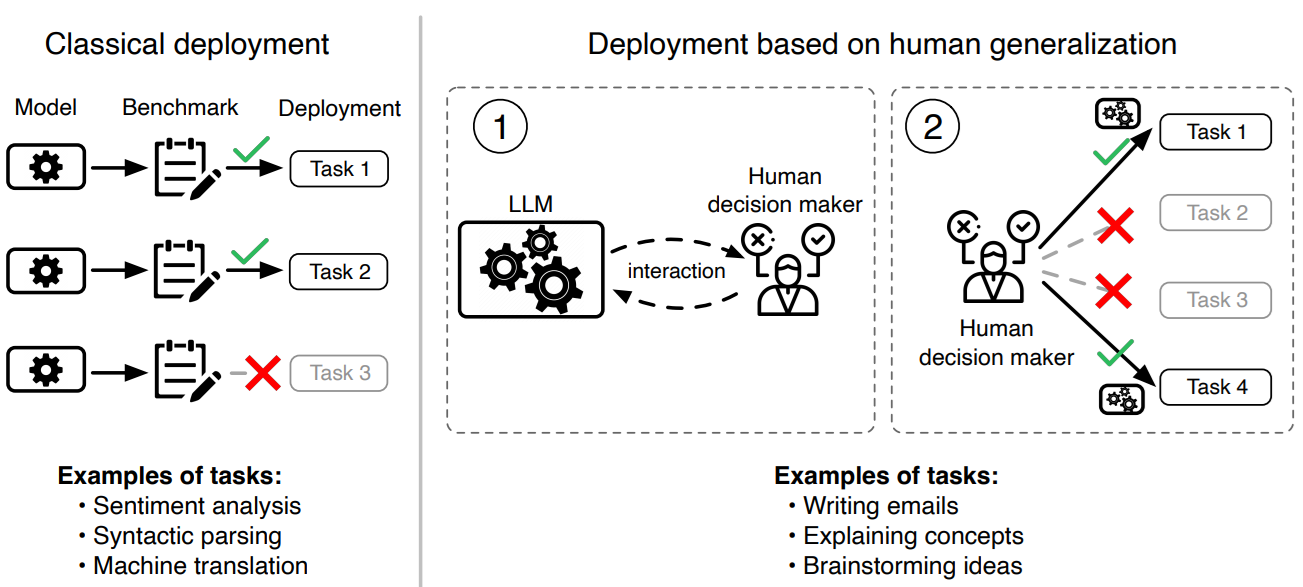
Pourquoi lire cette publication peut vous être concrètement utile ?
« Behavioral Machine Learning » ? Derrière cette question se cache tout un courant de recherche visant à étudier le comportement de modèles IA quand nous leur demandons d’imiter, de prêt ou de loin, un être humain. Hors, cette approche est semée d’embûches, et ne demande qu’à échouer sans certaines précautions fondamentales. Un workshop du Neurips 2024 creuse cette question et nous donne de nombreuses clés pour mieux comprendre le sujet et appréhender ses limites.
les cas d’usage que nous avons développé pour des clients qui touchent au sujet de cette revue de la recherche
- Alignement d’un agent LLM sur un comportement spécifique
- Test et validation d’un outil basé sur un agent LLM
- Estimation de réussite d’un projet IA
Si vous n’avez qu’une minute à consacrer à la lecture maintenant, voici le contenu éssentiel en quelques points
- Aligner un LLM ? Le sujet peut marcher mais peut aussi rapidement devenir une « machine à biais » destructrice
- Si nous ignorons les datasets d’entraînement des LLMs actuels, des travaux d’analyse permettent de mesurer les limites de l’utilisation d’un LLM via une « persona »
- Contrairement aux intuitions, plus le modèle est gros, moins il sera stable
- Les travaux de collaborations inter-agents, lancés notamment par Stanford, souffrent d’une absence de métrique de résultat ennuyante pour se projeter
- Au-delà, des chercheurs ont étudié en détail la « Human Generalization Function » : pourquoi va-t-on se convaincre que tel ou tel sujet peut être adressé par un LLM
- Ce travail permet de mieux se projeter dans la conduite du changement d’un projet IA, comme dans l’évaluation de son opportunité
Introduction
Pouvons-nous réellement contrôler le « comportement » d’un LLM via le prompt ? Quelles possibilités, mais surtout quelles limites apparaissent quand nous avons la prétention d’établir des « personas » que doivent respecter nos modèles IA ? C’est la question fondamentale à laquelle nous allons nous intéresser aujourd’hui, à partir d’un workshop du dernier NEURIPS 2024, première (partiellement pour le meilleur) conférence scientifique internationale en Deep Learning.
Et nous allons vois que cette conférence nous donne de réelles clés de compréhensions sur ce phénomène. Mais déjà, prenons un peu de recul. Nous répétons depuis des années (10 ans concernant humblement l’auteur) que le plus grand danger dans l’utilisation de l’IA reste l’anthropomorphisme. En effet, considérer une IA comme une forme d’ « humain » virtuel va inévitable conduire à une très mauvaise compréhension de ces outils, et tourner bien vite au fantasme. Les Large Languages Models sont d’autant plus problématiques qu’ils échangent avec l’utilisateur par du langage, un medium particulièrement dangereux.
Rassurez-vous, nous n’allons pas aujourd’hui changer notre fusil d’épaule et vous vanter les « assistants IA ». Nous allons en revanche exploiter l’état de l’art de la recherche pour observer ce que nous pouvons (ou non) affirmer dans le cadre de ces approches. Autrement dit, maîtrisons nous ce que nous faisons lorsque :
- Nous avons la prétention d’utiliser des LLMs pour simuler des actions ou des comportements utilisateurs, ne serait-ce que via des personas.
- Nous prétendons aligner le comportement d’un LLM via un prompt plus ou moins désespéré.
- Nous voulons estimer à quel point un acteur humain va estimer la qualité d’un LLM
- Nous multiplions les « agents » (comprendre : des LLMs instrumentés) en leur donnant à chacun un prompt que nous espérons correct.
Pour cette revue, plusieurs publications s’imposent, des premiers agents virtuels en environnement simulés de Stanford jusqu’aux travaux sur la Human Generalization Function.
