
Research Echoes #6
A new installment of Transformers, cinema or reality ?
Link for downloading the article in PDF format
Let's not hide our excitement, as this research review will be quite distant from the clamor of language models and other GPT-like models (which were the subject of a dedicated webinar in July), to focus on three exciting and fundamental works released in the past two weeks. On the agenda: a new, simple, and devilishly effective architecture for vision, a convincing generative model for music generation, and a promising scientific work for the interpretability of Deep Learning and data representation generation. Let's dive in!
A benchmark Vision Transformer
[https://arxiv.org/abs/2306.00989]
What's happening?
Whatever one may think of Meta as a company, it's undeniable that the Meta AI lab remains one of the most interesting players in the field. One of their advantages is their quest for efficient architectures, which goes against the grain of conventional academic approaches.
Here, with Hiera, Meta AI offers us a new baseline architecture around the Vision Transformer that is simpler and more efficient. While the ViT has indeed been gradually gaining traction in the academic world over the past three years, its relative youth has led to numerous efforts to improve its performance through various more or less controlled tricks.
As the authors note, recent advancements in the ViT have indeed improved its results, but at the cost of increased complexity. However, once we step out of the academic realm and into engineering, the training speed of a model becomes a key factor in iterating more rapidly on a problem and thus having better-suited tools.
In this context, Hiera is a much simpler model where the authors have removed a number of advancements proposed in the last two or three years, in favor of a much more effective pre-training based on the Masked AutoEncoder (MAE), where the model learns to understand spatial bias in images, a bias that is not structurally present in the Transformer architecture. It's worth noting that the absence of spatial bias in the Transformer has long been a topic of discussion, with many attempts made to address it, albeit at the cost of additional complexity. The authors argue here that the MAE is a pre-training method that introduces this spatial bias, but with minimal additional training overhead.
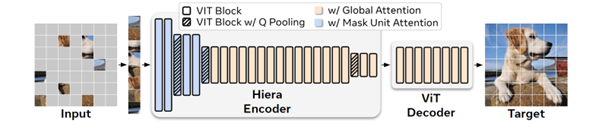
The model is furthermore a hierarchical model, processing the input image at different levels of resolution. It's worth noting that the MAE approach (masking part of the image and training the model to recover this masked part) is fundamentally ill-suited for a hierarchical model; the authors propose a specific adaptation here.
Why it's interesting
Deep Learning is a field of research, which often poses challenges in application. Many improvements are proposed, often validated according to a specific approach, but without insight into the combination and real relevance of these improvements. Moreover, these enhancements often introduce additional complexity and slowness, hindering the use of these models in direct application.
Here, a new, simpler, and more controlled architecture is excellent news for us, as it provides a more stable and faster starting point for approaching new subjects.
Furthermore, these models can serve as a backbone in more specialized models (especially in segmentation, detection, etc.). It's therefore highly likely that this model will directly influence many more specialized tools.
However, it's worth noting that a year ago, MetaAI proposed a new reference convolutional model (A Convnet for the 2020s [https://arxiv.org/abs/2201.03545]) in response to the evolution of Vision Transfomers. This new study seems to suggest that convolutional models are gradually becoming part of history 🙂
Generative AI and Music, a New Milestone
[https://arxiv.org/abs/2306.05284]
Generative AI has been a highly active field since the emergence of Stable Diffusion and Large Language Models, primarily tailored to images or text. Music, while an intriguing subject, has been somewhat frustratingly less effective compared to other domains. Several reasons contribute to this delay :
- We are much more tolerant of errors in an image than errors in sound. A few erroneous pixels may go unnoticed by our brains, while errors in the phase of a generated signal can result in an unpleasant auditory experience.
- The realization that music is a less commercially appealing domain compared to images or text applications, leading to less significant economic incentives.
- The relative scarcity of data in music compared to images, in a domain where data quantity remains a crucial factor in training neural network models.
If we set aside the very recent approaches where sound and diffusion models were mixed, which were quite disappointing, the last convincing approach was OpenAI's Jukebox in 2020 [https://openai.com/research/jukebox].
Therefore, the recent work by Meta AI (yes, them again, promised, we're trying to balance our watchlist) on music is an exciting endeavor that presents new impressive results. The subject is not yet "concluded," but we already encourage you to listen to the various examples on the project page: https://ai.honu.io/papers/musicgen/.
What's happening?
Without delving too deeply into the technical details, the authors here approached the problem somewhat like the famous Latent Diffusion Models, by training a generative model not directly on the music, but on the music encoded via Meta's EnCodec project [https://github.com/facebookresearch/encodec]. This project allowed learning compression of information via a relatively standard encoder/decoder model.
