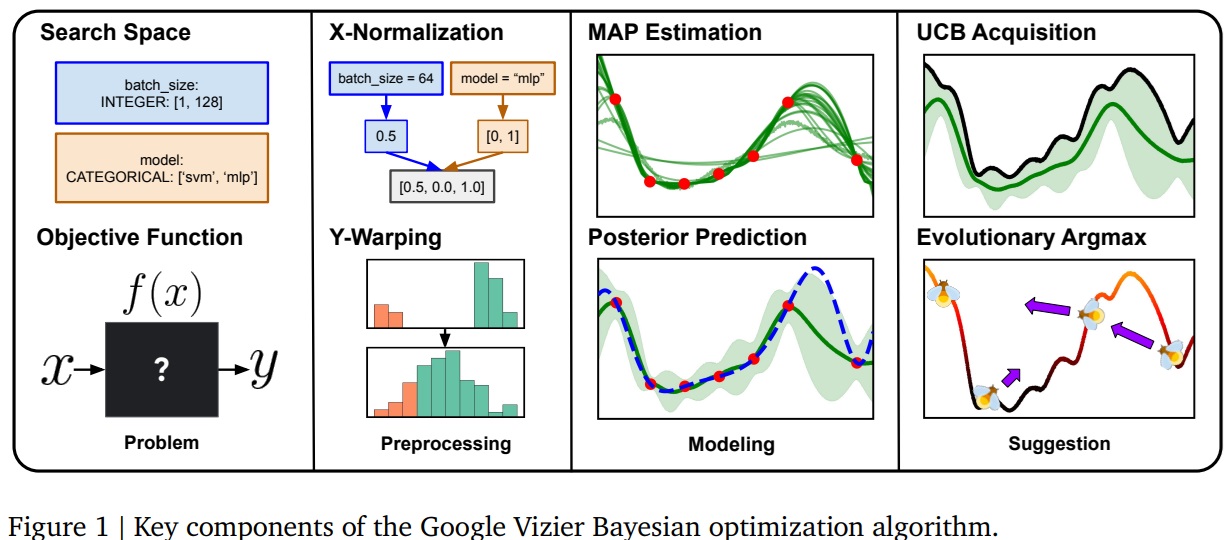
From left to right:
- Search space We’re talking here about the various parameters that modify the behavior of the black box we want to use. These parameters can take very different forms: continuous variables, discrete variables, or even enumerated values.
- Objective function We want to optimize a result, i.e., obtain the best possible score from this function by playing with the parameters of the search space.
- X-normalization & Y-warping : We’ll talk about it later 😊
- MAP estimation & Posterior prediction application of a UCB Classic Bayesian. Each attempt (choice of parameters to observe the resulting objective value) enables us to refine an estimate of the objective function we want to optimize. This estimate will provide us with new values to test next time.
- UCB Acquisition & Evolutionary argmax Classic bandit technique (si si), followed by an interesting optimization-based solution search, which we describe in more detail below.
We propose to highlight just two technical points relevant to this approach. The first concerns the Y warping which is the focus here. Remember that we’re dealing with a generic tool, supposedly capable of tackling many different problems. The values returned by the objective function therefore have no chance of having any “appreciable” behavior enabling a search for solutions. The approach here is therefore sequential, as shown in the diagram below:

The Half-rank wrapping will allow you to act on disappointing results (in this case, values below 10) by normalizing the distribution of values. These disappointing results will be moved to occupy the lower average of the target values. Visit Log warpingimproves the distribution of values for interesting results. Finally, the Infeasible Warper will identify useless targets and move them to a separate region, so that the algorithm doesn’t continue to explore this space in its search for solutions.
The second technical point of interest here is the algorithm used to update the set of detected values. The Firefly Algorithm (Firefly Algorithm) is a massive optimization algorithm proposed in 2009, inspired by the behavior of fireflies. Each “firefly” represents an experiment with its solution. The “light emitted” by the “firefly” is the quality of the solution found. In a updateThe most luminous fireflies will attract the less luminous ones, and an average motion vector will update these solutions to search for better candidates. This is a “swarm optimization where the number of elements is multiplied to obtain, overall, a relevant iteration on the solutions, in a manner quite similar to evolutionary algorithms.