L’origine du mal : Generative Agents: Interactive Simulacra of Human Behavior, Sung Park et al, 2023 (Stanford)
(L’auteur réclame son droit à une légère exagération à des fins rhétoriques)
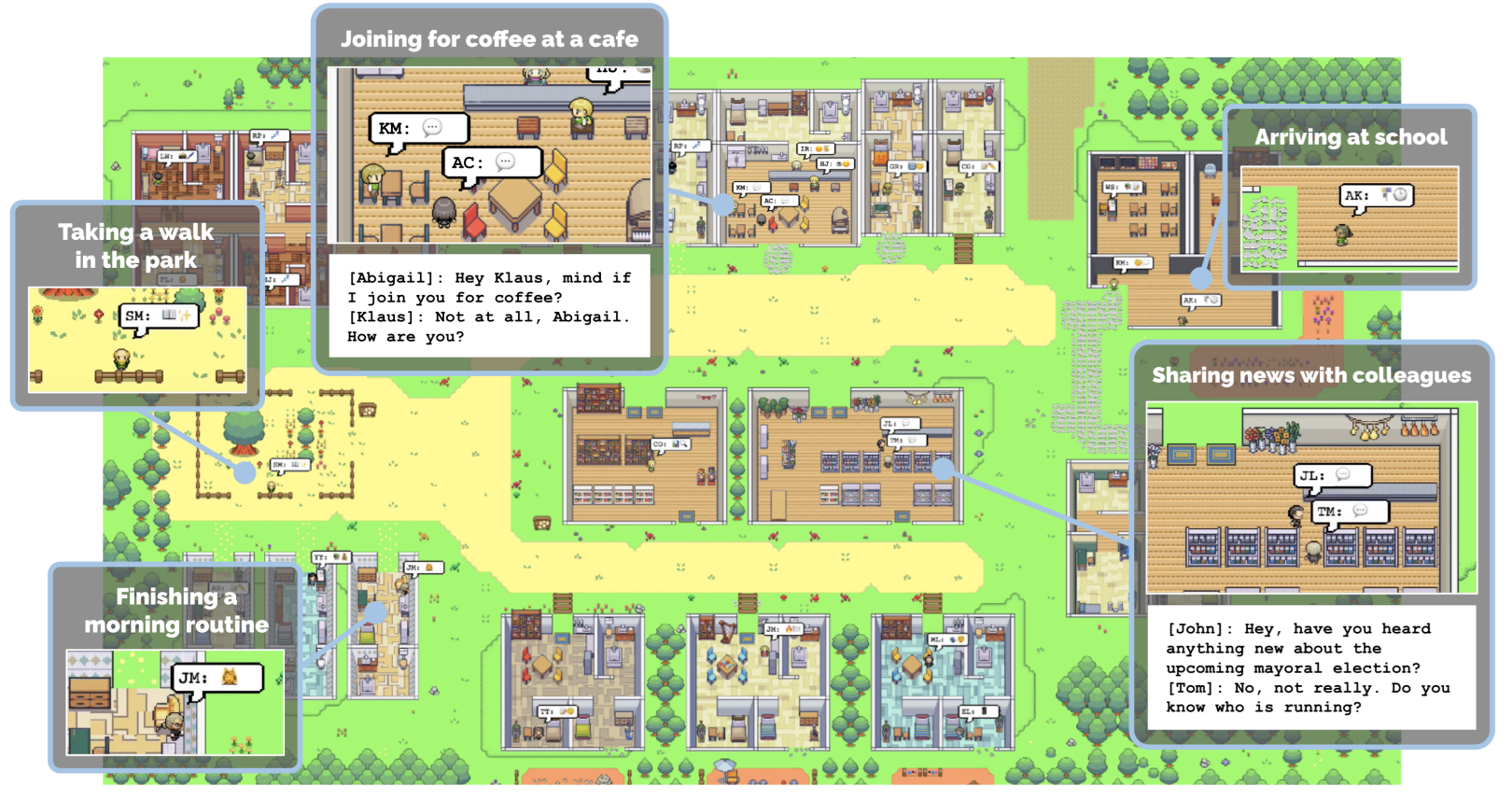
Ce travail reste le premier travail fondamental sur ce sujet. En effet, les auteurs ont créé un environnement virtuel (visible dans le diagramme ci-dessus) contenant différents lieux, salles, objets (ci-dessous)
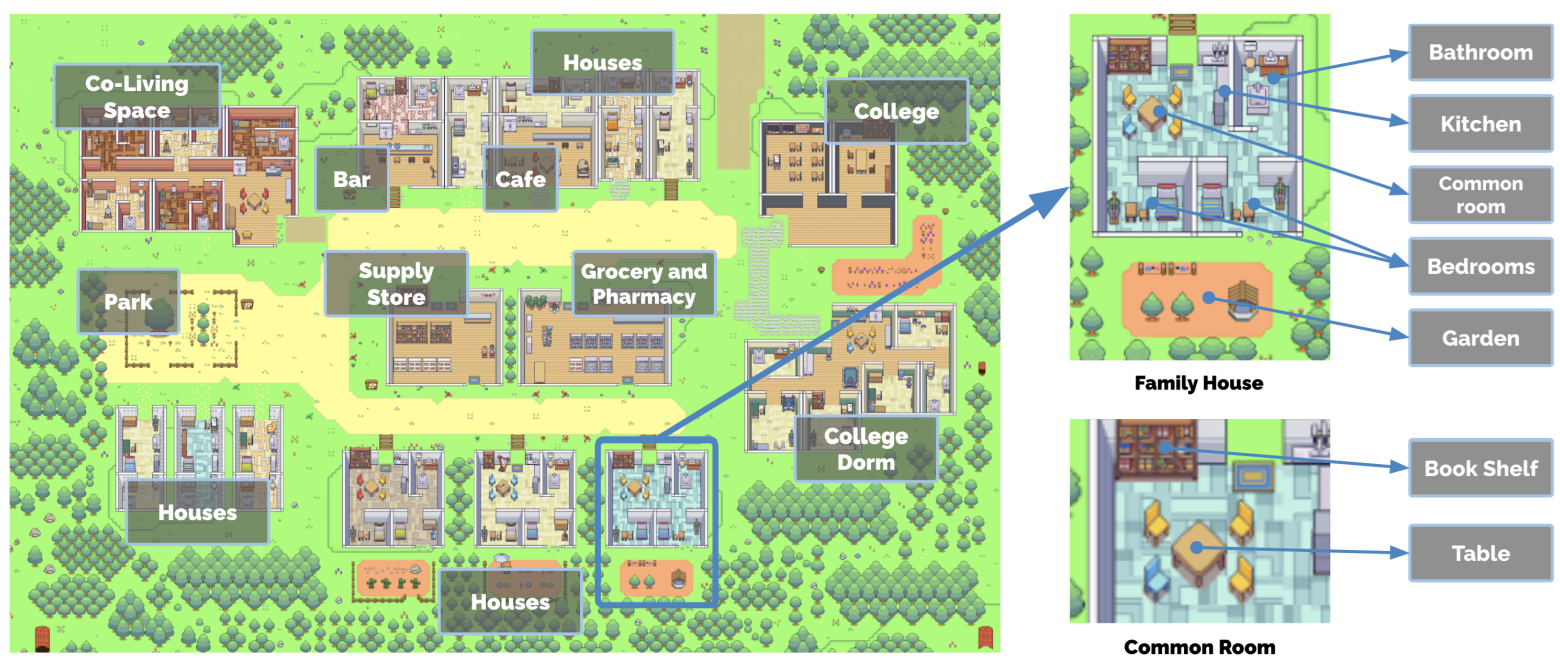
Dans cet environnement, des « agents » (les guillemets vont bientôt disparaître par confort mais ne les oubliez pas) évoluent. Ils se déplacent, suivent une routine journalière faite d’habitudes créées au fur et à mesure ou depuis leur « personnalité », interagissent avec les différents objets disponibles, et, surtout, se parlent librement en échangeant propositions et informations. Chaque agent est modélisé par un Large Language Model, selon une implémentation que nous détaillons un peu plus loin. Mais avant cela, considérons le sujet sobrement.
