
Research Echoes #4
Does passing an exam make you intelligent?
Things are moving very fast at the moment in the field of artificial intelligence. Things are moving very fast, perhaps even too fast, and today we'd like to take a look at a recent publication from Microsoft, which talks about ‘sparks of intelligence’ within GPT4, the famous OpenAI language model. Readers of this blog will already have been redirected to a more sober and less sensationalist analysis of these models [STOCHASTIC PERROTS], but in a context where more and more major groups are talking about laying off staff in order to, let's open the essential inverted commas, 'replace them with artificial intelligence', we owe it to ourselves to analyse this work and its promises. We will continue with work from the Meta AII laboratories on learning multi-modal representations. Can we use a model to learn a space on which the same concept, in the form of an image, text or sound, will be projected in the same place? It was this approach that led to the first DALL-E, and this type of work is still very interesting for us to follow.
Everything is moving very fast right now in the field of artificial intelligence. Everything is moving very fast, perhaps even too fast, and today we already propose to pause and take a look at a recent publication from Microsoft, discussing "sparks of intelligence" within GPT-4, the famous language model fromOpenAI. Readers of this blog may have already been directed to a more thoughtful and less sensationalist analysis of these models [STOCHASTIC PERROTS], but in a context where more and more large companies talk about layoffs to, to use necessary quotes, "replace them with artificial intelligence," we must analyze this work and its promises. We will then continue with a piece of work from Meta AI labs on multi-modal representation learning. Can we, through a model, learn a space where the same concept, in the form of image, text, or sound, will be projected to the same location? This approach, which enabled the first DALL-Eat the time, is still very interesting for us to follow.
Sparks of intelligence or marketing ?
Sparks of Artificial General Intelligence: Early experiments with GPT-4, by Bubeck et al [https://www.microsoft.com/en-us/research/publication/sparks-of-artificial-general-intelligence-early-experiments-with-gpt-4/] is a very recent work which, unsurprisingly, has caused a huge stir. To say that this subject is currently very sensitive is a fine understatement. Since ChatGPT was made available, language models have received a huge amount of attention, and the debate has been launched as to the real value of these new tools...
- On the one hand (and we'll come back to this shortly), OpenAI and Microsoft have no hesitation in presenting this model as a real step forward towards 'true' artificial intelligence, capable of replacing an individual in intellectually complex tasks.
- On the other hand, there are many voices criticising the methodology and the claims that go with it (see On the Dangers of Stochastic Parrots..., [https://dl.acm.org/doi/10.1145/3442188.3445922]
This new publication comes in the midst of this tense atmosphere, and it doesn't pull any punches...
What are we talking about ?
In this new work, the authors go very far in asserting that GPT4 does indeed represent a new form of intelligence. The authors approach many different tasks for which they propose an interesting analysis methodology to push the model to its limits. The application tests are numerous: image generation beyond simple memorisation, writing computer source code, mathematics, interactions with the world or with an individual, etc. On first reading, the results are indeed impressive. Below, the writing of a mathematical demonstration fundamental to poetry, or the generation of vector code to draw an element :

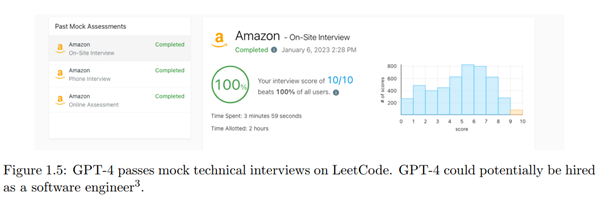
To revisit a "evergreen" topic of language models, GPT4 could be a software developer in the future :
The model is also said to be capable of generating ‘original’ music (those inverted commas are there for a reason, and we'll be talking about that shortly) :

Without delving too deeply into an exhaustive list (feel free to read the publication), GPT4 would also exhibit remarkable proficiency in mathematics :