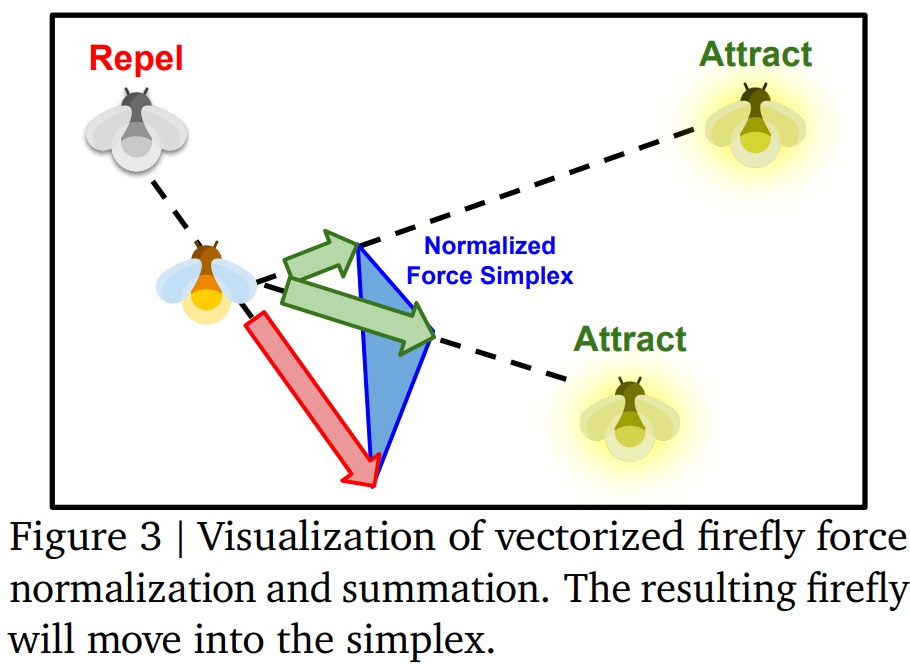
*** Attention, end of technical immersion, welcome to those who have left us. ***
Let’s move on to the results. Google Vizier as powerful as it promises to be? The results are indeed quite relevant. It’s worth pointing out that in the results given, the authors start from default methods without any specific research into the problem or the algorithm. The challenge is to put ourselves in the situation of an actor who wants to optimize his problem with as few specialized adaptations as possible. This is an interesting approach for us, but it may not work well for certain competing algorithms. These competitors are Ray Tune (a 2018 ancestor still going strong), Ax (tool for MetaAI high performance), HEBO (a highly effective Bayesian optimization project dating from 2020), HyperOpt, Optuna and Sci-kit Optimize (I don’t know about you, but I’m getting tired of the brackets). Several experiments are proposed.