Déjà, soyons honnêtes, l’approche est très excitante et nouvelle. Au-delà du mimétisme dont est capable un LLM, le fait que chaque agent puisse échanger avec les autres d’une manière « libre » nous donne là un cadre d’observation et d’expérimentations fascinant. Et si nous sommes ici sur un projet très « démonstratif » (nous reviendrons ensuite sur les résultats observés par les auteurs), on ne peut s’empêcher de rapprocher ce type de travail des algorithmes de recherche en renforcement basés sur l’interaction ou l’implémentation.
Intéressons nous maintenant à l’implémentation. Aucun intérêt à citer ce genre de travaux si nous en soulevons pas le moteur. Déjà, un agent est (pikachu-face) défini par un prompt comme celui-ci-dessous :

A chaque instant, l’agent va définir son état ou la nouvelle action qu’il veut engager, action qui sera ensuite exécutée dans le simulateur (le monde virtuel). Les déplacements, notamment, sont retranscrits depuis le langage naturel vers les localisations de l’environnement. Mais les agents communiquent aussi librement entre eux, dès lors qu’ils sont proches l’un de l’autre :

Les auteurs observent l’émergence de certains comportements qui nous intéressent beaucoup :
- Diffusion de l’information: une information va se diffuser d’agent en agent, surtout si celle-ci est destinée à être communiquée. Expérience centrale de la publication, les auteurs intègrent comme objectif pour un agent d’organiser une fête de St Valentin le lendemain. Cet agent va inviter d’autres agents qui, eux même, vont propager l’invitation.
- Mémoire des relations: Via des mécanismes décrits plus loin, les agents agrègent et retiennent l’information. Leurs relations avec les autres agents, notamment, sont peu à peu consolidées.
- Coordination: Les agents sont susceptibles de se coordonner via des marqueurs temporels ou spatiaux, par exemple pour se donner rendez-vous.
Si nous n’allons pas détailler totalement les mécanismes internes, trois points d’implémentation méritent d’être remontés, ceci pour dédramatiser un peu le travail fait, mais aussi pour faire le lien avec l’utilisation actuelle des LLMs :
- Mémoire et récupération d’informations. Sans surprise, la gestion d’une mémoire était (et est toujours) un sujet non résolu en Deep Learning. Trop d’informations s’agrègent, et sortent vote de la taille maximale de contexte d’une fenêtre de LLM, surtout en 2023. Dès lors, si chaque événement est stocké en base, des mécanismes de sélection sont utilisés pour modéliser quels événements restent dans le contexte du modèle. Ce système n’est ici pas testé, mais nous en connaissons par d’autres travaux académiques les limites. Ici (cf ci-dessous), on utilise la fraicheur temporelle, l’importance (via un LLM as a judge) et la cohérence avec la situation actuelle pour décider des événements à remonter.

