
Research Echoes #12
Imitation Learning: AI in Robotics Becomes Credible and Accessible
Download the magazine version by clicking here
TL;DR ?
Cinq mots-clésy
#Robotics, #DeepReinforcementLearning, #ImitationLearning, #ALOHA, #DiffusionPolicies
Why reading this publication can be useful to you concretely?
If you work in robotic control, you cannot afford to ignore the ongoing revolution in imitation. And beyond robotic control, any optimization problem modeling an agent making decisions can draw inspiration from these approaches.
What you can tell a colleague or your boss about it?
Datalchemy, in partnership with Kickmaker, explores the latest imitation learning training strategies, and even though it still seems a bit magical, it works with unexpected robustness, and most importantly, finally makes these trainings affordable and almost straightforward to implement.
Which business processes are likely to be modified based on this research?
It's almost the entire chain that is impacted by this paradigm shift. But more specifically, the simulation part to recreate training conditions could be greatly reduced, since we now simply rely on recording the actions of the human operator which will serve as the training dataset.
What sentence to put in an email to send this research echo to a friend and make them want to read it?
That's crazy! Datalchemy and Kickmaker rely on the results from MIT and Toyota to demonstrate that in a very short time and with a meager budget, we can implement imitation learning to train a robot.
The use cases we have developed for clients that relate to the topic of this research echo?
Training a robotic arm to grasp a piece and place it on a target, regardless of its position in a given space.
If you only have a minute to spare for reading now, here's the essential content in 6 points or 6 sentences.
-
- Very recent emergence of new robotic training methods (diffusion policies).
-
- Miraculously enough, we transition from deep reinforcement learning (extremely lengthy and costly, with sometimes unpredictable results) to diffusion policies and ALOHA (much simpler and more affordable, yielding very robust results).
-
- Miraculously because, up until now, the theoretical foundation of this small revolution still needs to be supported.
-
- These two approaches enable training the robot to perform potentially complex tasks (complex in the sense that recreating a complete simulation of these tasks is nearly impossible) with a ridiculously small dataset (a few hundred examples of tasks correctly executed by a human operator).
-
- The diffusion policies (whose architecture partially relies on the same diffusion as generative AI) demonstrate remarkable robustness to variations during training (a hand passing in front of the video sensor, the object to be manipulated mischievously moved, etc.).
-
- A very recent evolution of ALOHA makes the entire process portable, envisioning training a robot at home to assist the elderly or people with disabilities in everyday tasks.
AI & Robotics
A bit of change! Datalchemy has had the honor of accompanying the company Kickmaker for almost two years on topics of artificial intelligence, notably applied to robotics. So, we have been in the front row seats to observe the impressive evolution of this field. While AI applications in robotics have existed since the works of Mnih et al and the advent of Deep Reinforcement Learning, it must be acknowledged that these works have long remained inaccessible, for two main reasons :
-
- Training in DRL (Deep Reinforcement Learning) naturally requires much more GPU power than traditional Deep Learning training. Projects that caught our attention in 2018 (such as training a robotic hand by OpenAI, see diagram below) required a minimum of 8 high-performance GPUs to hope to obtain an agent. Many of our clients would have loved to try this approach, but were not willing to break the bank to form an opinion.
-
- This domain, DRL, while extremely enjoyable in its formulation (we train a software agent to maximize an arbitrary reward), was very cautious about real-world applications. As much as a model could learn to juggle in an expert manner quite easily in a typical simulator, transferring to reality was doomed to failure, as reality tended to create conditions too disconnected from the simulation. As for learning directly in reality, considering the cost of a robot, it was impossible.