The first comparison is made on a strictly continuous problem (variables can take any value in a given segment, for example, the position of an element or the force applied to a mechanical element). The authors display the efficiency (which takes into account not only the quality of the results, but also the computing power required to obtain them). We note that Vizier is not necessarily the best:
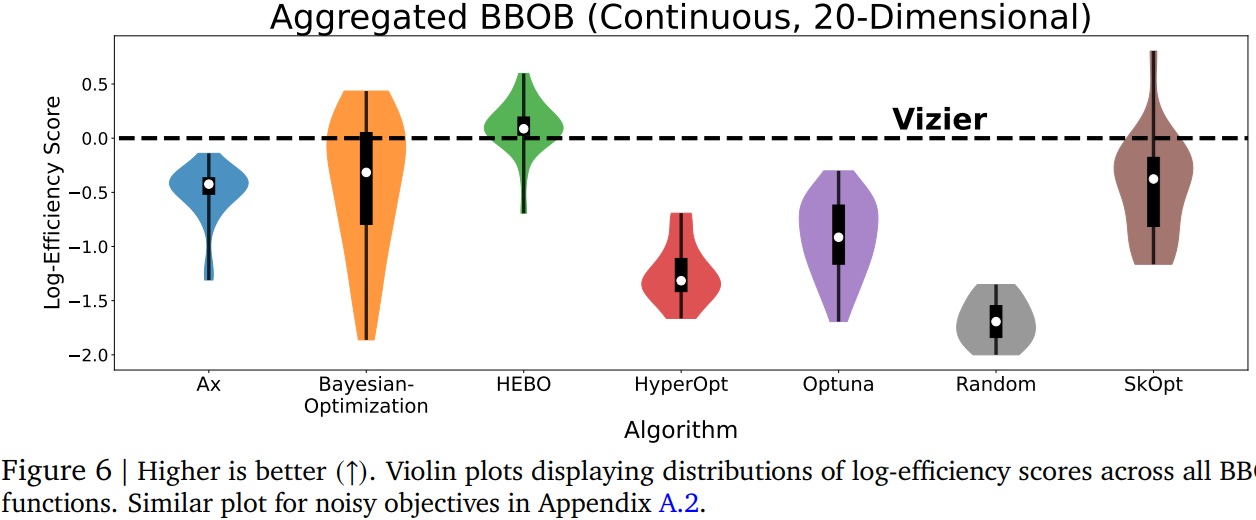
Indeed, HEBO and SkOpt can give quite superior results. But we’re dealing here with a 20-dimensional problem (20 different values to model a solution), and everything is possible. data-scientist knows that this number can easily increase. Vizier then takes his advantage:
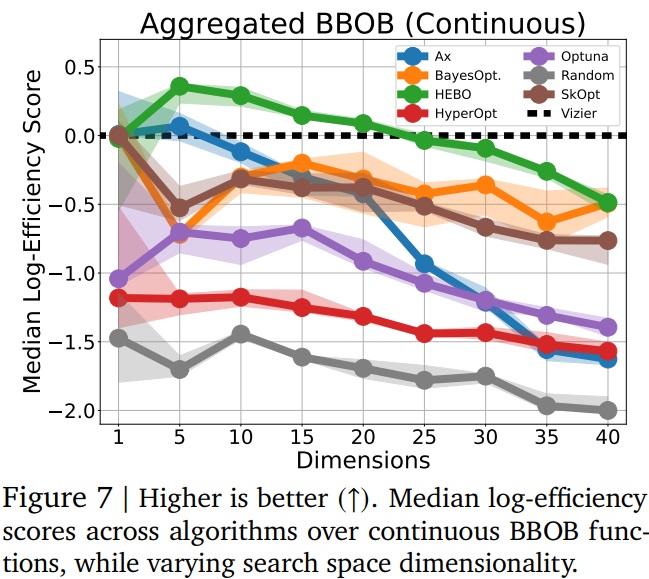
Note also that as soon as we move into problems where the parameters are not continuous, Google Vizier has a clear advantage. However, the majority of problems are not continuous in their modelling:
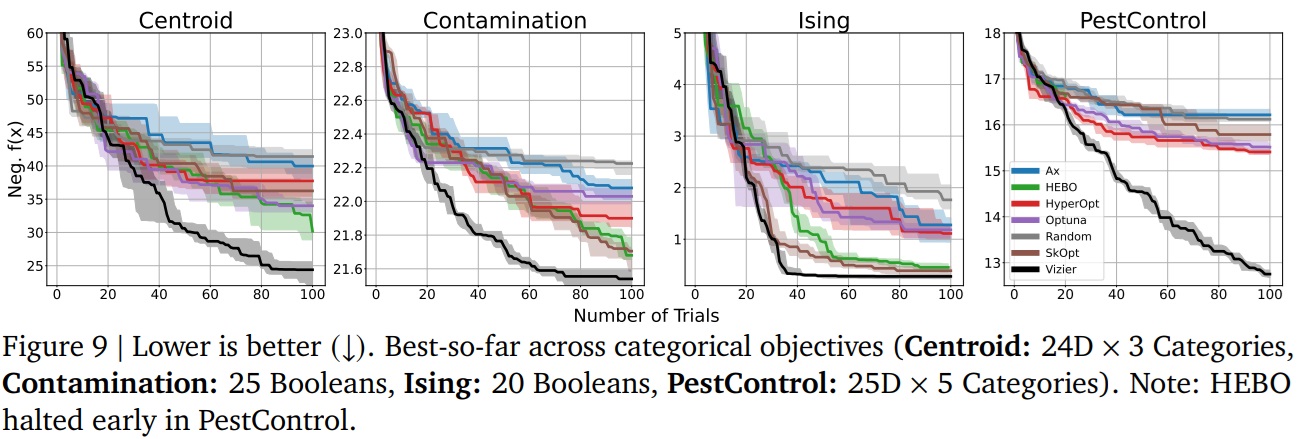
Last but not least Vizier is particularly useful when the search is parallelized (Batched cases) and where the objective is multidimensional (several values to model a solution).
Google Vizier is therefore an essential tool in the toolbox of any data scientist. Highly effective and particularly generic when faced with different problems, it can produce relevant solutions at an acceptable cost (depending on the complexity of the process to be optimized, of course).
GAvatar: the future of 3D AI modeling gains strength
And no surprises, NVIDIA has a front-row seat. But a little background before presenting this work will not be superfluous.
This will be the topic of our October webinar, 3-D modeling revolutionized by Deep learning. We also published a research journal at the end of 2023 specializing in this subject. Originally, a 3-D shape was modeled either by a cloud of points floating in space, or by very simple shapes ( meshes) joined together. These models worked very well, but suffered from a severe limit of complexity, particularly when it