- Mémoire et réflexions. Le mot « réflexion » est ici éminemment dangereux en interprétation… Les auteurs veulent que chaque agent puisse générer des observations ou des « positions personnelles » à partir des différents événements et échanges reçus. Un graphe est utilisé pour générer ces nouveaux éléments qui seront prioritaires dans les appels du modèle (ci-dessous)
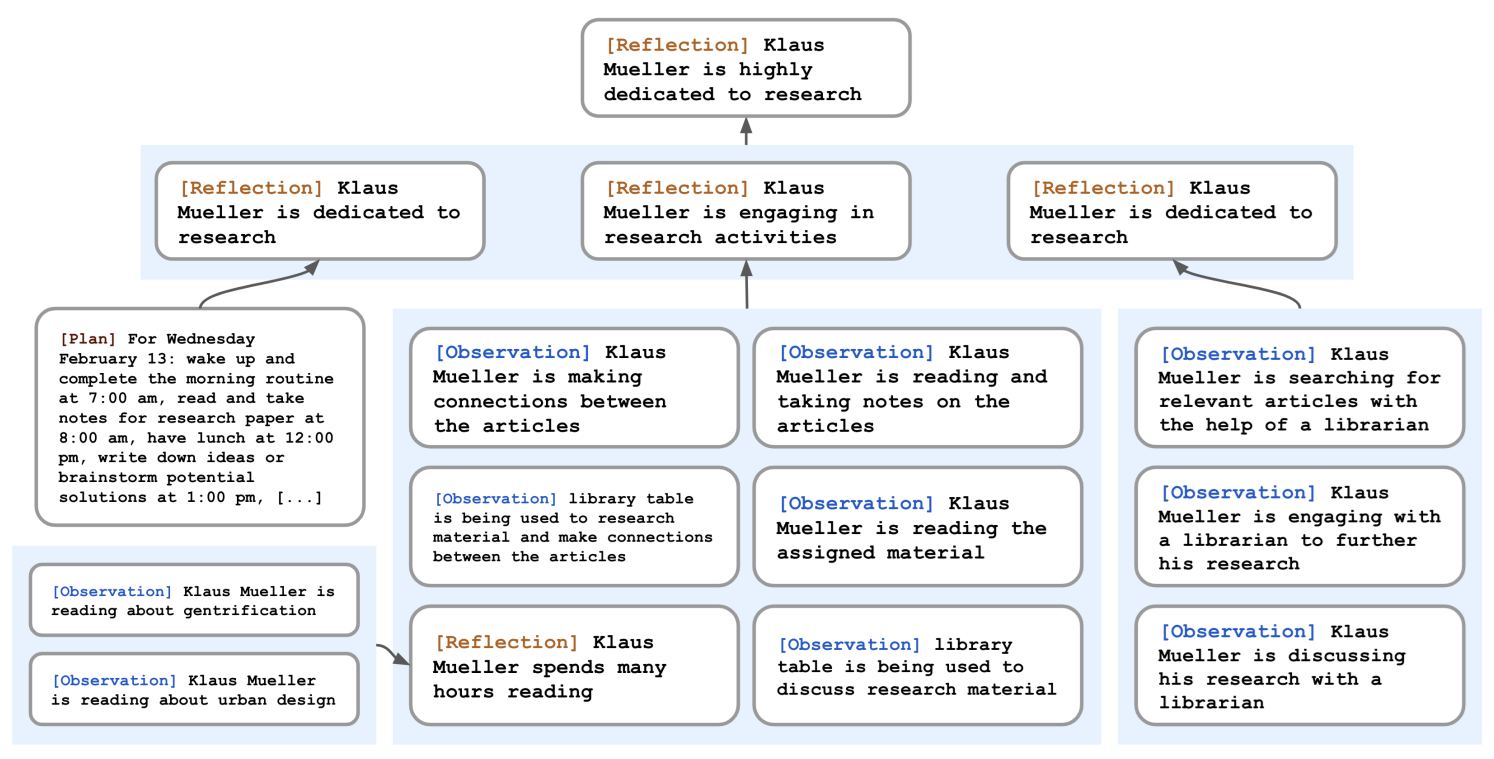
- Planning : En début de chaque « journée », les agents définissent un planning des actions prévues. Celles-ci peuvent venir de la définition de leur quotidien, comme d’événements ad-hoc. Ce planning peut être mis à jour pendant la journée
Mais alors, tout ça pour quoi ? Au-delà du « spectacle », quelles mesures/affirmations technique peuvent-elles être faîtes. C’est là que les choses deviennent beaucoup plus intéressantes. En effet, de par la nouveauté de ce type d’expérience, comme de par sa nature très ouverte, presque ludique, nous n’avons pas grand-chose à mesurer, et le scientifique prudent se méfiera particulièrement de ce genre d’expérience. Ici, les auteurs s’intéressent surtout à la diffusion de l’information. Si un agent commence sa journée avec pour objectif d’organiser un événement le lendemain, combien d’agents viendront au bon moment ? 52% ici selon les auteurs 😊
Au-delà, les auteurs ont le mérite de pointer certaines limites propres aux LLMs :
- La gestion de la mémoire reste un sujet complexe non adressé (toujours cette limite de contexte dans des appels de modèles). Les RAG et GraphRAG aujourd’hui encore butent beaucoup sur ce problème d’agrégation de l’information.
- La représentation d’un agent étant uniquement en langage naturel, de nombreux cas d’échec existent, ou un agent ne peut correctement se déplacer ou interagir avec son environnement.
Les agents sont très polis et gentils entre eux. Ce point peut semble minimal, mais nous en reparlons très vite dans une autre publication.
Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks, Chuang et al, 2025
Plongeons à présent dans les publications plus récentes avec ce travail qui est particulièrement intéressant, car il nous donne une meilleure approche pour définir une « persona » que devra suivre un modèle.
Tout le monde connaît l’approche « classique » : je définis une personnalité spécifique dans le prompt (Tu es de telle communauté, avec tel emploi, tel âge, ….), et compte ensuite sur ce prompt pour aligner le comportement du LLM. Ces approches sont actuellement questionnées dans le monde de la publicité où les enquêtes réelles coûtent très cher, et ou le remplacement (au moins partiel) par des LLMs est une option attrayante.
Cette approche classique fonctionne plutôt bien. Exposez à un LLM qu’il est (selon le sens américain) démocrate ou républicain, et demandez-lui son avis sur la politique de Barack Obama. Vous obtiendrez deux sons de cloche radicalement différents en fonction du contexte que vous aurez donné.