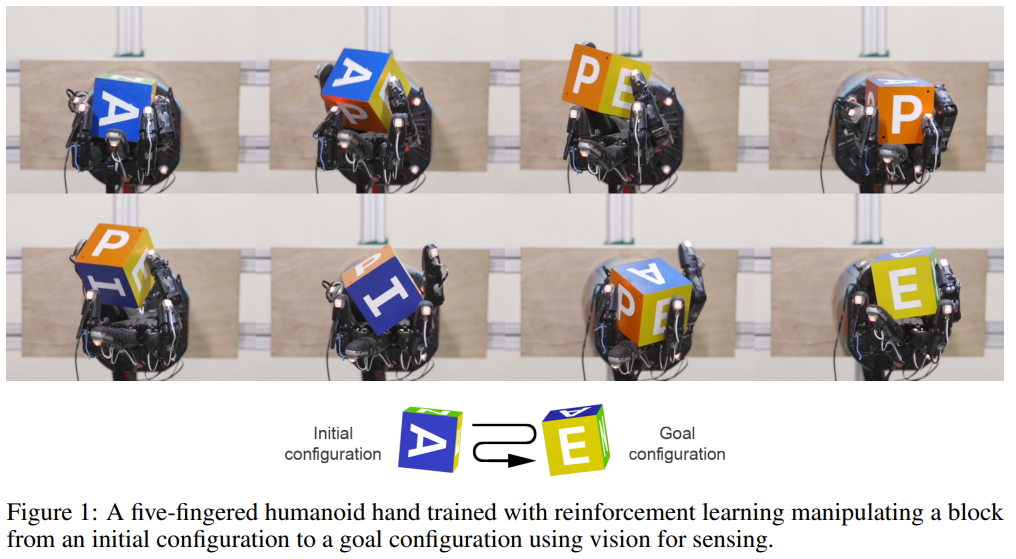
Figure from Learning Dexterous In-Hand Manipulation, Andrychowicz et al
So the field remained the prerogative of "big" players in Deep Learning, such as OpenAI or Google. Google and RT-1, and RT-2models. Indeed, Google presented the world with a robust robotic system that leverages the latest advancements in Large Language Models (again...) and cross cross embeddings (allowing images and texts to be worked on in a common mathematical space) to control a robotic arm for a wide range of tasks. While this training must have been particularly heavy, the promise is enticing. Controlling a robotic arm requires extremely precise control of each position in space, and to grasp an object, for example, it is necessary to precisely locate that object. Once this (non-trivial) localization is achieved, the robotic movement must also be calculated exactly while respecting its mechanical constraints... Here, the idea of having just a text description to execute an action seems to be a very strong disruption in this field, with impressive variance, as the text can serve to describe both the gesture and the target object (below, among other examples: pick up the bag about to fall off »)

So, Google revolutionized the field of robotics? Have industry players seized upon these works to apply them to their own scenarios and revolutionize the industrial branch? Unfortunately, no. Indeed, (and Google had accustomed us to better), while the publication is freely available, the code required to train or use these models is, as of now, unavailable. And considering that these trainings require both training the Large Language Model (LLM) and the actor, their cumulative costs prevent any replication work.
However, let's note another potentially complex point with this approach: the RT2 model is an end-to-end model: we input text, and observe actions controlling the robot as output. However, anyone who has worked a little with Large Language Models knows that controlling a model with a prompt is a dark, illogical, and anxiety-inducing art, in which errors can easily appear unexpectedly. It's not impossible that RT2 suffers from the same issue...
At this stage, we could sadly conclude that cutting-edge AI is reserved for very large players who, sooner or later, will commercialize their work. But in the last six months, the scientific landscape has radically changed and suddenly become much more accessible...
Learning by imitation
The surprise came from another research stream of DRL, which until now had remained more of a scientific curiosity than a real solution: Imitation Learning.
In a "classic" approach, we will train an AI model to find the right actions to take in order to obtain the greatest possible reward. The model will be faced with a simulator reproducing (more or less well) the target reality, will make an astronomical amount of mistakes, and finally (with a bit of luck, let's be honest) become "good" enough to succeed in its task.
In "Imitation Learning" approaches, we do not directly use a simulator. Instead, a human expert generates a certain number of demonstrations, each corresponding to a sequence of successful actions. Once these demonstrations are accumulated, a model is trained to generalize from them, in order to handle the largest possible number of scenarios. Considering that we typically have only a few hundred demonstrations, the challenge of generalization here is particularly daunting, as the model must learn to handle cases it has never seen in the demonstrations, without access to the physical constraints of the world it operates in. For this reason mainly, Imitation Learning has remained a rather sidelined topic. Yet, it holds a very interesting promise: training a model on a task agnostic to examples that can fully correspond to reality, without the need for an elaborate simulator. Several recent works have revolutionized this field, works that are now applicable to industry and require a moderate economic investment. It's time to present these little revolutions 😊
ALOHA : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware, Zhao et al
The collaborative effort of Meta, Stanford, and Berkeley, ALOHA is a breath of practicality and efficiency that has truly disrupted the field to our utmost delight. Fundamentally, the strength of this approach lies in the fact that researchers did not settle for running a more or less exotic algorithm on a GPU cluster to extract pretty videos. On the contrary, the authors propose here a comprehensive approach allowing to recreate the recording configuration of demonstrations in addition to the training and inference code. And this robotic manipulation setup is "low cost", with a reproduction cost estimated at less than $6000 (provided one has access to a decent 3D printer). ALOHA indeed proposes to create interfaces allowing direct control of the two robot arms by a human operator. Through this approach, an expert can record a number of demonstrations on specific tasks:

This "low-cost" approach is already a small revolution in a world where even the slightest hardware costs a small fortune. Here, the entire system costs the equivalent of an entry-level robotic arm. More generally, the advantages are quite numerous: versatility with a wide range of possible applications, easy to use, easy to repair as well as to build (at least relative to the world of robotics). It is already quite rare for researchers to address the question of performance and reproducibility of their work to this extent; here, everything is available to reproduce this system quite easily. As soon as we manage to perform a task via the control interface, we can hope to train a model that generalizes this task in a satisfactory manner. The tasks accomplished, precisely, have the particularity of going far beyond commonly accepted reinforcement applications. We are talking about extremely precise actions, such as opening or closing a ziplockbag, grabbing a credit card from a wallet (skynet will need pocket money, don't argue), inserting an electronic component, turning the pages of a book, up to bouncing a ping pong ball on a racket!