came to generating new 3-D shapes. However, the NeRFwhich appeared in 2020, radically changed the game, by proposing to model a shape in 3 dimensions using a specific neural network. The application was as follows: a user takes a series of photographs of a scene or object, retaining the camera’s positional information. Visit NeRF was then trained to learn how to model the scene, and could then be used to successfully generate new views (from new angles/positions) of the scene.
As usual in artificial intelligence, this approach had as many qualities as flaws. Indeed, while the generation application and the quality of the results are staggering, the modeling generation was very cumbersome and very slow (initially taking up to an hour). Beyond that, making proper use of these new modeling tools for practical applications was a totally untested subject. Then came two works:
- The InstantNGP from NVIDIA which allowed you to control the level of precision of the modeled 3D scene, and already optimized the handling of the 3D result.
- Above all, the Gaussian Splatting fromINRIA (cock-a-doodle-doo) which, in 2022, greatly optimized modeling and democratized these approaches. Following on from this work, 3D visualization tools based on this technique have appeared, encapsulated in a web browser.
From then on, it was simply a matter of time before more applied work appeared. The video game industry has been at the forefront of the adoption and use of these technologies. The release of GAvatar from Yuan et al (NVIDIA) is an event not to be missed.
Here, the approach is aimed directly at generating and animating 3-dimensional avatars. The authors explain that their approach can animate a model at up to 100 frames per second ( Warning: the authors here are rascals who don’t give the GPU used to obtain this number, forcing us to exercise a minimum of caution.).

The method used here is worth analyzing:
*** Caution: readers who have suffered from geometry problems are asked to skip this section until the results are presented ***.