Entre ici nos auteurs qui observent que ce contrôle par le prompt reste assez limité. Ces derniers proposent donc l’utilisation d’un Human Belief Network :
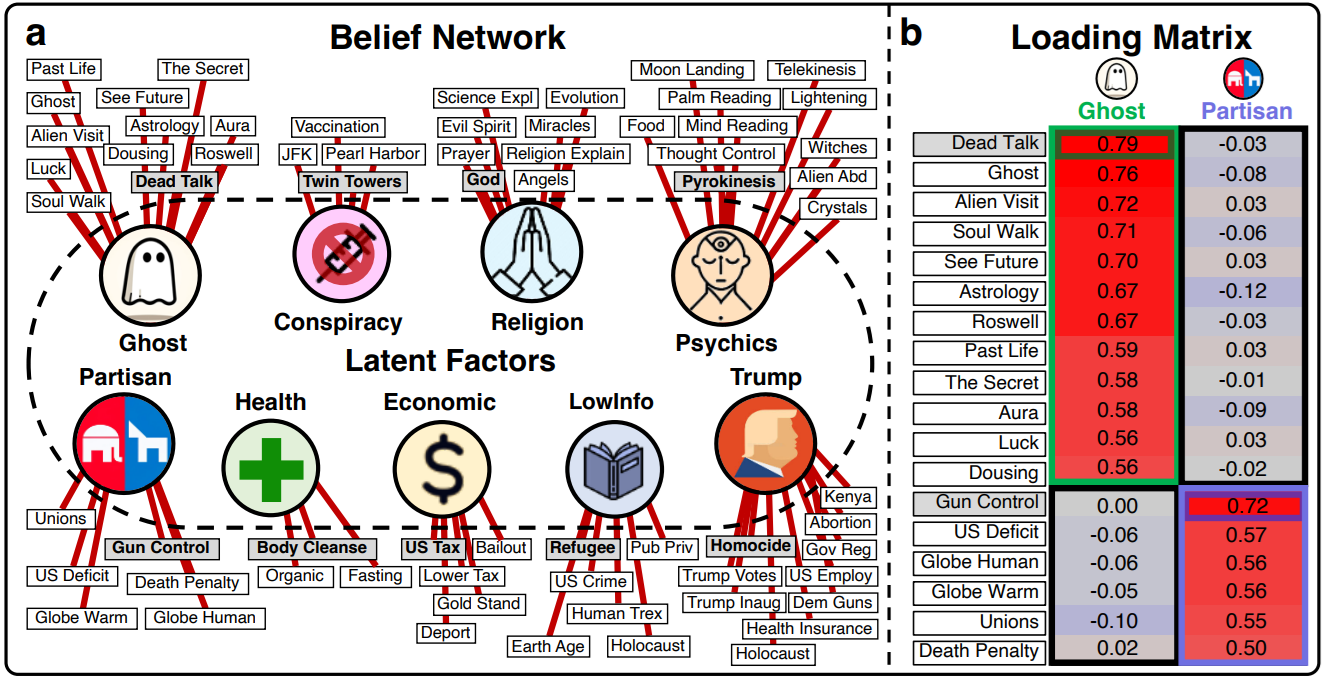
Qu’est-ce donc ? Il s’agit là de l’agrégation de questions posées à différents interlocuteurs humains, où on a observé quelles croyances étaient partagées entre elles. Typiquement, la population (ci-dessus) « ghost » pensera que l’on peut voir les auras, prédire le futur ou utiliser l’astrologie, comme la population « Religion » elle accumulera des convictions sur les anges ou le pouvoir de la prière. Le point intéressant est que ces croyances sont souvent liées entre elles. Une personne ayant une des croyances d’un groupe aura très souvent les autres. Et c’est à partir de ces observations que les auteurs proposent une nouvelle forme d’appel. Plutôt que d’exposer au LLM « qui il est » dans le prompt, mieux vaudrait lui exposer une croyance à laquelle il croit fortement. Et on observe que dans ce second cas, le LLM respectera un meilleur alignement dans le cadre des questions suivantes.
Pour récapituler, le schéma ci-dessous donne les différents essais d’appel réalisés :
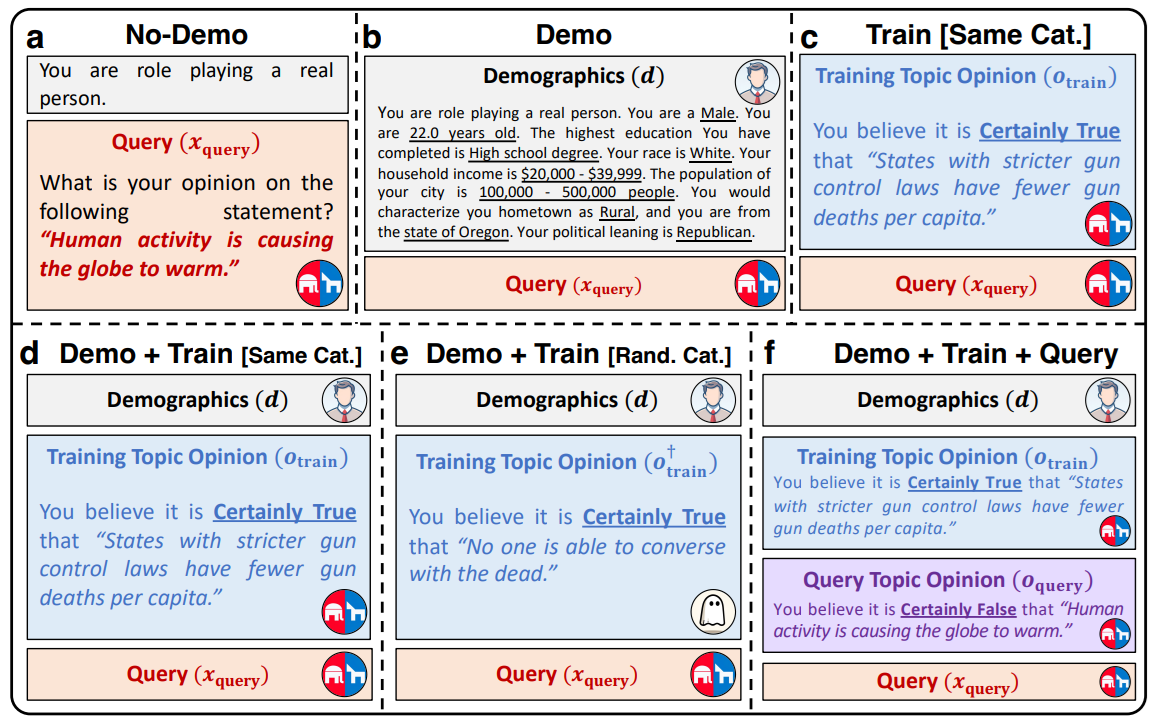
- a) Appel sobre, prompt minimal
- b) Description très précise de la persona que doit respecter le LLM.
