
Research Echoes #7
And in 3D, can you see anything? But yes, thanks to neural networks.
Written by Eric DEBEIR - Scientific Director of Datalchemy - eric@datalchemy.net
www.datalchemy.net
NeRFs, Signed Distance Fields... Behind these barbaric terms lies a small scientific revolution born from artificial intelligence with numerous applications. Today, we offer a focus on this new field that emerged around 2021 and has recently seen impressive new results. We will start with a landmark work by NVIDIA, Instant Neural Graphic Primitives, then move on to two recent works: LeRFs and Gaussian Splatting. But before that, a more comprehensive introduction is needed.
What are we talking about?
A fundamental challenge is that of Computer Vision: leveraging visual information from sensors to model a representation of the world. These models are often in two dimensions (from a standard photograph), but transitioning to a three-dimensional representation is essential if one wants to subsequently act correctly: precise detection of an element in space, robotic manipulation, etc.
Fundamentally, there are two main approaches to representing a scene in 3D :
- A modeling by voxels, which is a three-dimensional equivalent of a pixel. Where a pixel is an atomic point in two dimensions, a voxel is an atomic building block of space representation. Voxel-based modeling is often unnecessarily heavy, as the objects we want to identify occupy a minimal part of the total space. Many works have attempted to optimize this approach, and curious readers may be interested in the Minkowski Engine.
- A modeling by simple points in three dimensions, known as "point clouds". This modeling is often the most efficient, and many Deep Learning architectures are optimized to handle this form of data. Interested readers can refer to PointNet and its numerous successors.
NeRFs (Neural Radience Fields) and SDFs (Signed Distance Fields) are two new methods for modeling a scene in three dimensions. Each has its advantages and disadvantages, and we won't go into too much technical detail in this article. The main point to remember is that these approaches aim to model a scene by training a specific neural network, which, once trained, can then be used to query the appearance of each "point" from a virtual camera.
An particular advantage of these methods is that we can generate the 3D representation from a collection of 2D photographs taken from different angles. Furthermore, NeRFs and SDFs allow for photo-realistic reconstruction of unmatched quality, surpassing anything that existed before.
Until the following work, the main issue was the extreme slowness (due to computational heaviness) in generating a new scene. But NVIDIA sparked a revolution with the first Instant NGPs...
Instant NGP – Instant Neural Graphic Primitives with a Multiresolution Hash Encoding
This work by Müller et al [1] had the effect of a thunderclap in the research world. The authors here broadly explored the idea of training a neural network to represent a scene, working on four different applications: Gigapixel image, SDF, NRC et NeRF. The main advancement here is the speed of training and generation, with an approach considered "instantaneous" (which may be slightly exaggerated). From a collection of photographs of the target scene, a neural network is trained with increasing accuracy based on the time allocated for training.

The main revolution brought by the authors concerns the method for modeling scene details based on the desired resolution level. Here, a hierarchical architecture encodes hashes to identify how we want to call the trained neural network. This method is extremely efficient and evidently volatile enough to be applied to the four target domains of the publication.
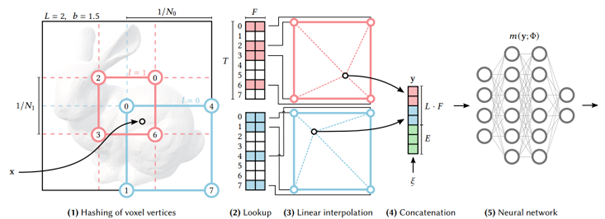
Another very strong argument of this work is the speed of model training, which was much more interesting than what existed until now, making the approach practically usable. It is worth noting that this speed is not unrelated to the authors' affiliation (NVIDIA). The multi-hash encoding algorithm was thus implemented directly in CUDA to be as efficient as possible on a GPU. This work is available on Github today, even though the source code license does not allow for commercial use...
It's worth noting that NVIDIA has notably supported a large number of artistic creations using this work, encouraging its use in various creative contexts... However, at the time, this work proved insufficient to envision a realistic and effective application in the industry. Many researchers have worked on the subject, and we'd like to present two recent and exciting works...
3D Gaussian Splatting for Real-Time Radiance Field Rendering
This work by Kerbl et al [2] from Inria (Cocorico as required) recently disrupted the field by offering much better quality results with much more usable real-time rendering. We have thus recently seen many actors jumping on this approach to create web viewers for NeRFs, or to do real-time animated mesh rendering while maintaining a quality close to photorealism. Here, the authors manage to generate new views from a scene recorded at 30 frames per second, at a resolution of 1080p. The results are impressive :

To date, this approach is the most relevant for training and using a NeRF, pending further work. It should be noted that this notion of rendering speed is fundamental for using these tools correctly, for example in animation rendering (to explore an acquired scene, or even to animate a scene). We closely follow these optimization efforts and await future developments to continue identifying the best opportunities for our clients.
LERF : Language embedded Radiance Field
The next work by Kerr et al [3] will make those who follow the field of Deep Learning smile, as after all, is there even a single domain where recent advances in language processing have not been applied?
Here, the idea is to couple the training of a NeRF with OpenAI's CLIP model. As a reminder, the latter has been trained to align, in a latent space, a textual description of an image. CLIP has already been extensively used to query the content of an image from a textual prompt. Here, the authors train the model so that it can query a NeRF from a description text. The image below should clarify the subject :

Attention : it is indeed a 3-dimensional scene that is being worked on, not just a simple image. This work allows us to highlight a current limitation of NeRFs, namely, their usability. It's one thing to model a 3D scene in a photo-realistic way; it's another to then extract information or be able to locate a part based on a semantic query. Here, the approach directly enables querying a trained model to isolate interesting content based on a precise or non-precise description: description of an object, color, concept, etc. Obviously, the alerts and limitations we have provided on language control remain valid here.
The authors also elegantly specify some of these limitations, notably the "bag of words" aspect: a textual query may not necessarily respect the logical meaning of the sentence. "« not red »" is similar to "red."
Nevertheless, this work remains an important step in academic research on the subject of NeRFs.
Should one "do NeRF" today ?
Following academic research is one thing, applying it to a concrete problem is another. Some initial applications are already practical for acquiring and rendering a 3D scene. Some actors aim to create new tools based on these techniques, for example, to showcase the three-dimensional appearance of a product on the Internet or to facilitate capture. However, these tools are still very young and suffer from real heaviness in their usage. It is also noticeable that, to date, there are still few relevant works (from an industrial/application perspective) to solve a technical problem based on NeRF/SDF. It's one thing to acquire a 3D representation of a scene; it's another to extract concrete information with real control over the tool's limitations and results.
We have the impression that we are approaching the moment when things will shift. Many technical and scientific challenges have been overcome in the past two years, and a good bet is that 2024 will be the year when processing Computer Vision of a scene through these approaches becomes second nature.
If you wish to follow these works, we can recommend the excellent site https://neuralradiancefields.io/ which follows and comments on the news of this new scientific domain.
[1] : https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
[2] : https://arxiv.org/abs/2308.04079
[3] : https://www.lerf.io/