These tasks are interesting because they would typically be very challenging (if not impossible) to learn in a classical approach, simply because they are very complex to replicate in simulation (imagine a simulator reproducing the physical deformation of plastic). They are also tasks requiring high precision. They are possible here precisely because we rely on demonstrations performed by human operators who, themselves, can react to the evolution of the problem to find the right action policy. One could postulate (in an ambitious manner) that if a task can be performed in demonstration, it can be subjected to learning...
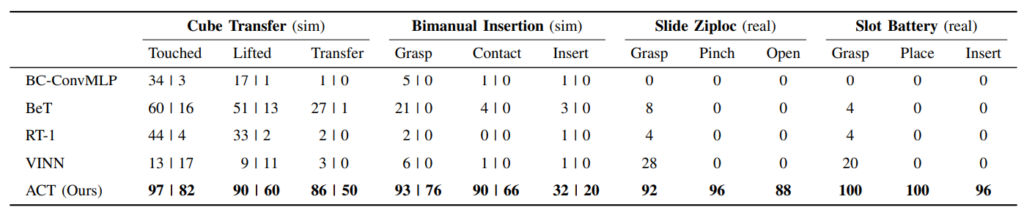
Regarding the internal architecture of the model, we'll leave aside some technical peculiarities here to note that we find the eternal Transformer (note: eternity began in 2017 for researchers in Deep Learning). A CNN-type encoder will generate high-level representations of images from each camera (here, four cameras), to then feed into a Transformer encoder that also takes the robot's command history as input. At the output, the decoder will be called to generate the next action sequence. Of interest, a conditional VAE is used here to train another Transformer encoder and allow it to learn a relevant compression of the input information. ALOHA was the first cannon shot with results significantly superior to what could be observed before. Below, the ACT of ALOHA is compared to previous approaches on two synthetic tasks and two real tasks. The observed results are significantly more convincing.
Diffusion Policies : Visuomotor Policy Learning via Action Diffusion, Chi et al
Another piece of work emerged in June 2023, establishing itself as a new reference in the field of Imitation Learning. Led by MIT, Toyota, and Columbia University, Diffusion Policies have emerged as a highly effective and versatile approach, now becoming for us a quasi-baseline to test against a new problem.
We remain within the same paradigm as before, namely, training a model to solve a problem using a finite number of demonstrations. This approach has notably distinguished itself by its architectural approach which makes it extremely efficient. Particularly:
-
- A modeling allowing closed-loop operation, continuously taking into account the history of the robot's recent actions to adjust the future movements generated by the model. The idea is that the model will be able to continuously adapt its actions, especially in the event of sudden occurrences: camera occlusion, movement of an object by a third party, etc. This robustness, which we have observed in our tests, is a very strong advantage of Diffusion Policies.
-
- Effective visual conditioning. A sub-model is specialized in extracting from a sequence of images (the history of the robot's actions seen by a camera) representations which, then, will feed the diffusion process that generates the robot's actions (we will come back to this very soon). This extraction is done only once per image, independently of the diffusion, allowing the resulting model to run in real-time.
-
- A new optimal ad-hoc architecture for performing broadcasting (I promised we would come back to it, and that promise will be kept!) with a Transformer.
And promise made, promise kept, let's take this opportunity to talk about broadcasting 😊
If you follow Deep Learning even a little, you haven't missed this new approach that has emerged over the past two years, especially in the case of generative AIs like Stable Diffusion. The idea of diffusion is that we train a model to produce the information we are interested in, but with an additional constraint on this generation: starting from completely noisy information and, gradually, through denoising, obtaining the desired result. We have already discussed these new approaches in our research review, especially because while they yield impressive results, they are too recent for us to understand why they work so well.