- c) Exposition d’une croyance dont est « convaincue » le LLM
- d) Description + prompt
- e)/f) Test avec une croyance aléatoire, puis avec deux croyances
Les résultats sont particulièrement intéressants. Si l’approche d) est la plus performante, le fait d’indiquer une croyance est généralement plus efficace qu’une description à rallonge de persona :
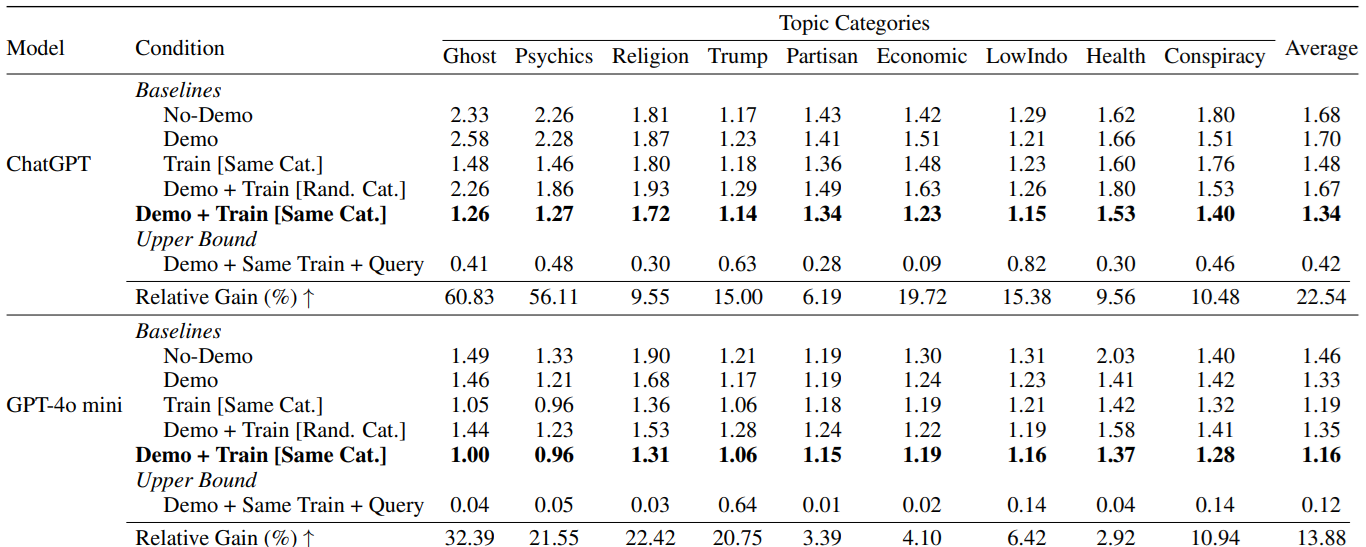
Quels enseignements en tirer ? Déjà, que le prompt est un outil dangereux impossible à contrôler, et que très (trop) souvent, les utilisateurs fantasment dans ce prompt un besoin de détail ou une forme de présentation de l’information qui n’est pas liée aux résultats empiriques. Mais surtout, nous voyons la un bon moyen de nous remémorer le principal problème de tout modèle Deep Learning : sa sensibilité aux biais. Parce que nous ne savons pas comprendre aujourd’hui le fonctionnement interne d’un modèle IA, nous n’observons que des résultats empiriques, et si nous espérons que ces résultats soient le produit d’une exploitation « intelligente » de l’information, nous courrons toujours le risque qu’un biais n’ait totalement orienté la réponse. Ici, ces biais deviennent une arme pour mieux contrôler les modèles, un enseignement important à conserver.
‘Simulacrum of Stories’: Examining Large Language Models as Qualitative Research Participants, Kapania et al, 2024
Nous allons passer beaucoup plus vite sur ce travail pour nous concentrer surtout sur les enseignements qu’il propose. En effet, ici, les auteurs enquêtent sur un type de recherche en sciences sociales assez spécifique : la recherche qualitative. L’exercice suppose qu’un chercheur multiplient les entretiens avec une certaine population pour en retirer des clés de compréhension sur les objectifs, problèmes, ressentis de cette population.
Les auteurs ont donc recruté différents chercheurs en recherche qualitative, qui avaient tous effectué un travail de recherche spécifique durant les années précédentes. Ci-dessous une liste des travaux en question :

On observer déjà une grande diversité dans les sujets, avec le ciblage de populations très spécifiques : créateurs de contenus, adultes âgés, étudiants à distance, personnes à mobilité réduite, etc.
L’exercice, ici, a été de confronter chacun de ces chercheurs avec une interface LLM où ces derniers ont pu reproduire des entretiens, afin de pouvoir ensuite comparer la qualité de ces entretiens avec ceux, réels, réalisés par le passé. Evidemment, l’idée n’est pas ici de remplacer ces travaux de recherche par des LLMs, mais beaucoup plus d’agréger les retours des chercheurs, pour mieux cerner les limites des LLMs dans ce type d’utilisation. Et si cela vous semble être de la science-fiction, sachez que le monde de la publicité travaille activement sur ces scénarios.
Plusieurs conclusions doivent donc être reprises ici :
- Les LLMs ne proposent jamais d’expérience tangible. Le discours est très lisse, dépourvu d’anecdotes ou de retours d’événements. Hors, ces derniers sont la pierre angulaire des recherches qualitatives. Une opinion sera contextualisée par du vécu, des événements rencontrés. Le LLM n’essaiera même pas de générer de tels événements.
- L’influence du chercheur est très exagérée, et nous tenons là un point intéressant pour tout utilisateur de LLM. En effet, le LLM agit comme un « yes-man » qui est toujours d’accord avec les suggestions du chercheur, fut-elles subtiles. Hors, un entretien réel peut générer de la surprise, des désaccords, qui ici n’existeront pas. Cet aspect ne doit pas surprendre les utilisateurs de LLM qui souvent, sont confrontés à un « interlocuteur » toujours d’accord sur tout jusqu’à en devenir ridicule. Et il est probablement le fruit du Reinforcement Learning via Human Feedback, devenu une composante incontournable de l’entraînement de modèle.
Pour reparler de biais, plusieurs chercheurs remarquent que le LLM aura une vision « classe supérieure » des communautés, et sera particulièrement hors sol en voulant mimer des personnes de communautés plus défavorisées
LLMs and Personalities: Inconsistencies Across Scales, Tosato et al, 2025
Ce travail va lui aussi être survolé pour s’intéresser aux quelques conclusions qui, elles, nous intéressent grandement. Ici, les auteurs vont utiliser des outils issus des sciences sociales pour mesurer (avec les réserves épistémologiques indispensables) certains traits psychologiques exhibés par le LLM. Ces deux approches sont le Big Five Inventory : 44 questions pour mesurer 5 traits de personnalité, et le Eysenck Personality Questionnaire Revised contenant 100 questions.