The methodology proposed by the authors is particularly interesting, as it navigates around the fundamental problem to which we will return later. The authors seek to observe whether the model is capable of adapting its responses to new instructions and whether it can adapt to new domains. More specifically, the authors are seeking to observe a form of generalisation of the model, in an attempt to escape from a form of results derived from memorising the model. One form of generalisation they are looking for concerns multi-modularity: this model has only been trained on text, so if it is capable of reacting to notions in images without ever having observed any, we would be looking at a real and impressive generalisation.
It should be noted that while the authors consider GPT-4 to be a step forward, they do not consider it to be an AGI (generic AI, 'true AI'), which still has many limitations. These limitations appear very quickly in problems linked to organisation, and are the subject of a dedicated chapter.
Why it's interesting
We are seeing more and more companies thinking about ‘replacing humans with AI’. Beyond the hype, we need to question the real effectiveness that a neural network can have on real problems. In this respect, claiming that these models could be ‘lawyers’ or ‘computer developers’ on the basis of scores obtained in tests raises huge questions.
The heart of the problem is also raised by the authors :


Indeed, to assess any Deep Learning model since 2012, it's essential to observe how well the model has memorized information in its training set and how capable it is of generating new, original responses to a novel problem. In the case of coding tests, mathematical problems, or lawyer exams, if the model has encountered these scenarios frequently during training, its "success" will be heavily qualified, and it will likely fail when faced with a genuinely new problem.
However, and this is the huge problem raised by the publication on Stochastic Parrots, we do not know the dataset used by OpenAI for its training. OpenAI refuses to provide this information without which we cannot judge the quality of the model.
This lack of information is a huge detriment in the world of research, where a researcher's work is only of value if it has been criticised and reproduced by other researchers. This opacity is a policy adopted byOpenAI that raises questions. We do not know to what extent GPT4 has what is known as a "'poisoned dataset'".
Please note: this observation does not totally undermine the value of GPT4. Simply learning to summarise a huge amount of information for re-use is a remarkable feat, and language models clearly learn high-level modelling of information that allows them to transfer/adapt tasks easily. And even if the hypothesis of the “poisoned dataset” hypothesis is valid, this model remains a fascinating tool that condenses an incredible amount of knowledge in a misunderstood way. We do not understand today what a language model fundamentally is. It is regrettable that there is so much marketing noise today that we cannot stand back and judge the quality of these tools. Remember that the authors all come from Microsoft, which is paying dearly for its collaboration with OpenAI to take a leadership role in artificial intelligence...
From all angles: an embedding space for all modalities
Data can take many forms: image, video, sound, text, etc. An embedding space is a tool that can be used to simplify data and replace it with a much simpler vector. All Deep Learning work implicitly aims to learn such a space: an image classifier will learn to summarise an image into a simpler vector, just as ChatGPT will learn to transform each element of a sentence into such a vector.
In a recent work, IMAGEBIND: One Embedding Space To Bind Them All, Girdhar et al, [https://arxiv.org/abs/2305.05665], the MetaAI teams have struck a blow that cannot fail to interest us.
What's happening?
Here, the authors are training a model that aims to bring together several modalities in the same space: images, video, audio, text, sound, depth maps, IMUs, thermal images, etc. The challenge is to be able to bring together several modalities in the same space. The challenge is to be able to bring together two modalities targeting the same context: the sound of a fire, an image of a fire, a text describing a fire, and so on. The model therefore learns how to project each piece of data into a space of 'concepts' (a term to be taken lightly here) and then work from one modality to another.

What's fascinating is that here, the authors don't necessarily have links between all the modalities, but only certain links, such as text to image, sound to video, and so on. However, the model clearly learns to work from any modality to any other modality.
Once the model had been trained, they were then able to test it on a large number of applications, as this type of approach is by nature very generic (we'll come back to this later), for example :
- Classification of sound or movement using IMU
- Content retrieval using textual description
- Generation of content controlled by other content (example below):
- Detect elements from sounds to target an element :

Why it's interesting
We've been doing Deep Learning long enough to understand that the fundamental challenge in training a model is learning a satisfactory dimensionality reduction of the data. While this learning can be done implicitly by training a model, working on specific backbones is often interesting. Furthermore, learning anembeddings space is a fundamental tool for working with new data, especially for clustering or anomaly detection approaches.
Here, we already have an approach that provides us with new tools that are easy to parameterise, although we lack the hindsight to analyse the quality of these tools compared with challengers simpler but potentially more effective A picture containing screenshot, colorfulness, artDescription automatically generatedchallengers
that are simpler but potentially more effective. Above all, we have a toolbox that allows us to work directly on many forms of data. And multi-modal learning greatly enriches the information we can extract from, say, a depth map or an audio recording. This type of approach is a minor revolution for exploratory work on data, where the ability to transfer information and reduce its complexity are the sinews of war.
Editor Eric Debeir - Technical Director of Datalchemy