As usual in Deep Learning, an approach that works very well in one domain will be tested in all other domains. It's not always a very good idea (how many architectures aiming to "optimize" the attention of the Transformer have ended up in limbo?), but for diffusion, it must be recognized that this comprehensive approach seems to apply to other subjects than just effortless image generation.
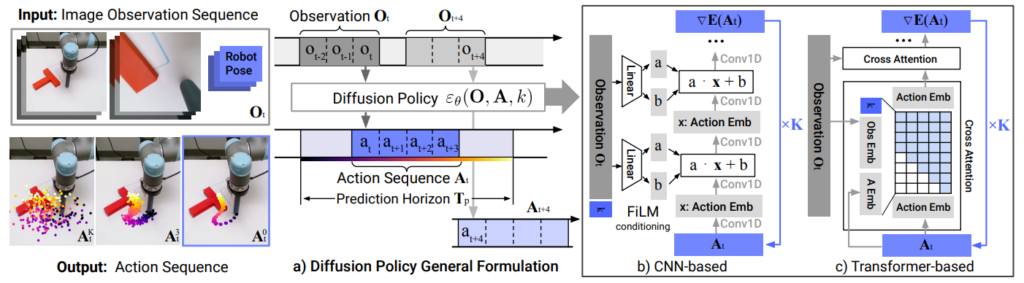
Here, we discover that these diffusion models are an excellent tool for learning to generate control information for a robot arm, conditioned on a history of actions and images. We won't even try to attempt a justification of this success. But it seems that this approach succeeds in truly generalizing new actions from demonstrations, and does so very effectively. The diagram below represents the overall architecture. We have (top left) a history of actions and images. These observations will be exploited to generate, through diffusion, the sequence of actions (diagram a) Diffusion Policy General Formulation). This sequence is generated by modeling the images either by a good old CNN (diagram b)), or a Transformer (diagram c)). At the bottom left, we see a modeling of diffusion with, all the way to the left, a series of completely noisy positions, which through diffusion will eventually (third image) be refined into a series of valid positions to push the 'T' to the right place.
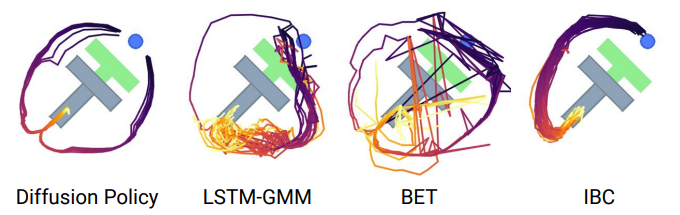
Several points of interest are to be noted here: Diffusion models are multimodal. They learn true variance in action strategies and remain very stable unlike previous approaches, as shown in the diagram below, where the IBC learns only one direction (similar to almost the LSTM-GMM), and where BET/LSTM-GMM are very, if not too noisy :
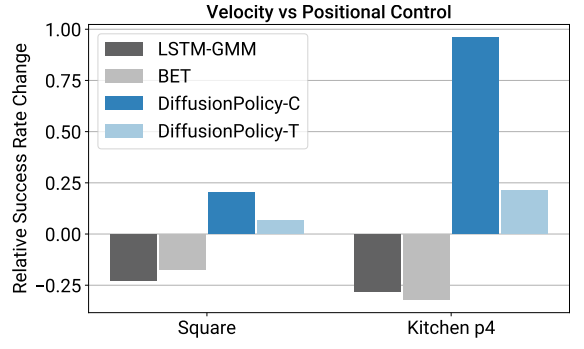
Diffusion Policy works in positions. The majority of imitation-based robotic control approaches model the movement of the robot arm as speed control, rather than position control. Surprisingly, position control works much better here.
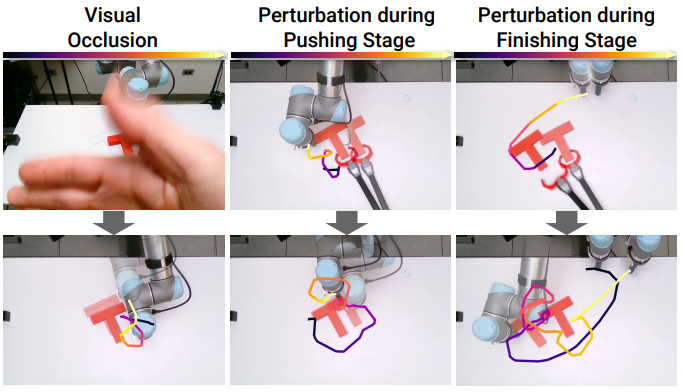
The Diffusion Policy is robust against reception latency.One strength of this approach is to offer an efficient method, and thus robust to certain disruptions. The authors have introduced a latency of up to 10 timesteps with negligible loss of results. Here, we observe an appreciable form of generalization that allows us to project ourselves correctly towards a practical use of this tool.