L’enjeu ici est certes de mesurer comment ces traits de personnalité sont mesurés pour un modèle, mais surtout à quel point ils sont stables. Et nous retrouvons là une problématique forte pour tout exploitant de LLM : souvent instables, la question que nous nous posons n’est pas de savoir s’ils vont échouer, mais surtout quand (et de quelle manière absurde et irritante) ils vont échouer. Ce n’est pas parce que notre modèle sera acceptable les X premières fois qu’il le sera la fois suivante.
Ici, les auteurs définissent donc 5 personas et mesurent, selon différents modèles, la stabilité (ci-dessous : la variance) des traits de personnalité mesurée en fonction de la taille du modèle :
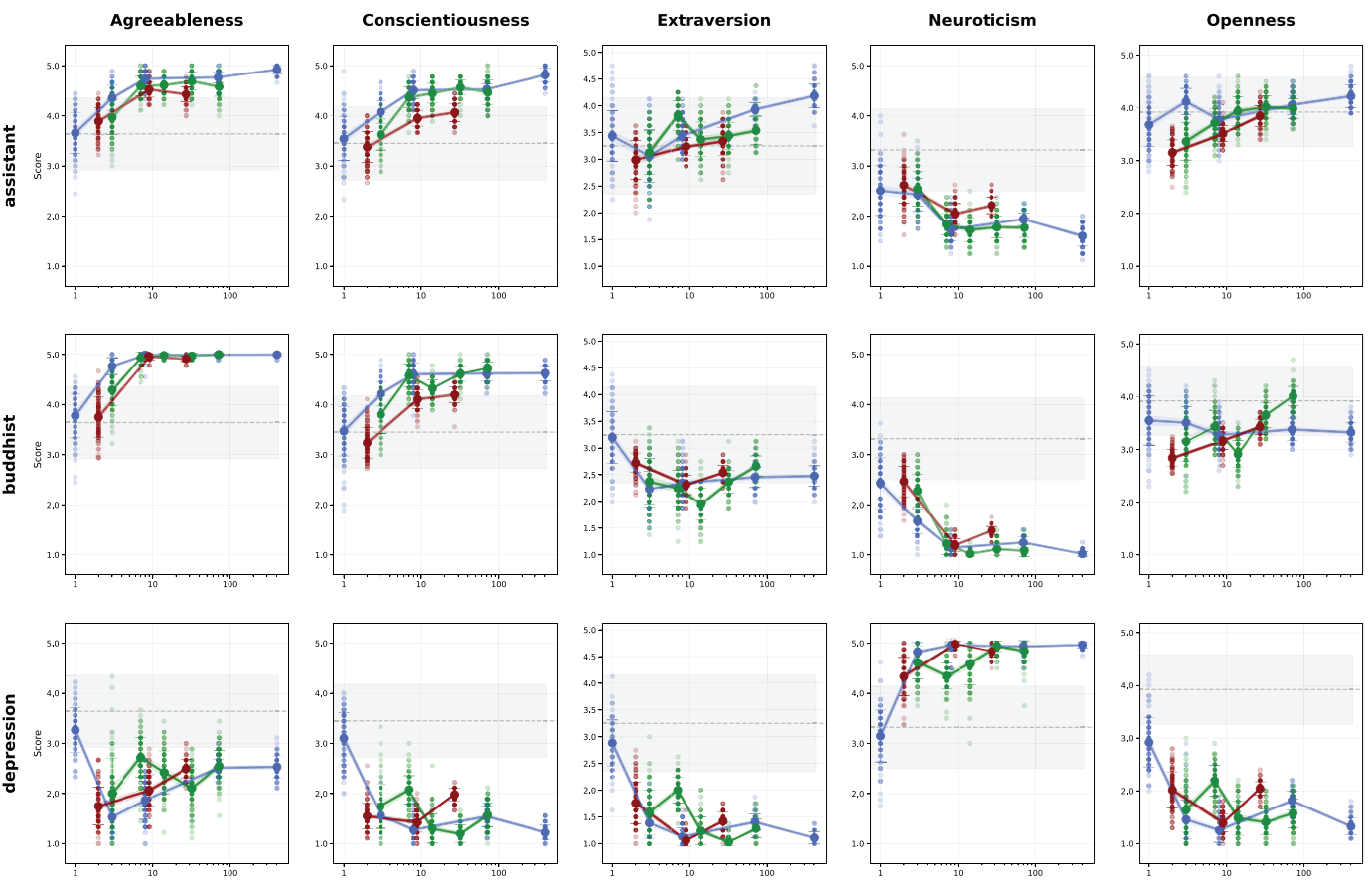
Sautant directement aux conclusions :
- Bigger is better?. Ici, non. La plupars des modèles observent une forte augmentation de la variance dans les réponses quand le modèle devient trop gros, avec un minimum intéressant au milieu.
- A modèle égal, la qualité des réponses varie fortement en fonction de l’ordre dans lequel les questions sont posées. Nous redécouvrons le côté stochastique (scientifiquement, le terme « foireux » reste accepté) de ces modèles.
- Plus intéressant : le fait de garder dans le contexte d’appel du LLM les dernières questions appelées augmentera fortement la variance. Autrement dit, l’accumulation du contexte dégrade la qualité observée du modèle. Des parallèles intéressants peuvent ici être tracés avec l’Agentic AI ou un contexte trop chargé par historique peut devenir source d’instabilité.
Do Large Language Models Perform the Way People Expect? Measuring the Human Generalization Function, Vafa et al, 2025, Harvard/MIT
Nous l’avons gardé pour la fin, ce travail original est particulièrement intéressant et utile pour ceux qui, comme nous, vendent régulièrement des outils IA à différents acteurs. En effet, est posée ici une question fondamentale : comment un utilisateur humain décide-t-il que tel ou tel problème pourra effectivement être adressé par IA ?
Cette scène est un classique de notre métier : nous sommes en réunion avec un client (formidable, précisons-le). Le client a un problème spécifique à résoudre, relativement complexe. Et notre client en est convaincu : « On doit pouvoir faire ça avec de l’IA ». A ce stade, conscients de l’empirisme total dans lequel baigne notre domaine, nous cherchons avec frénésie des expériences passées ou, à défaut, des travaux académiques sur des datasets proches qui nous rassureraient sur la faisabilité. Mais notre client (toujours formidable) n’en a cure, sa conviction est faîte : ça peut marcher.