We start with the diagram below and then isolate certain points to be noted:
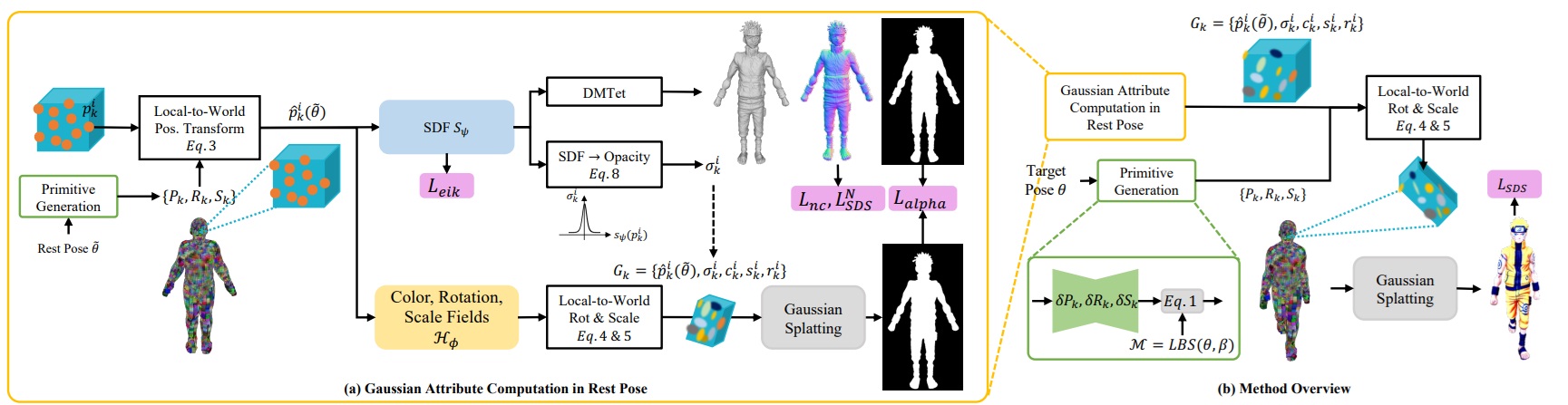
- Avatar modeling Here, the human body is represented by a collection of primitive shapes (cubes) whose position and deformation will evolve during model optimization. Each primitive “contains” a set of 3D Gaussian shapes similar to the Gaussian Splatting original. This approach will not only animate the avatar, but also group the geometrically generated Gaussians in an efficient way and avoid some of the pitfalls of the Gaussian Splatting
- Gaussian parameterization The yellow rectangle at bottom left shows the characterization of each Gaussian. We’re talking here about Neural Implicit Fields. A single neural network will therefore be trained to make these appearance and deformation predictions. This approach stabilizes the training compared with the initial version, where the authors optimized these values as direct attributes of the Gaussians.
- SDF (Signed Distance Field): the blue rectangle on the left (SDF) plays a dual role: it evaluates the opacity of the Gaussian, but also models the result as a Signed Distance Field. This modelling is important because it makes it much easier to generate a mesh that the NERFs s, which are of little use in a graphics chain.
The part on the right models use. With a target pose (avatar position), the primitives will be deformed, taking with them the linked Gaussians. We then use the splatting (projection onto a two-dimensional surface for display) to display the result.
*** Please note: at the end of your dive in a technical environment, please leave the Gaussians as you found them on your arrival.
The results are (would be?) very efficient (100 fps), but also visually well above the competition:

Why is this work so important? Because we are finally beginning to see concrete applications of the work in progress. NeRF. These applications confirm that what was a theoretical and aesthetic technical revolution will tomorrow become a central model. And there’s no shortage of applications: SLAM (ability of a robotic agent to walk through a space, model that space in 3D and locate itself), scene segmentation/analysis, robotics (interaction modeling)… Here, avatar generation may seem a little disappointing as an application, but it’s an important step towards democratizing and industrializing these approaches. NVIDIA makes it easy to generate new avatars, export results in meshes The result is an image that can not only be exploited with traditional tools, but also animated in real time. However, there are still some limitations: colors are often over-saturated, and animation remains approximate compared to what can be observed with conventional techniques. On this last point, the authors imagine that the use of physical rules or video broadcast models could improve things. To be continued.