Diffusion Policy is stable during training. We observed this personally during our tests, where the choice of hyperparameters often involves desperate attempts that can completely invalidate training. Diffusion Policy is extremely stable. And this is excellent news because usually, it is necessary to iterate on these hyperparameters to hope to find the right combination, which is both time-consuming and costly.
Diffusion Policy is stable in the face of disturbances. This point is impressive. During the training of a robot in a real environment, the authors regularly obscure the camera or move an element that the robot must manipulate. The model adjusts its strategy in real time without making mistakes. Once again, we have a strong argument if we are interested in concrete and effective approaches.
MobileALHOA : Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation, Fu et al
This latest work is much more recent but deserves attention. Here, there isn't really any mathematical innovation in Deep Learning, but rather a window opened to the future of robotics from these approaches. The authors took the ALOHA approach and evolved it to create a demonstration environment that is portable and can be applied anywhere, especially in someone's home. This allows for gathering demonstrations in an open setting, and then training a model to interact with common objects via a complete robot :

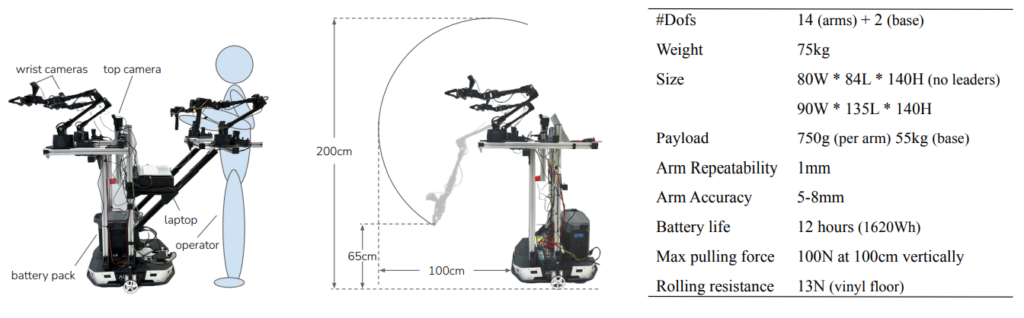
The most impressive aspect of this affair isn't just the versatility of the actions performed, but the fact that the system remains financially accessible (around $30K) and opens the door to numerous interesting applications. Here, we have a system that is fast in execution (comparable to a human in normal movement), stable even for handling heavy objects, and self-sufficient in terms of power supply (integrated battery).
Another point of interest is that the authors reused the old demonstrations from ALOHA to train the model together with these new applications, and observed a real improvement in results. This implies that each problem is not completely isolated, and a model can learn to transfer from one situation to another. It becomes conceivable to have a global dataset acting as a foundation, allowing for very effective learning of new tasks. It is also worth noting that MobileALOHA here only requires about fifty demonstrations to learn a task, slightly less than the diffusion policies which require several hundred. Below are some examples of tasks learned and reproduced by the model :

Conclusions ?
If we are to conclude, we can already observe that we are at a key moment in the field of robotics augmented by artificial intelligence. A domain that was extremely costly to access suddenly becomes much more accessible (training diffusion policies, for example, takes two to three days on a standard GPU). The areas of application are also exploding, solving tons of problems we had, summarized somewhat caricaturally as "if we can control the robot and collect demonstrations, we can hope to train an agent".
Furthermore, caution is advised! These works are still very recent, and as usual in Deep Learning, training a model is one thing, but framing and controlling it to avoid bad scenarios is a separate task not to be underestimated, sometimes more complex than the training itself. It is therefore necessary to control the actions sent in real time to avoid collisions (when possible!), or at least to prevent undesired modes of operation. Testing such a system is also a challenge, especially if we have trained a real robot directly... Nevertheless, robotics seems ready to enter a new golden age. Where programming such a system was incredibly cumbersome, accumulating demonstrations is much faster and directly addresses the specifics of the targeted problem through the operator. A matter to follow, as usual 😊