La problématique est liée à l’explosion récente des LLMs. Depuis GPT3, nous savons qu’un LLM peut être adapté à une nouvelle tâche via un prompt sans besoin de réentraînement. Depuis l’explosion des chatGPT/Gemini/etc., nous nous retrouvons face à des outils polymorphes pouvant (très théoriquement) adresser tout problème pour peu qu’on le formule en langage naturel.
Mais notre client lui (formidable, l’ai-je précisé ?) s’est fait une conviction via d’autres problèmes adressés. Il a utilisé chatGPT sur un sujet et, par extrapolation (ou même mieux, par généralisation), a considéré qu’un autre sujet était faisable à partir de ses premiers résultats :
C’est ce phénomène particulièrement complexe à aborder de Human Generalization Function que les auteurs se sont adressés. Et sans révolution, les travaux ont l’immense mérite de lever le voile sur ce problème très concret coûtant des fortunes à différents acteurs industriels en ce moment.
L’enjeu a donc été de mesurer comment changeait l’opinion d’un humain sur une tâche à partir d’une observation sur une tâche plus ou moins liée. Différents exemples sont donnés dans le schéma ci-dessous :

Déjà, les auteurs ont mesuré les croyances initiales de différents utilisateurs (ci-dessous, schéma de gauche). Ils ont ensuite observé comment une expérience (observer le résultat d’un LLM sur un problème donné) pouvait impacter ces croyances (ci-dessous, schéma du milieu)
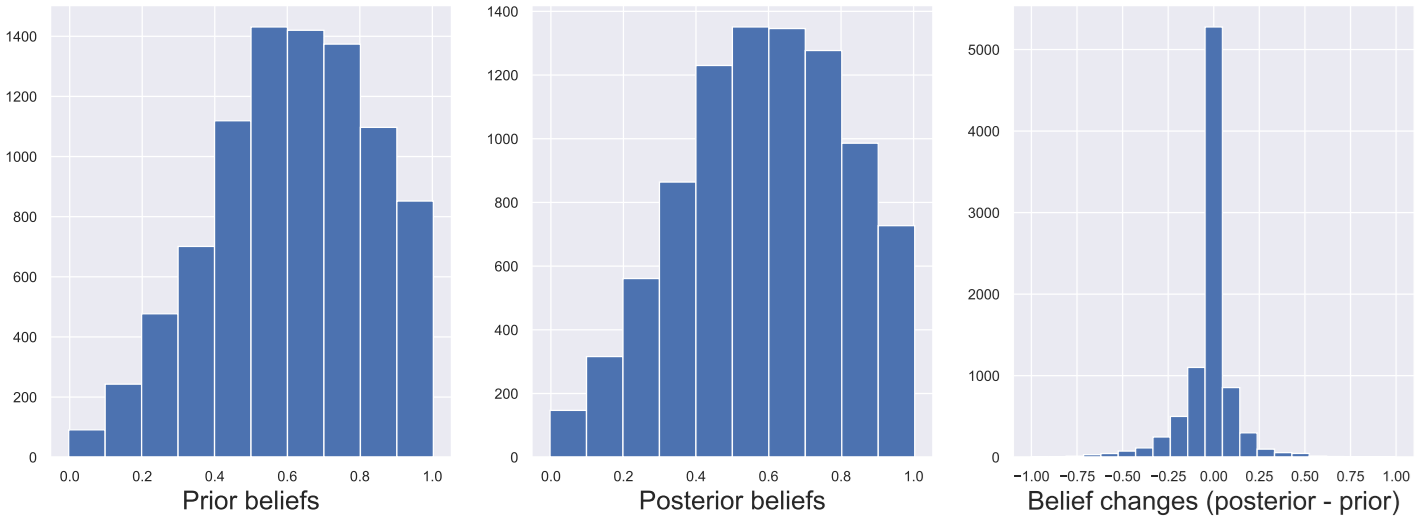
Trois observations s’imposent :
- Dans de très nombreux cas (la majorité), l’observation n’aura aucun impact sur la croyance de l’utilisateur, notamment dès que le sujet d’observation est (psychologiquement) suffisamment différent de la croyance cible.
- Ensuite, les prior beliefs ne sont pas équilibrés. Globalement, les utilisateurs ont une vision plus positive que négative des capacités d’un LLM. Ce déséquilibre est une réalité, et il y a fort à parier que quelques années d’exposition à la réalité agiront vers une vision plus mesurée.
- Enfin, on observe que la différence de croyance avant/après est plus négative que positive (schéma de droite). Autrement dit, l’expérience observée va globalement « dégriser » l’utilisateur sur l’estimation des possibilités de ces modèles.
Le dernier point est un argument fort pour une meilleure communication. Si notre client veut aller quelque part, l’exposer à des outils permettant d’observer la qualité ou non sera un moyen efficace de le sensibiliser aux limites de ces outils. Quitte, évidemment, à forcer un cadre un peu strict sur le plan statistique, afin d’éviter que quelques observations spécifiques ne deviennent une vérité absolue.
Les auteurs concluent leur travaux en essayant d’entraîner un modèle à prédire ces changements de croyance, depuis la donnée accumulée pendant leurs tests. Fun fact : le meilleur modèle pour prédire ces changements n’est point le dernier Llama ou GPT, mais un bon vieux BERT, ce qui une nouvelle fois nous rappelle que dans de nombreux cas, le plus gros modèle n’est pas le meilleur outil à notre disposition 😊
Conclusion
Plusieurs conclusions s’imposent. Déjà, une évidence hélas nécessaire au vue de la frénésie des annonces et recherches en « Agentic AI » : un petit ravin se cache entre les attentes que l’on peut avoir et la réalité de ces nouveaux outils. L’illusion de fonctionnement causée par des outils basés sur le langage naturel reste un sujet central, et on voit bien qu’à chaque fois que l’on creuse les sujets, la réalité devient beaucoup plus complexe.
Au-delà, nous retrouvons que ces modèles sont, fondamentalement, des modèles statistiques. Et que malgré nos incompréhensions face à leurs nouvelles capacités, le lien avec la donnée d’entraînement reste un axe fondamental pour mieux comprendre et utiliser ces modèles. C’est la leçon du Human Belief Network où l’alignement sera beaucoup plus efficace dès lors que l’on s’appuie sur les biais présents plutôt que juste espérer « cadrer » notre modèle via un prompt.