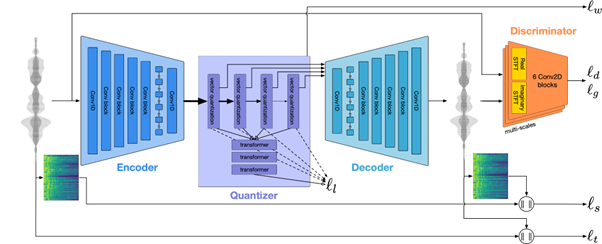
The new generative project relies on these high-level representations to learn how to generate new music. These thirty-second pieces can be generated from a textual prompt (which remains quite disappointing) or from a melody of another piece (where the condition seems to be applied much more effectively).
The important technical point here is how to model and generate the music.
Firstly, the modeling of music involves several parallel quantized vectors, rather than a single vector as often found in text or image. These complementary vectors are necessary to reproduce high-quality sound. However, this multiplication poses an optimization problem in usage. The authors here explore several approaches to generate these vectors at different levels while seeking to parallelize the calculations. A constraint is that these vectors are generated sequentially with a dependence on the history. Therefore, the authors propose a generic framework to handle this case of parallel tokens to be computed.
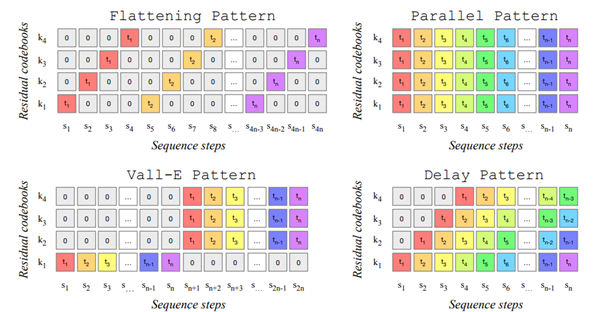
Second point of interest, the generative model here is not based on diffusion models! Against the current trend that started in June last year, the authors here use a good old autoregressive Transformer. If further research confirms that this approach is better suited for music generation, perhaps we will eventually observe how the type of generated data correlates with the Deep Learning architecture used.
Why it's interesting ?
Generative AIs are both an apocalypse and a revolution for the domains they affect. Following this tsunami is already interesting from a strictly social and economic perspective, and what we have been observing for the past few months in images (changes in economic paradigms and the emergence of new creative tools) will sooner or later occur in music. This work is clearly a new fundamental step towards the "Stable Diffusion moment of music".
However, it should be noted here that music often remains uniform, and the dependence on textual prompts is much less interesting here. The small size of the dataset (10K tracks in this case) likely plays a significant role.
Moreover, many industrial topics involve analyzing sound (for example, voice or system noise), or even more generally, a continuous signal over time. Any approach that makes progress in the field of music could potentially provide us with a new tool to address these topics.
White-box Transformers, a bit of intelligence in Deep Learning
[https://arxiv.org/abs/2306.01129]
This topic is mathematically much more complex and "low-level" than the topics we usually address in this blog, but it falls into a subject that we have been following closely for years, that of model interpretability and a better understanding of what happens when we train and use neural networks.
Let's first recall the foundation: Deep Learning remains largely empirical today, lacking a comprehensive mathematical theory that would justify and guide research. Model interpretability remains a complex academic subject where, although partial solutions exist, no approach can claim to fully address the issue.
Therefore, any serious work in this direction is particularly worth watching.
What's happening?
A strong theory in the world of Deep Learning is that of Representation Learning. Simplistically: a neural network, when trained to address a task, implicitly learns to compress the input information. This compression is not just a reduction of space, but preserves high-level information defining the input data.
This theory is a fundamental axis of work in Deep Learning. It is especially in this perspective that intermediate vectors in a neural network are referred to as latent vectors or embeddings. It is important because it seems to be regularly justified (by clustering, anomaly detection, style transfer, etc.) and provides us with a strong understanding of what an AI model learns.
Here, the authors propose to adapt the architecture of the Transformer and its training, focusing on the compression performed by the model. The central point is that this adaptation, the white-box Transformer, is mathematically interpretable for each layer of the network, opening the door to many exciting works to better analyze what happens in these networks. The model is trained using a compression objective and a sparsity (rarefaction) objective of information, and then adapted to classical classification tasks.
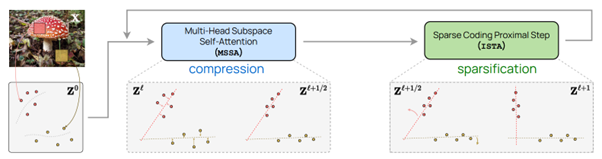
Why is this important?
This work will not immediately lead to new interpretability tools, but the fact that the operations of the layers can be mathematically interpreted opens the door to the emergence of new methods for interpretability and therefore the robustness of our AI models. Considering that these two points are currently two of the greatest challenges we may encounter, we cannot ignore this type of publication.
Written by Eric DEBEIR - Scientific Director of Datalchemy - eric@datalchemy.net
www.datalchemy.net